

Feed aggregator
SQL Server 2025 – Retirement of SQL Server Reporting Services (SSRS)
Microsoft has announced the end of the SQL Server Reporting Services (SSRS) service. In other words, Microsoft will no longer provide new versions of SSRS. Currently, the latest available version is the 2022 version (https://www.microsoft.com/fr-FR/download/details.aspx?id=104502).
However, it is important to note that this service will be supported until January 11, 2033. Moreover, it will still be possible to use SSRS and host databases from this service on a recent version of SQL Server.
The replacement for SQL Server Reporting Services (SSRS) is Power BI Report Server (PBIRS). This is the service to adopt for future installations. In fact, we have observed that many clients have been using Power BI Report Server for several years.
I use SQL Server Reporting Services and would like to migrate to Power BI Report Server. What are my options?
Several solutions are possible (the following list is neither exhaustive nor in any particular order):
- Migrate the databases that support the SSRS service to PBIRS
- Current environment:
- Server 1 (S1):
- Hosted services: SSRS and SQL Server Database Engine. The SSRS service and my databases are hosted on my S1 server.
- Server 1 (S1):
- New environment:
- Server 2 (S2):
- Hosted services: PBIRS and SQL Server Database Engine. The PBIRS service and the database engine are hosted on my S2 server.
- We will migrate the databases from S1 to S2.
- The PBIRS service will connect to the migrated databases.
- Server 2 (S2):
- Current environment:
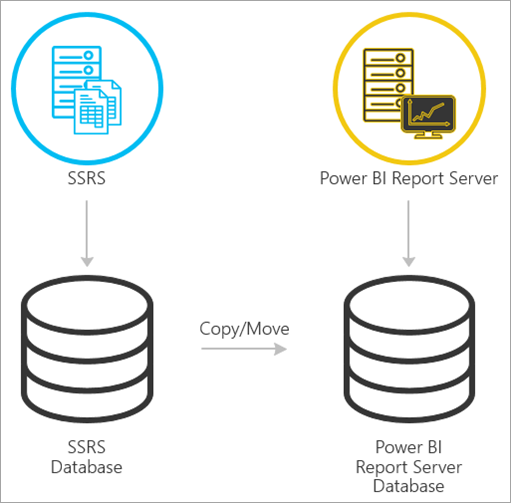
Reference: https://learn.microsoft.com/en-us/power-bi/report-server/migrate-report-server
- Use the RDL Migration Tool (RdlMigration) to migrate reports from SSRS to PBIRS
Reference: https://github.com/microsoft/RdlMigration
- Use the Reporting Services PowerShell API, which allows for fine-grained control over the migration of reports
Reference: https://github.com/microsoft/ReportingServicesTools
I am currently using SSRS 2022 and would like to migrate to Power BI Report Server. What are my options?
According to the documentation (as of now), it is currently not possible to migrate from SSRS 2022 to Power BI Report Server.

Reference: https://learn.microsoft.com/en-us/power-bi/report-server/migrate-report-server
Thank you, Amine Haloui.
L’article SQL Server 2025 – Retirement of SQL Server Reporting Services (SSRS) est apparu en premier sur dbi Blog.
Experiencing SQLBits 2025 in London
This week, I’m in London attending the SQLBits 2025 conference.
Since joining dbi services as a consultant, this is my second time taking part in the event.
The last time was in 2022, but I attended remotely due to the uncertainties surrounding international travel at the time, as COVID-19 was still a concern.
You can actually find the blog post I wrote back then: SQLBits 2022 – Levelling up my Performance Tuning skills.
This year, I’m here in person and fully intend to make the most of the experience.

For context, SQLBits 2025 is one of the largest Microsoft data platform events in Europe. Taking place in London from June 18 to 21, it features dozens of sessions covering SQL Server, Azure, Power BI, AI, and data engineering. The event brings together experts, MVPs, and Microsoft product team members for intense learning and networking. Known for its high-quality content and friendly atmosphere, SQLBits is a must-attend event for anyone working in the Microsoft data ecosystem.

As you can see on my badge, I’ve chosen to attend a wide range of sessions during the first two days, and on Friday I’ll be taking part in a full-day training on “Real-World Data Engineering: Practical Skills for Microsoft Fabric” led by Prathy Kamasani.
On the agenda, agenda, you’ll see that the trending topics stand out. Personally, I’m very interested in sessions on SQL Server 2025, which has just been released in public beta, or sessions on the SQL Server engine in general, but of course these aren’t the majority of sessions.
The trends are now:
- AI and AI Agents, with multiple sessions exploring how AI is being integrated into the Microsoft data ecosystem including intelligent assistants, automation, and real-world use cases.
- Microsoft Fabric is front and center, everywhere.
- Analytics and Power BI continue to be key pillars, with advanced sessions on DAX, large-scale reporting, data modeling, and real-time analytics.
- Data Transformation and DataOps are well represented, especially through practical sessions on orchestration, data pipelines, automation, and governance.
Today I attended the following sessions:
- How Microsoft’s new, open-source Data API builder fits into Solution Architecture

- Unlocking the Power of Open Mirroring in Microsoft Fabric
- AI Agents in Action: Enhancing Applications with Azure AI Services
- Azure SQL Managed Instance Demo Party
- Empower Your Data with Real-Time Intelligence leveraging Data Activator within Fabric
- From B-Trees to V-Order. Told differently than usual
- Resolving Deadlocks in SQL Server: Practical Demo
It’s a huge amount of information, subjects to explore and ideas for solving real-life problems for our customers.
That was only the first day, but I’m already extremely satisfied with the conference: from the quality of the sessions and the content to the expertise of the speakers. I’m looking forward to making the most of the upcoming sessions, and I highly recommend that any Microsoft Data professional consider attending SQLBits. If not this year, then why not next year?
L’article Experiencing SQLBits 2025 in London est apparu en premier sur dbi Blog.
Creating hierarchy using a parent child table
plsql gateway procedure on Oracle Autonomous Database
Inability to Export/Import our APEX APP
Parallel execution of Ansible roles
You can run a playbook for specific host(s), a group of hosts, or “all” (all hosts of the inventory).
Ansible will then run the tasks in parallel on the specified hosts. To avoid an overload, the parallelism – called “forks” – is limited to 5 per default.
A task with a loop (e.g. with_items:) will be executed serially per default. To run it in parallel, you can use the “async” mode.
But unfortunately, this async mode will not work to include roles or other playbooks in the loop. In this blog post we will see a workaround to run roles in parallel (on the same host).
