DBA Blogs
Hi,
I have a database with thousands of tables containing the same kind of information.
I need to write a program to aggregate these informations and thought about using a sqlmacro.
<code>
-- This is a very simplified concept
create or replace
function get_val (p_table_name varchar2)
return varchar2 SQL_Macro
is
return 'select col1,col2 from p_table_name';
end;
/
select col1, col2
from get_val(t.table_name)
, table_list t; --Table_list contains the list of the table to take
</code>
And it always tells that the table doesn't exist.
The documentation talks about DBMS_TF.TABLE_T, which works if you pass the table as the parameter (and not the table's name).
How can I do that? Do I have to write a function returning the rows from the table?
Thank you
<code>SQL> select banner from v$version where rownum=1;
BANNER
--------------------------------------------------------------------------------
Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
SQL> create table t1(id int generated BY DEFAULT ON NULL as identity);
Tabelle wurde erstellt.
SQL> create table t2(id int generated BY DEFAULT as identity);
Tabelle wurde erstellt.
SQL> create table t3(id int generated ALWAYS as identity);
Tabelle wurde erstellt.
SQL> select table_name, generation_type
2 from user_tab_identity_cols utic
3 where utic.table_name in ('T1', 'T2', 'T3');
TABLE_NAME
--------------------------------------------------------------------------------
GENERATION
----------
T1
BY DEFAULT
T2
BY DEFAULT
T3
ALWAYS</code>
Why doesn't user_tab_identity_cols.generation_type show "BY DEFAULT ON NULL" for T1 ?
Behaviour is differently in comparison to T2, so where can I see it (besides DBMS_METADATA) ?
<code>
SQL> set long 5000 lines 300 pages 5000
SQL> select dbms_metadata.get_ddl('TABLE', table_name) from user_tables where table_name in ('T1', 'T2');
DBMS_METADATA.GET_DDL('TABLE',TABLE_NAME)
--------------------------------------------------------------------------------
CREATE TABLE "YYY"."T1"
( "ID" NUMBER(*,0) GENERATED BY DEFAULT ON NULL AS IDENTITY MINVALUE 1 MAXVAL
UE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NO
CYCLE NOKEEP NOSCALE NOT NULL ENABLE
) SEGMENT CREATION DEFERRED
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
TABLESPACE "XXX"
CREATE TABLE "YYY"."T2"
( "ID" NUMBER(*,0) GENERATED BY DEFAULT AS IDENTITY MINVALUE 1 MAXVALUE 99999
99999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NOCYCLE N
OKEEP NOSCALE NOT NULL ENABLE
) SEGMENT CREATION DEFERRED
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
TABLESPACE "XXX"
</code>
We use Business Objects against a database setup just for generating reports. This is an Exadata RAC with 2 nodes and ASM storage and all of the BO sessions login/connect to the same oracle user.
During our last month-end, which coincided with quarter-end, we saw many session with "env: SS - contention" wait event. Also intermittently saw "buffer busy waits" as they all wait for access to the shared temporary tablespace, as indicated by the P1 Value.
Searching for answers on how to reduce these wait events led us to Local Temporary Tablespaces. So we setup a Local Temp Tablespace in our development environment...
<code>CREATE LOCAL TEMPORARY TABLESPACE FOR ALL temp_reporting_local
TEMPFILE '+DTADVQ1/.../TEMPFILE/temp_reporting_local.dbf'
SIZE 10G AUTOEXTEND OFF
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 2M;
</code>
Assigned it to the REPORT_USER as it's default Local Temp Tablespace...
<code>ALTER USER report_user LOCAL TEMPORARY TABLESPACE temp_reporting_local;
SELECT username, default_tablespace, temporary_tablespace, local_temp_tablespace
FROM DBA_USERS
WHERE username = 'REPORT_USER';
USERNAME DEFAULT_TABLESPACE TEMPORARY_TABLESPACE LOCAL_TEMP_TABLESPACE
REPORT_USER TBE_REPORT_USER_01 TEMP_REPORTING TEMP_REPORTING_LOCAL
</code>
Then ran some large queries while logged in as REPORT_USER. The query fails with same error message as before: "ORA-01652: unable to extend temp segment by 256 in tablespace TEMP_REPORTING".