Parallelization over the ansible hostsIn this example, we have 3 hosts (dbhost1, dbhost2, dbhost3) in the dbservers group
(use ansible-inventory --graph to see all your groups) and we run the following sleep1.yml playbook
- name: PLAY1
hosts: [dbservers]
gather_facts: no
tasks:
- ansible.builtin.wait_for: timeout=10The tasks of the playbook will run in parallel on all hosts of the dbservers group, but not more at the same time as specified with the “forks” parameter. (specified in ansible.cfg, shell-variable ANSIBLE_FORKS, commandline parameter –forks)
https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_strategies.html
$ time ansible-playbook sleep1.yml --forks 2
...
ok: [dbhost1] #appears after 10sec
ok: [dbhost2] #appears after 10sec
ok: [dbhost3] #appears after 20sec
...
real 0m22.384s
With forks=2 the results of dbhost1 and dbhost2 will both be returned after 10 seconds (sleep 10 in parallel). dbhost3 has to wait until one of the running tasks is completed. So the playbook will complete after approx. 20 seconds. If forks is 1, then it takes 30s, if forks is 3, it takes 10s (plus overhead).
Parallelization of loopsPer default, a loop is not run in parallel
- name: PLAY2A
hosts: localhost
tasks:
- set_fact:
sleepsec: [ 1, 2, 3, 4, 5, 6, 7 ]
- name: nonparallel loop
ansible.builtin.wait_for: "timeout={{item}} "
with_items: "{{sleepsec}}"
register: loop_result
This sequential run will take at least 28 seconds.
To run the same loop in parallel, use “async”
https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_async.html
- name: PLAY2B
hosts: localhost
gather_facts: no
tasks:
- name: parallel loop
ansible.builtin.wait_for: "timeout={{item}}"
with_items: "{{sleepsec}}"
register: loop_result
async: 600 # Maximum runtime in seconds. Adjust as needed.
poll: 0 # Fire and continue (never poll here)
# in the meantime, you can run other tasks
- name: Wait for parallel loop to finish (poll)
async_status:
jid: "{{ item.ansible_job_id }}"
register: loop_check
until: loop_check.finished
delay: 1 # Check every 1 seconds
retries: 600 # Retry up to 600 times.
# delay*retries should be "async:" above
with_items: "{{ loop_result.results }}"
In the first task we start all sleeps in parallel. It will timeout after 600 seconds. We will not wait for the result (poll: 0). A later task polls the background processes until all parallel loops are finished. This execution only takes a little bit more than 7 seconds (the longest sleep plus some overhead). Between the loop and the poll you can add other tasks to use the waiting time for something more productive. Or if you know your loop takes at least 1 minute, then you can add to reduce the overhead of the polling loop, an ansible.builtin.wait_for: "timeout=60".
For example, we have an existing role to create and configure a new useraccount with many, sometimes longer running steps, e.g. add to LDAP, create NFS share, create a certificate, send a welcome-mail, ….; most of these tasks are not bound to a specific host, and will run on “localhost” calling a REST-API.
The following code example is a dummy role for copy/paste to see how it works with parallel execution.
# roles/create_user/tasks/main.yml
- debug: var=user
- ansible.builtin.wait_for: timeout=10Now we have to create many useraccounts and would like to do that in parallel. We use the code above and adapt it:
- name: PLAY3A
hosts: localhost
gather_facts: no
tasks:
- set_fact:
users: [ 'Dave', 'Eva', 'Hans' ]
- name: parallel user creation
ansible.builtin.include_role: name=create_user
with_items: "{{users}}"
loop_control:
loop_var: user
register: loop_result
async: 600
poll: 0But unfortunately, Ansible will not accept include_role: ERROR! 'poll' is not a valid attribute for a IncludeRole
The only solution is to rewrite the role and to run every task with the async mode.
But is there no better solution to re-use existing roles? Let’s see…
Parallel execution of roles in a loopAs we already know
- Ansible can run playbooks/tasks in parallel over different hosts (hosts parameter of the play).
- Ansible can run tasks with a loop in parallel with the async option, but
- Ansible can NOT run tasks with a loop in parallel for include_role or include_tasks
So, the trick will be to run the roles on “different” hosts. There is a special behavior of localhost. Well-known is the localhost IP 127.0.0.1; But also 127.0.0.2 to 127.255.255.254 refer to localhost (check it with ‘ping’). For our create-user script: we will run it on “different” localhosts in parallel. For that, we create a host-group at runtime with localhost addresses. The number of these localhost IP’s is equal to the number of users to create.
users[0] is Dave. It will be created on 127.0.0.1
users[1] is Eva. It will be created on 127.0.0.2
users[2] is Hans. It will be created on 127.0.0.3
…
- name: create dynamic localhosts group
hosts: localhost
gather_facts: no
vars:
users: [ 'Dave', 'Eva', 'Hans' ]
tasks:
# Create a group of localhost IP's;
# Ansible will treat it as "different" hosts.
# To know, which locahost-IP should create which user:
# The last 2 numbers of the IP matches the element of the {{users}} list:
# 127.0.1.12 -> (1*256 + 12)-1 = 267 -> users[267]
# -1: first Array-Element is 0, but localhost-IP starts at 127.0.0.1
- name: create parallel execution localhosts group
add_host:
name: "127.0.{{item|int // 256}}.{{ item|int % 256 }}"
group: localhosts
with_sequence: start=1 end="{{users|length}}"
- name: create useraccounts
hosts: [localhosts] # [ 127.0.0.1, 127.0.0.2, ... ]
connection: local
gather_facts: no
vars:
users: [ 'Dave', 'Eva', 'Hans' ]
# this play runs in parallel over the [localhosts]
tasks:
- set_fact:
ip_nr: "{{ inventory_hostname.split('.') }}"
- name: parallel user creation
ansible.builtin.include_role:
name: create_user
vars:
user: "{{ users[ (ip_nr[2]|int*256 + ip_nr[3]|int-1) ] }}"
In this example: With forks=3 it runs in 11 seconds. With forks=1 (no parallelism) it takes 32 seconds.
The degree of parallelism (forks) depends on your use-case and your infrastructure. If you have to restore files, probably the network-bandwith, disk-I/O or the number of tape-slots is limited. Choose a value of forks that does not overload your infrastructure.
If some tasks or the whole role has to be run on another host than localhost (e.g. create a local useraccount on a server), then you can use delegate_to: "{{remote_host}}".
This principle can ideally be used for plays that are not bound to a specific host, usually for tasks that will run from localhost and calling a REST-API without logging in with ssh to a server.