Monitoring Free Space, the Local Temps do not appear to have been used at all.
<code>SELECT tablespace_name, inst_id,
tablespace_size/1024/1024 AS total_mb,
allocated_space/1024/1024 AS allocated_mb,
free_space/1024/1024 AS free_mb
FROM dba_temp_free_space
WHERE tablespace_name LIKE 'TEMP_REPORTING%';
TABLESPACE_NAME INST_ID TOTAL_MB ALLOCATED_MB FREE_MB
TEMP_REPORTING 10240 10240 0 (assumed to be zero at instant report died)
TEMP_REPORTING_LOCAL 1 10240 2 10238
TEMP_REPORTING_LOCAL 2 10240 2 10238
</code>
A hash join exceeded the 10GB of shared temp but did not use any of the Local temp.
So, how can we get these queries to use Local Temp once Shared Temp "overflows"? I'm thinking it is because it cannot spit the hashed results between the two. Which makes me wonder how it will ever use local temp tablespaces.
Second question: why did they not set it up to use the Local Temp first and then overflow into the Shared Temp, if needed? Seems like a more logical approach if you want to mitigate these wait events.
I am trying to setup a database project that has three or so schemas that are named the same for most of the deployed environments but are different for one deployment. For example local development through production would have schema names schema1, schema2, ... but for one set of deployed environments the schemas have been renamed and are out of my control, e.g., dba_schema_db1, dba_schema_db2, ...
What I want to know is if there is a built in way using SQLcl projects to alias the schemas so that they can be configured per environment without too much manual intervention.
Hi. What is the technical reason why the package DBMS_DEBUG_JDWP is not available on the Oracle Autonomous Database? What does it do that makes calling it illegal in PL/SQL?
Thanks,
I have a table with partitions and I would like to find the most efficient way to empty a clob column for an entire partition.
I thought I could use DBMS_REDEFINITION with col_mapping and part_name but I am always getting ORA-42000.
Here are the statements I am using to reproduce the issue.
<code>create table tkvav_part_redefinition (
id number primary key,
num varchar2(10),
ts timestamp,
mynum number,
mylob clob
);
insert into tkvav_part_redefinition values (1, '42' , systimestamp + 59/23,12,'123');
insert into tkvav_part_redefinition values (2, '-9.876', systimestamp + 51/31,34,'234');
insert into tkvav_part_redefinition values (3, '1.2e3' , systimestamp + 61/17,25,'345');
insert into tkvav_part_redefinition values (4, '42' , systimestamp -10 + 59/23,68,'123');
insert into tkvav_part_redefinition values (5, '-9.876', systimestamp -10 + 51/31,69,'234');
insert into tkvav_part_redefinition values (6, '1.2e3' , systimestamp -10 + 61/17,70,'345');
insert into tkvav_part_redefinition values (7, '42' , systimestamp -20 + 59/23,75,'123');
insert into tkvav_part_redefinition values (8, '-9.876', systimestamp -20 + 51/31,76,'234');
insert into tkvav_part_redefinition values (9, '1.2e3' , systimestamp -20 + 61/17,77,'345');
commit;
select rowid,x.* from tkvav_part_redefinition x;
ALTER TABLE tkvav_part_redefinition MODIFY
partition by range (ts) interval (NUMTODSINTERVAL(7, 'DAY'))
( PARTITION P1 VALUES LESS THAN (to_date('20260202', 'yyyymmdd'))
) ONLINE;
select TABLE_NAME, PARTITION_NAME from user_tab_partitions where table_name = 'TKVAV_PART_REDEFINITION';
create table tkvav_part_redefinition_int4 FOR EXCHANGE WITH TABLE tkvav_part_redefinition;
begin
dbms_redefinition.start_redef_table(
uname => user,
orig_table => 'tkvav_part_redefinition',
int_table => 'tkvav_part_redefinition_int4',
col_mapping => q'[
id,
num,
ts,
cast(null as number) mynum,
empty_clob() mylob
]',
options_flag => dbms_redefinition.cons_use_pk,
orderby_cols => null,
part_name => 'SYS_P1438977',
continue_after_errors => false,
copy_vpd_opt => dbms_redefinition.cons_vpd_none,
refresh_dep_mviews => 'N',
enable_rollback => false
);
end;
/</code>
ORA-42000: invalid online redefinition column mapping for table "EP2_ST675"."TKVAV_PART_REDEFINITION"
ORA-06512: at "SYS.DBMS_REDEFINITION", line 116
ORA-06512: at "SYS.DBMS_REDEFINITION", line 4441
ORA-06512: at "SYS.DBMS_REDEFINITION", line 5835
ORA-06512: at line 2
It works without any issues when I set part_name => null.