SummaryAnsible is optimized to run playbooks on different hosts in parallel. The degree of parallelism can be limited by the “forks” parameter (default 5).
Ansible can run loops in parallel with the async mode. Unfortunately that does not work if we include a role or tasks.
The workaround to run roles in parallel on the same host is to assign every loop item to a different host, and then to run the role on different hosts. For the different hosts we can use the localhost IP’s between 127.0.0.1 and 127.255.255.254 to build a dynamic host-group; the number corresponds to number of loop items
L’article Parallel execution of Ansible roles est apparu en premier sur dbi Blog.
M-Files Backup considerations
 Once upon a time in IT project land
Once upon a time in IT project land
What an achievement, it’s been a good while your team is working on a huge project and it’s finally completed. All related documentation is well registered and managed into your knowledge workers enterprise content management, M-Files.
Time to get some rest and move on other tasks. Hence time is passing until dark moments show up and bring your attention to round to review and check your previous project documents to find answers regarding colleagues questionings. Bad luck, it looks like several content have disappeared. Even worse, you discovered others are corrupted. Leaving aside the root cause of all this, your first objective now is to retrieve your precious documents. And guess what, backups are your best friends.
M-Files deployment contextBefore considering technical details, let’s assume your M-Files vault(s) is on-premise deployed. Note that if you are working with M-Files Cloud vault(s) then M-Files Corporation is maintaining and backing up your vault for you. M-Files Cloud offers a default standard backup service as part of every M-Files subscription. Moreover, it is possible to extend your backup capabilities based on retention and recovery point settings.
This said, do mind we shall have different situations:
- M-Files Server + Microsoft SQL Database + object files distributed either on a single server or across multiple servers
- M-Files Server + Firebird SQL Database + object files only on a single server
One must admit Firebird SQL Database is a nice choice when you start working with M-Files in order to be confidant quickly and easily with the tool. But keep in mind, as soon as you are managing millions of objects, furthermore in a production context, it is highly recommended to review your local server infrastructure and consider working with / migrating to Microsoft SQL database.
M-Files server-specific dataWhatever M-Files configuration type is in place, you must always take care of your master database. This is where server-specific data reside and it is always stored in an embedded Firebird SQL database. Information stored are:
- Information on transactions since the last backup
- Login accounts
- M-Files login passwords
- Personal information
- License types
- Server-level roles
- Scheduled jobs
- Notification settings
- Licenses
- M-Files Web settings
As you can imagine, these information are important and must be taken into account with care as much as your Document Vault backup does. Hence, I would recommend to take regular Master Database backups according to your needs and system criticality.
M-Files vault-specific dataAccording to database software used to store these information, either an embedded Firebird or Microsoft SQL server, M-Files provides you the possibility to do full and differential backup. Differential backups contain changes since the last full backup which includes all object files and vault metadata such as:
- Objects with their version history, files, and metadata
- Value lists, property definitions and classes
- Metadata structure
- Users, user groups and named access control lists
- User permissions and vault roles
- Workflows
- Connections to other systems
- Event log
- Vault applications and scripts
Note it is possible to store object files inside Microsoft SQL server database, whereas this is not an option with Firebird (always stored in file system). Nevertheless, this may lead to performance issues in large environment and should be consider with care if not avoided.
In case of using embedded Firebird database, simply schedule all vaults back up jobs in M-Files Admin.
With Microsoft SQL server database engine, you must back up both the Microsoft SQL database and the files in the file system separately. It is important to always back up Microsoft SQL database first and then the file system data to avoid any references to non-existing object files.
Other data to considerSome secondary data are not saved during above backup procedures. Instead, these are re-created after a restore operation. Think about index files, PDF renditions and thumbnails stored on M-Files server hard drive and pay attention to rebuilding duration. In large vault, the amount of time to rebuild search indexes can take a lot of time. Hopefully, it is feasible to back up and restore them accordingly. Depending on search engine used, procedure can be slightly different but feasible.
Last, do not forget any system modification(s) such as Windows registry, notification message templates or whatever M-Files Server installation folder files since these will not be included in Master or Vault backups.
Advices
Things are always easier said than done but it might get even worse than ever if you do not pay attention to few M-Files backup best practices. Hardware failure, accidental deletions, cyberattack, logical and or human errors happen. To be prepared to face such issues:
- Plan, do, act and check your backup plan considering your systems criticality, Business and end-users SLA and constraints.
- Do not hesitate to lean on your IT Administrator support teams and M-Files Architect to validate choices made and review potential architecture weakness.
- Avoid taking data file system snapshot on active M-Files system servers where data is stored (inconsistency and damaged files may occurred).
- Apply the 3-2-1 backup strategy for the best (store 3 copies of your data, in at least 2 types of storage media with1 in a secure off-site location)
On top of this, OR/DR test exercise shall prevent and reveal most of your backup plan gap(s). Thus you will be prepared to solve backups issues validating, in passing, their integrities.
If you need further assistance, do not hesitate to contact dbi services for any M-Files support and guidance around this topic and others.
Enjoy your knowledge work automation tasks with M-Files.
L’article M-Files Backup considerations est apparu en premier sur dbi Blog.
stikhar iz rossii

The blood of the martyrs is the seed of the Church.
This present moment
I sat upon the shore
Azure Bootcamp Switzerland 2025

Last week I attended the Azure Bootcamp Switzerland 2025 with my colleague Adrien from the Cloud team. It was the 1st time for us but it was already the 6th edition of the event. This is a community event and non-profit event on an obvious topic: Azure
It’s a quite intensive day, 2 keynotes and 15 presentations split in 3 different streams. We took the ticket some ago and I was quite surprised by the amount of people interested in Azure topics. Indeed, just before the keynote, they announced the event was sold out. I know already the location since it’s at the same place than the Data Community Conference I participated last year.
Since we were two people at the event, we were able to split in the different streams. I followed sessions on really different topics: building AI application for Swiss government, Building Data platform, FinOps, Platform engineering with Terraform and DNS for hybrid environments.
All presentations were interesting but I’ll bring the focus on 2 of them: Cost observability with new FinOps standard FOCUS and DNS in hybrid environments because I think these 2 topics are really in important in the current deployments. The 1st one is quite obvious, you should not go to public Cloud without monitoring your costs. And the 2nd one, in my opinion, many companies are deploying Cloud but still have on-premise workload and it’s important to know how to live in this hybrid world.
Level up your Cost Observability with the new FinOps standard FOCUS and Microsoft Fabric
We discussed this FinOps topic already within the Cloud team at dbi services. But we may have overlooked the FOCUS specification by trying to create our own mapping in the different Cloud cost usage exports. The public Cloud providers are not strictly following the specification and there are some tips in the slides. Using Fabrics is then a good example on how the cost data can be processed.
DNS in hybrid cloud environments – can it be that hard?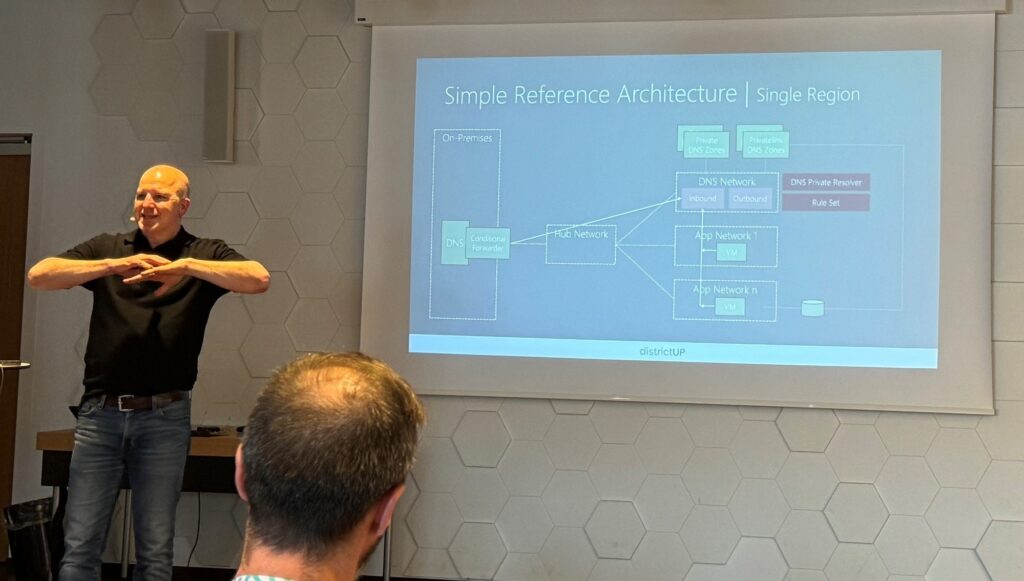
On DNS side, the main take-away of this presentation is to correctly plan your DNS needs. In most cases, you will not use fixed IPs when you work with public Cloud. Usually, IPs are provided automatically when network interfaces are created. Then DNS is a critical component to ensure a good communication between all your instances/services. The DNS should be part of your network design from the beginning to ease the management of the DNS and avoid DNS private zones scattered at different places.
L’article Azure Bootcamp Switzerland 2025 est apparu en premier sur dbi Blog.
M-Files Online June 2025 (25.6) Sneak Preview
The June 2025 release of the M-Files Client is just around the corner, and as an M-Files partner, we have the opportunity to access the Early Access Release. As it rained heavily over the Whitsun holiday, I decided to spend some time installing the new version and exploring its features and improvements.
A quick look at the release notes revealed that this update would introduce the much-anticipated graphical workflow feature. This allows end users to easily observe the workflow status. But that’s not all, as you can read below.
- New M-Files Desktop and Web: Visual Workflows
- New M-Files Desktop: Global Search
- New M-Files Desktop: Co-authoring improvements
- New M-Files Desktop and Web: M-Files URL improvements
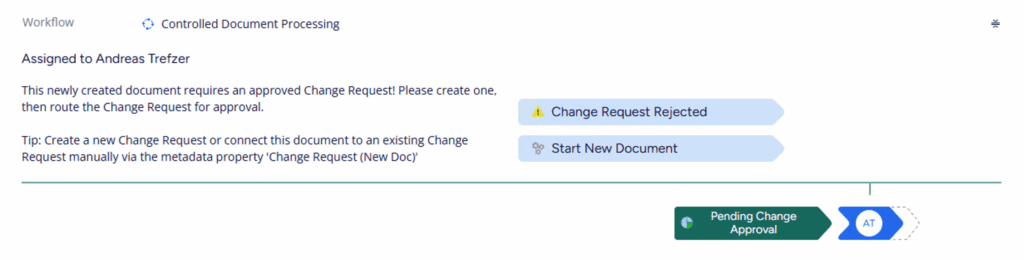
During the M-Files Global Conference 2025, the launch of visual workflows was announced to great enthusiasm. I actually heard about the implementation of this feature several months ago and have been waiting for it ever since. I am therefore very happy that it is now available, as it will provide real added value for M-Files end users. Graphical views are easier for people to understand when they want to quickly grasp the status of a task or, in this case, the workflow of a document.
The screenshot below shows the new graphical view. As you can see, the current workflow status and the next step are displayed at the bottom. Furthermore, if you are the person with the next action in the workflow, there are buttons above the workflow status to easily perform the action.
For me, the action buttons in the new client are key, as the new client does not have the left-hand actions bar that the old client has. In my opinion, this implementation enhances the end-user experience and encourages end-users to migrate to the new, modern client.
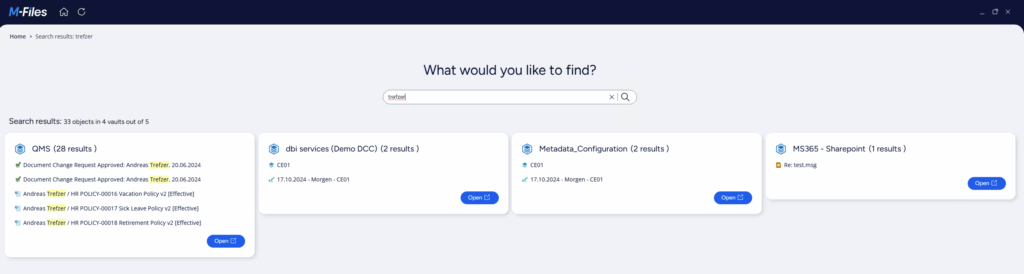
 Global Search
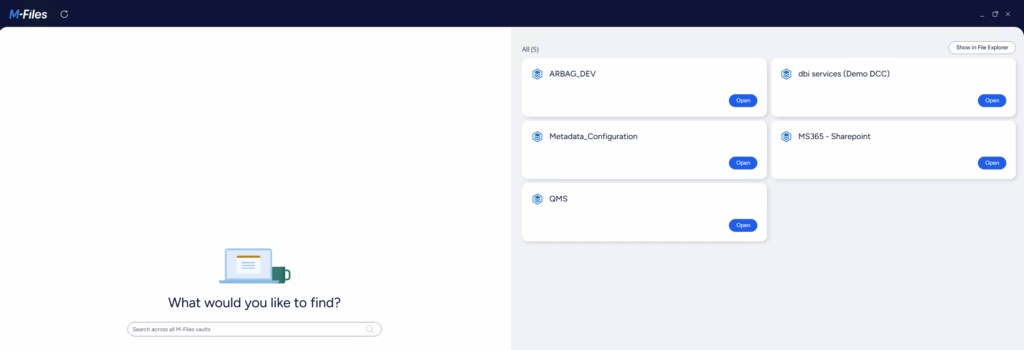
Global Search
With global search enabled in the M-Files client, you can search all the vaults you have access to. Furthermore, the home screen now displays all the vaults that you have access to. You can access them with just one click.