what am I doing wrong when using part_name ?
Hi Tom!
We have a large load every day from one table to another and I wanted to split it up into chunks and run parallel jobs to speed it up.
I found that doing the split on rowid doesn't work on partitioned table. First I did it on partition level since this is how we load (partition by partition via dynamic SQL) but I should have realized that wouldn't work.
But I got really surprised that the split doesn't work even if I do it on whole table without partition. And I have tested at a few tables we have and it works, as long as its not a partitioned table.
I am quite confused with this, is there an explanation?
So this sql:
<code>SELECT MIN(r) start_id
,MAX(r) end_id
FROM (SELECT ntile(20) over (ORDER BY rownum) grp
,ROWID r
FROM my_big_table)
GROUP BY grp ;</code>
Gets it into 20 chunks but when testing the first chunk via this sql:
<code>SELECT COUNT(9)
FROM my_big_source_table
WHERE ROWID BETWEEN 'AACGW1AELAAN72EAAB' AND 'AACGW1AH7AADmn/AAY';</code>
it simply fetches the whole table. If I do the same on any other table that isn't partitioned it works fine as with the example in FreeSQL.
DBAs spend a lot of time reviewing reports about the health of their databases. I’ve used an LLM to speed up that process.
I took a daily report about our Oracle databases and used an LLM to generate a short summary that lets a DBA immediately see which databases need attention.
A typical report looks like this for each database:
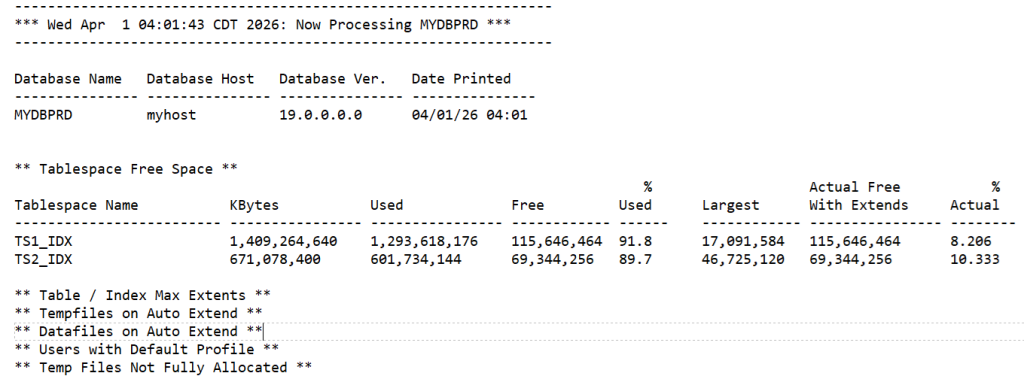
The full report has over 2,000 lines that must be manually scanned by the on-call DBA each day.
The LLM-generated summary looks like this:
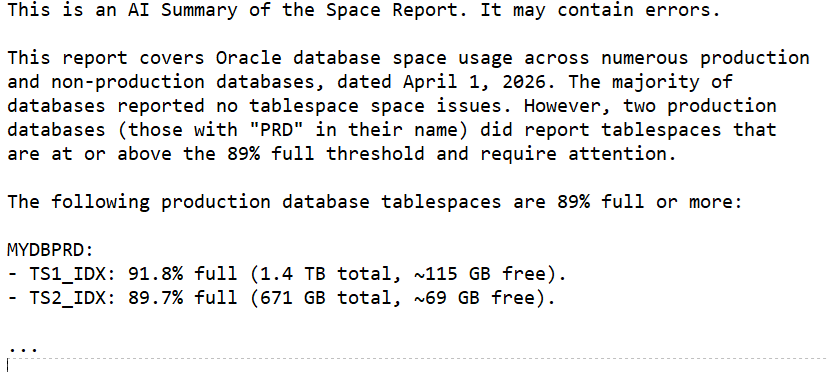
This summary immediately shows which databases need attention. We still manually scan the entire report but having the summary in the body of the email (with the full report attached) lets us see at a quick glance what needs attention and how urgent it is. The summary does not replace the full report; it only highlights the items that are most likely to be important. In our environment we chose 89% full as the point where we start reporting on space issues.
I’m using AWS Bedrock with the Claude Sonnet 4.6 model. Here is the Python
function that sends the combined prompt and report to Bedrock and returns the summary:
Here is the prompt that preceeds the report:

This simple use of an LLM has saved me time by putting a quick summary in the email body while preserving the full report for detailed review.
Bobby
How to troubleshoot this error:
[oracle@localhost ~]$ sudo setenforce 0
[sudo] password for oracle:
[oracle@localhost ~]$ export ORACLE_BASE=/u01/app/oracle
[oracle@localhost ~]$ export ORACLE_HOME=$ORACLE_BASE/product/19.0.0/dbhome_1
[oracle@localhost ~]$ export PATH=$ORACLE_HOME/bin:$PATH
[oracle@localhost ~]$ export ORACLE_SID=FREE
[oracle@localhost ~]$ export CFGTOOLLOGS=/tmp/dbca_logs
[oracle@localhost ~]$ mkdir -p /tmp/dbca_logs
[oracle@localhost ~]$ chmod 777 /tmp/dbca_logs
[oracle@localhost ~]$ mkdir -p /u01/app/oracle/oradata
[oracle@localhost ~]$ chmod -R 775 /u01/app/oracle
[oracle@localhost ~]$ chown -R oracle:oinstall /u01/app/oracle
[oracle@localhost ~]$ unset DISPLAY
[oracle@localhost ~]$ $ORACLE_HOME/bin/dbca -silent -createDatabase \
> -templateName General_Purpose.dbc \
> -gdbname FREE \
> -sid FREE \
> -createAsContainerDatabase true \
> -numberOfPDBs 1 \
> -pdbName FREEPDB \
> -sysPassword Oracle \
> -systemPassword Oracle \
> -pdbAdminPassword Oracle \
> -databaseType MULTIPURPOSE \
> -memoryMgmtType auto_sga \
> -datafileDestination /u01/app/oracle/oradata \
> -emConfiguration NONE
[FATAL] [INS-00001] Unknown irrecoverable error
CAUSE: No additional information available.
ACTION: Refer to the logs or contact Oracle Support Services
SUMMARY:
- [DBT-00006] The logging directory could not be created.
- [DBT-00006] The logging directory could not be created.
[oracle@localhost ~]$
When I try to read data from a CSV file using an Oracle external table, I get the following error:
ORA-29913: error in executing ODCIEXTTABLEOPEN callout
ORA-29400: data cartridge error
What are the possible causes of this error, and how can I fix it so that the external table can read the CSV file successfully?
I need to propagate changes on a few tables to an external system. I have to do it near realtime and ultimately it will end up on Kafka from my end. The solution target is Oracle 19c and needs to be installed to multiple clients on premises.