You can also perform global searches directly using the search box on the home screen. This enhancement is especially useful for users who have access to multiple M-Files vaults, like me. It makes my work faster and smoother and is a great feature.
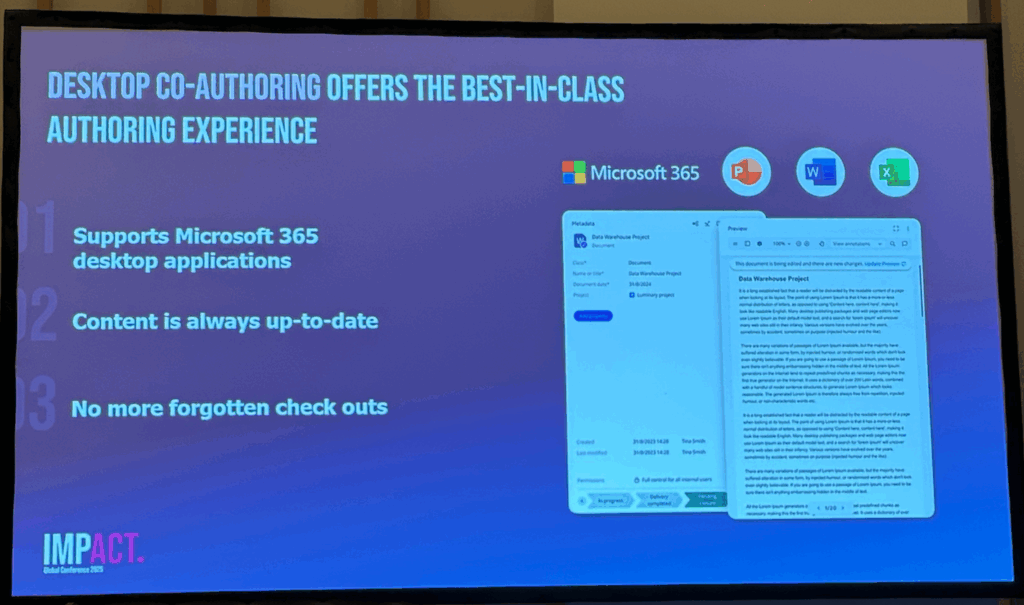
 Co-authoring improvements
Co-authoring improvements
Create new Office documents and co-author them in Microsoft 365 Office desktop applications. This new release makes co-authoring the default behaviour when opening a document. See the latest live document changes in M-Files. Any user with the necessary access rights can co-author a document and save new versions of the document to M-Files.
 M-Files URL improvements
M-Files URL improvements
The implementation of this feature is a clear statement of the willingness to integrate the known functions from the M-Files Classic Client in the new and modern M-Files Client. I had a look in to the client development roadmap and it confirms me the commitment of M-Files to enhance the new and much faster client to make them available for the end-users. The next logical step was to enable and improve URL handling. Please find below a brief summary of the URL improvement news.
- Open view and edit specified document in Web via links
- Support for search links
- Property-based search in Web and Desktop via Links
- External ID support for objects in grouping levels
I am pleased to inform you that a new client will be available in June for all M-Files end-users. In my professional opinion, the most significant enhancement is the implementation of the graphical workflow, and of course the deeper integration within the Microsoft ecosystem, with the enablement of co-authoring with M-Files.
I hope you are also feeling as overwhelmed as I am about this new M-Files Client. Should you wish to see them in action, please do not hesitate to contact us or me. We will be happy to arrange a demonstration to illustrate the potential of M-Files to enhance your business.
L’article M-Files Online June 2025 (25.6) Sneak Preview est apparu en premier sur dbi Blog.
Additonal help with JSON object - Add/Remove items from array within a JSON object
Deadlock while doing parallel operation
Azure Bootcamp Switzerland 2025, an Azure day in Bern
On June 5th I could participate to Azure Bootcamp Switzerland in Bern. The event gave me the opportunity to attend multiple presentations on various Azure topics.

From AI to serverless integration to the cloud and networking, the conference’s topics were various and always interesting.
We had for example two keynotes during the day, one speaking about how to transform DevOps with a multi tools platform and the other one giving us an AI journey in the Nvidia scope.
I attended as well some security and networking sessions. For example, I attended a session on how to master network security in Azure, where we had some details on how to manage correctly Network Security Groups or Azure Firewalls.

This day was very interesting and the diversity of topics was really something that made me like it even more. I could learn a lot of things during all the presentations. Hopefully it takes place again next year and I can come again.
L’article Azure Bootcamp Switzerland 2025, an Azure day in Bern est apparu en premier sur dbi Blog.
Oracle DMK release 2.2.0 new features / Windows support.
DMK is a Database Management Kit that can be used in various database environments.
It simplifies command-line tasks for Databases Administrator on Unix and Windows systems. It supports multiple databases including Oracle, MongoDB, MariaDB, and PostgreSQL. It also includes additional modules for automating RMAN backups, database duplication, and database creation.
dbi-services recently released version 2.2.0, introducing significant improvements for Oracle databases with RAC/ASM and enhanced support for Windows.
You can check here more details:
https://www.dbi-services.com/products/dmk-management-kit/
Below example how its showing on command line processes output :
 Windows support:
Windows support:
Now managing your Oracle databases on Windows server has never been easier.
Just clicking DMK.cmd shortcut on your Desktop open you directly command line with DMK API.