Example problem:
Let's say I have table of messages. I have a column called change_id which is populated by trigger from a sequence on insert and update. Theoretically I always know which row was changed last. i might avoid needing to track deletes, not sure yet.
Now I create a procedure to be ran as a batch and collect rows changed from last run. First it gets the max(change_id), then selects all rows between last_run_max_change_id and new_max_change_id. Exports data as json to another table. writes new_max_change_id as last_run_max_change_id. Commits. Another process will handle delivery of json to where it needs to be.
The problem is another long running transaction might have consumed sequence with lower numbers but has not commited when batch was run, thus those change_ids will never be exported. Another problem is I don't have deleted rows.
Solution 1: Golden Gate replication or OpenLogReplicator or something similar. I would have to convince all clients to commit to paying the GG licence, create tables as replication target, export from those tables, delete from them. Licence and getting all clients on board is difficult, because i need one solution for all. Also security, stability and maintenance concerns will likely make clients want to reject such ideas, and it has to be all of them onboard. I have also tried to use Oracle Streams before on another project and had stability issues and ORA-600 errors that were never resolved.
Solution 2: use SCN instead of change_id. SCNs (ora_scnrow) are not indexed and select by scn in where clause on billions of rows is too slow.
Solution 3: Flashback. Have something like SELECT * FROM messages VERSIONS BETWEEN SCN :last_scn AND :current_scn; My concern is if the program doesn't run for a while for whatever problem and reason, the flashback will be lost. I would need a backup solution.
Solution 4: trigger after insert on messages table that will write to export table. Handles insert, update, delete and nothing will be skipped. I select 10k ids ordered, export to json, delete 10k records and commit; I'm worried about big transactions having additional load to write to export table and trigger overhead for each row. Additional context switching. Index contention on export table having rows at the same time inserted by inserts and updates on original table and rows deleted by export batch process. Exports will have to be ordered by change_id.
Conclusion: The only stable and data consistent solution I can think of is solution 4, a trigger. But I'm worried about overhead.
Instead of a trigger, I could check the code and program additional inserts into export log table so that the total number uf updates might be lower but not by much.
A...
Hello,
I have a question regarding concurrent statistics gathering in Oracle 19c. Currently, my global preference is set to OFF:
SELECT DBMS_STATS.GET_PREFS('CONCURRENT') FROM DUAL;
-- Result: OFF
I can enable it manually with:
BEGIN
DBMS_STATS.SET_GLOBAL_PREFS('CONCURRENT','ALL');
END;
/
I understand that enabling CONCURRENT allows Oracle to gather statistics on multiple tables and (sub)partitions at the same time, potentially reducing the total duration. Oracle uses the Job Scheduler and Advanced Queuing to manage these concurrent jobs.
My question:
Is there a relationship between the maintenance windows (like WEEKEND_WINDOW or WEEKNIGHT_WINDOW) and concurrent statistics gathering? Specifically:
When CONCURRENT is enabled, does Oracle automatically schedule these parallel stats jobs within the maintenance windows?
Or is the maintenance window unrelated, and the concurrent gathering runs independently of it?
Thank you for your guidance.
All,
I have an Oracle view built on top of a partitioned table. Occasionally the view becomes INVALID, even though there are no DDL changes happening on the base table. The view becomes VALID again automatically when it is accessed or queried, but this behavior is causing issues in production.
I'm trying to understand what could be causing the intermittent invalidation.
<code>
create view my_view as
SELECT dly_fct_id, acct_ref_id, bus_dt
FROM my_table
WHERE bus_dt = TO_DATE('01/01/2500','MM/DD/YYYY');
</code>
Note: The date above is only a placeholder. In reality this predicate changes dynamically based on the ETL run date.
Base table structure:
<code>
CREATE TABLE my_table
(
dly_fct_id NUMBER,
acct_ref_id NUMBER,
bus_dt DATE
)
PARTITION BY RANGE (bus_dt)
INTERVAL (NUMTODSINTERVAL(1,'DAY'))
(
PARTITION p0 VALUES LESS THAN (TO_DATE('01-JAN-1900','DD-MON-YYYY'))
)
COMPRESS;
</code>
Constraint:
<code>
ALTER TABLE my_table
ADD CONSTRAINT xpk_my_table
PRIMARY KEY (dly_fct_id, acct_ref_id)
RELY;
</code>
The table actually contains ~50 columns, but I only included the relevant ones here.