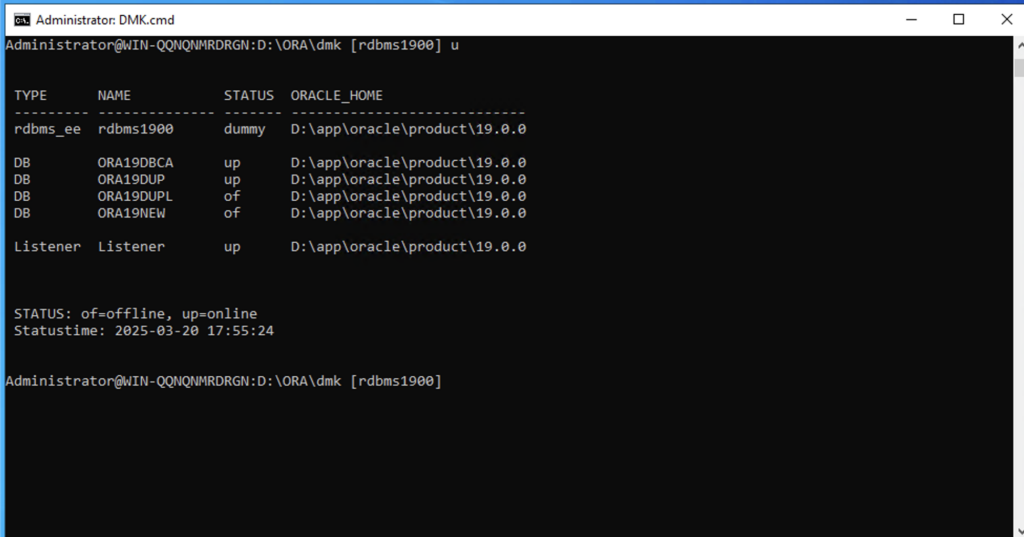
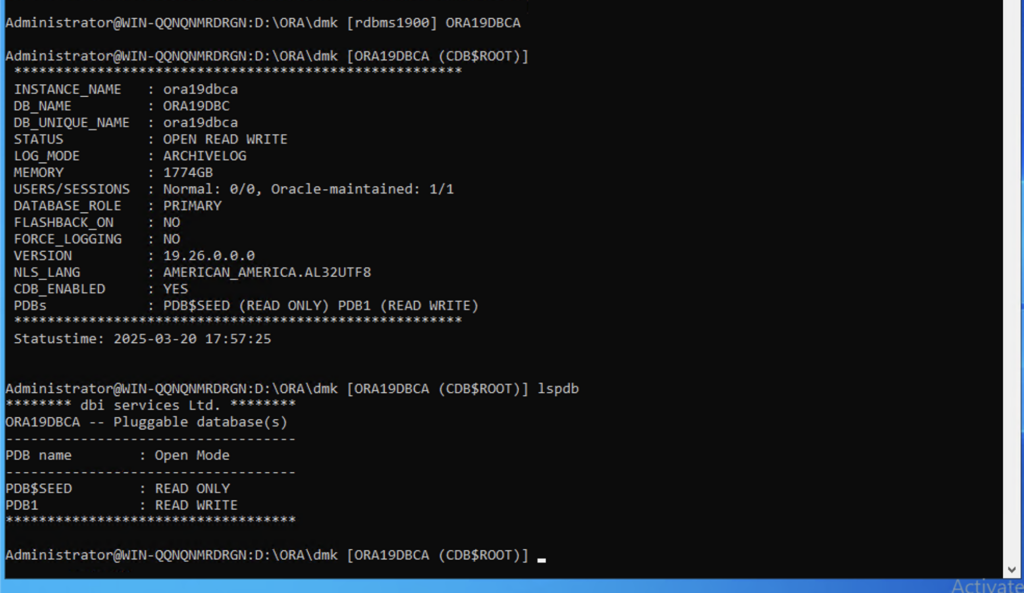
Using commands like istat/CDBNAME/lspdb we can easly navigate between our databases.
With simple alias ‘u’ we can see all databases on Windows server.
You can easily list or connect to your Multitenant PDBs just by using alias like lspdb. Use PDBNAME to directly login to your PDB:
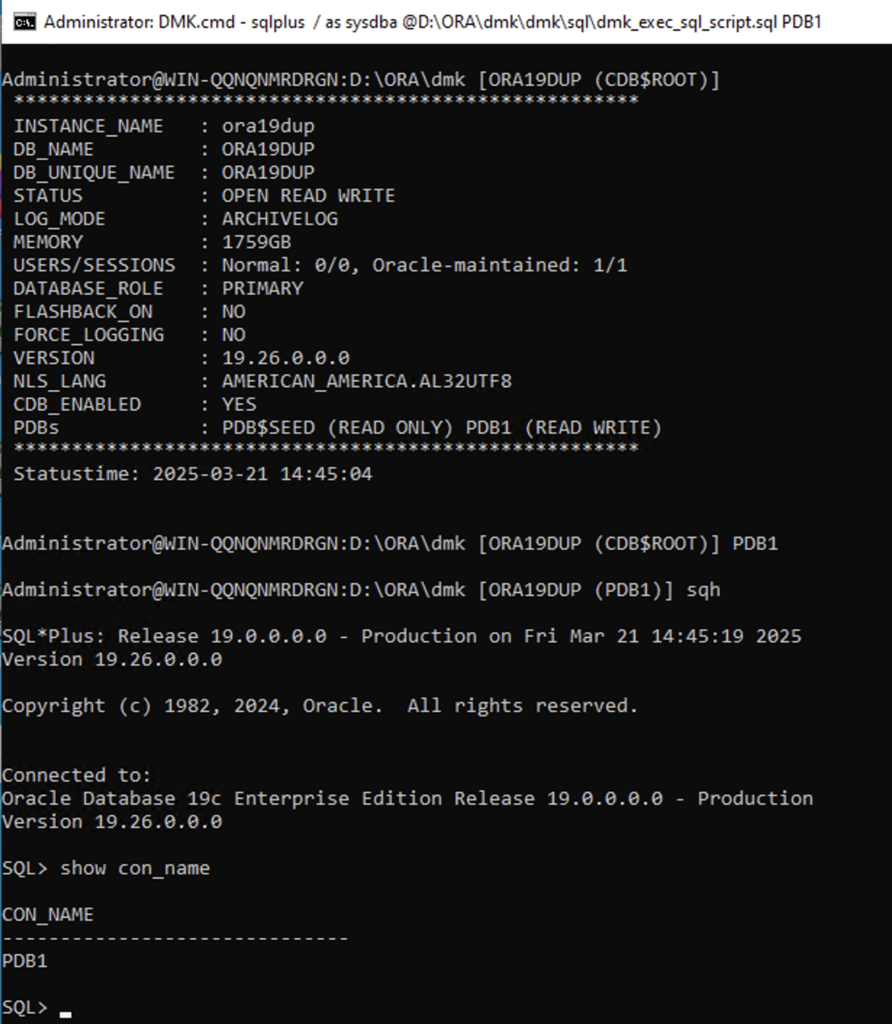
in connection of DMK_backup and DMK_dbcreate DMK_dbduplicate its quite a powerful pack to manage your databases on Windows platform.
Now syntax and output is fully compatible with Linux version
This version also not need extra Perl installation, at it will use Perl binaries from Oracle Home on Unix and Windows OS.
sqlplus/rman/asmcmd work with command history, simply use sqh and arrrow ‘up’ and ‘down’ to navigate over your previous selects:
Usefull aliases:
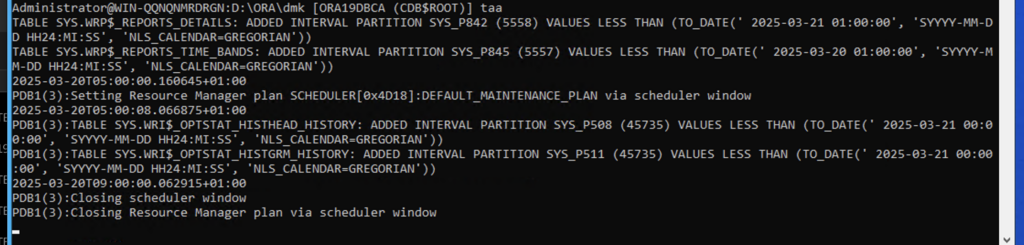
taa – tail on alertlog
cdh- move to current ORACLE_HOME
cdd -move to DMK home
sqh – sqlplus with history
asmh -asmcmd with history
rmanh – rman with history
cddi – move to current DB DIAG_DEST
vit/vil/vio – giving you fast access to edit your current tnsnames listener and oratab config without long time looking them all over filesystem.
Full list of aliased you can find in DMK documentation under this link
Below example of tail on alertlog:
Now also when your environment change:
· new ORACLE_HOME
· changed ORACLE_HOME
· new/removed ORACLE_SID
· new/removed PDB’s
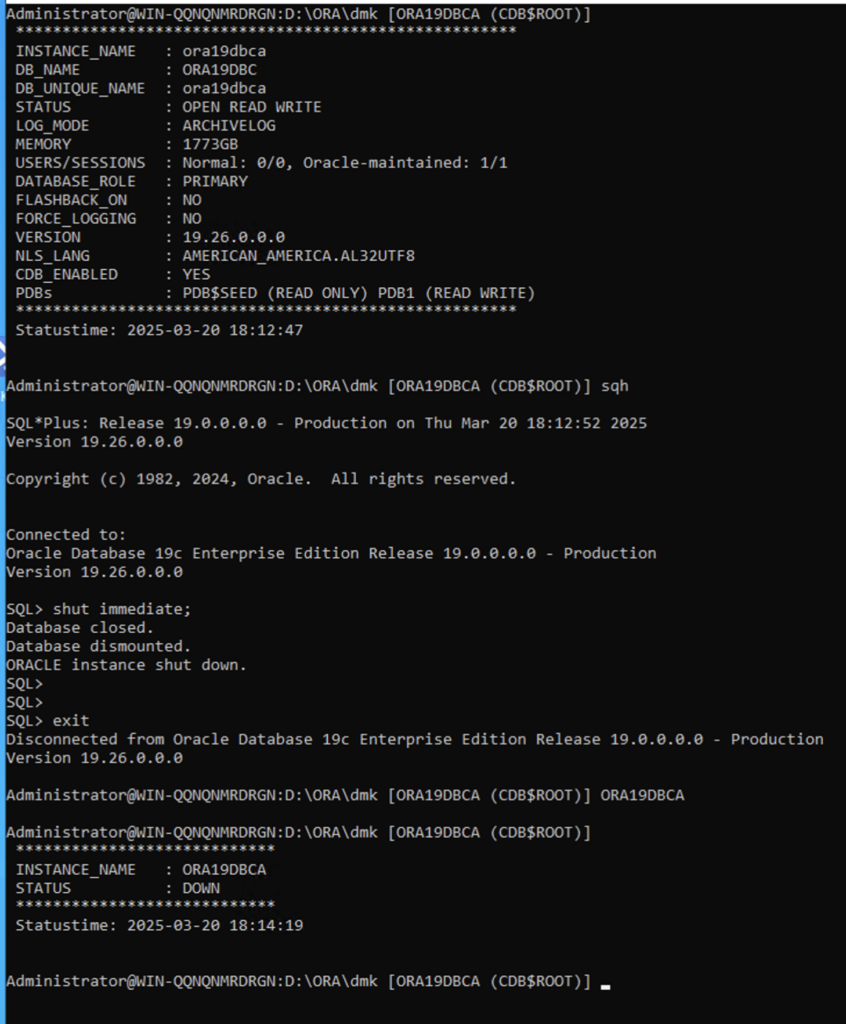
DMK will automatically adjust informations and aliases.

Now when you type ‘u’ or SID, all your instances are refreshed from actual state also when some of database up/down status changed:
These changes also apply to Linux version.
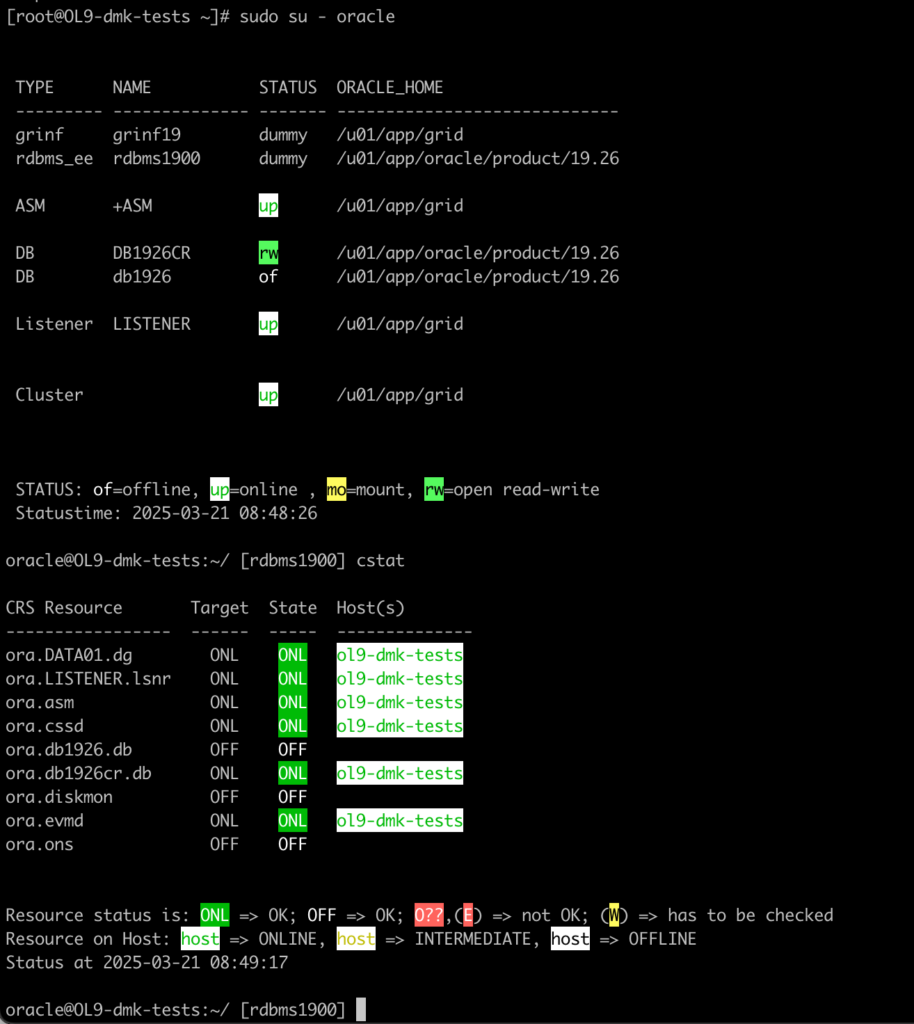
Oracle RAC / Clusterware :For Oracle with RAC/Clusterware configuration there are also some improvements.
Use cstat to see crs resources in colored output.
Also you can check your ASM instance:
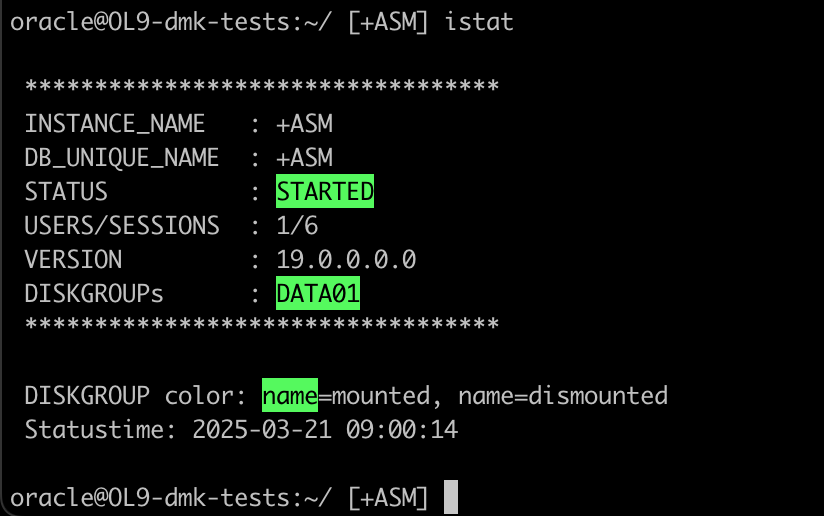
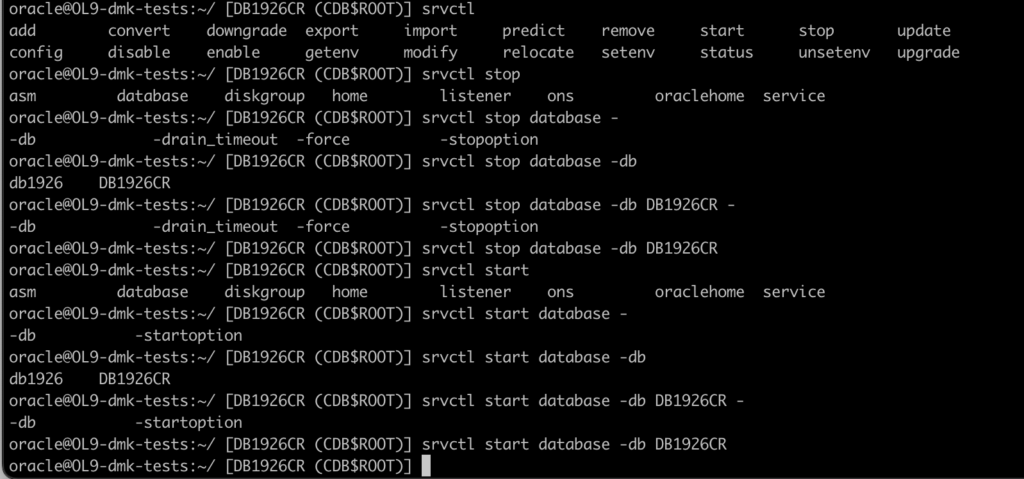
What is also interesting for srvctl command we implemented command-completion with tab
So you don’t need to think anymore about proper srvctl command arguments (and as you know its a lot of options). Now, just choose from the list using [tab]
For example, stopping and starting database.
DMK not only helps to use command line commands , but it also helps to keep structural Oracle Optimal Flexible Architecture (OFA) standards of your naming convention/folder structure and keep Oracle best practices for database configuration. By installing additional modules for backup/duplication/dbcreate, you can provide instant standardization and improve quality for your environments.
You can read more in DMK documentation under this link.
L’article Oracle DMK release 2.2.0 new features / Windows support. est apparu en premier sur dbi Blog.
JSON_OBJECT_T.GET_CLOB(key) returns the string 'null' if the value is null
Discovery of the day on Oracle 19 version EE 19.21.0.0.0:
JSON_OBJECT_T.GET_CLOB(key) member function returns a CLOB string containing 'null' (lowercase), not a NULL value.
As you can see below the 'null' string is matched by the function NULLIF which replaces it with a real NULL value:
set serveroutput on
declare
l_procedure clob;
j_job_desc json_object_t;
begin
j_job_desc := json_object_t.parse('{"procedure":null}');
l_procedure := nullif(j_job_desc.get_clob('procedure'),'null');
if l_procedure is null then
dbms_output.put_line('nothing');
else
dbms_output.put_line(l_procedure);
end if;
end;
/
nothing
PL/SQL procedure successfully completed.
The documentation doesn't explain this behavior at all, it just says that the member function will create a CLOB implicitly and that's all,