Additional details:
The view does not become invalid daily, but it happens intermittently.
There are no known DDL operations on the table except regular ETL data loads.
The view becomes VALID again automatically when it is queried.
This is happening in a production environment, so we want to understand the root cause.
Questions:
What could cause a view to become INVALID intermittently without explicit DDL on the base table?
Could this be related to partition maintenance, statistics gathering, or constraint changes?
What system views or logs should we check to identify the root cause?
Any guidance on where to investigate would be greatly appreciated.
is Instances can exist without the database and database can exist without instance
Hello i just wanted to ask you a question. Can you please provide me some good online oracle books, tutorials or courses of the dba technologies like RMAN, Golden Gates, Exadata, Data Guard, Data pump and RAC? thanks.
I am normally using
"<code>SELECT DBMS_METADATA.GET_DDL('USER', 'User_Name') FROM DUAL;</code>"
to get the hashed password ( which I use to re-create the user as it was ), with SYSTEM user.
This unfortunately does not work for users which have password_versions = 10G ( I am using Oracle 19 but I think this happens with 12 as well )
The hashed password in that case is stored in a column of USER$ sys table that SYSTEM user is not allowed to see
However I observed that I can use export datapump to dump the user definition and then import datapump to get a sql file that has the hashed password, even with SYSTEM user ( but it is a long way ).
So how can SYSTEM user get the hashed password?
I would like a simpler way to get a script to re-create a user
Regards
Mauro
Well hello i just wanted to ask you when you have 100000000 rows of data and the best partitioning strategy is to use partition by range with subpartition by hash (having a column that is date type called hired and in the range we have YEAR(hired) and in the hash we have MONTH(hired)) how we will know the number of the partitions we will have to create in the table so we can have the best performance when we query data? thanks.If you don't understand my question i can provide the code if you ask me thanks.
Hi Tom,
I was learning Secure Application Roles and created an example to test it. Everything worked fine to actually create and enable the role, but I'm getting an error disabling the role (actively disabling it, not just letting the end of session do it).
First I'll paste a portion of the script output showing the error, and then I'll paste the .sql script itself that can be reproduced.
=== secure_role_example.txt ===
MYDBA@ORCL > create package body secure_role_pkg as
2 procedure enable_role is
3 begin
4 -- security check here
5 if 1 = 1 then
6 dbms_session.set_role('secure_role');
7 end if;
8 end;
9
10 procedure disable_role is
11 begin
12 dbms_session.set_role('all except secure_role');
13 end;
14 end;
15 /
Package body created.
MYDBA@ORCL > show errors
No errors.
MYDBA@ORCL >
MYDBA@ORCL > grant execute on secure_role_pkg to public;
Grant succeeded.
A@ORCL >
A@ORCL > exec mydba.secure_role_pkg.enable_role;
PL/SQL procedure successfully completed.
A@ORCL >
A@ORCL > select * from session_roles;
ROLE
------------------------------
SECURE_ROLE
A@ORCL >
A@ORCL > exec mydba.secure_role_pkg.disable_role;
BEGIN mydba.secure_role_pkg.disable_role; END;
*
ERROR at line 1:
ORA-01919: role 'SECURE_ROLE' does not exist
ORA-06512: at "SYS.DBMS_SESSION", line 124
ORA-06512: at "MYDBA.SECURE_ROLE_PKG", line 12
ORA-06512: at line 1
A@ORCL >
A@ORCL > select * from session_roles;
ROLE
------------------------------
SECURE_ROLE
=== secure_role_example.sql ===
-- secure_role_example.sql
-- Run this logged in as the mydba user, who has dba role.
-- This example creates a secure application role, which is a role that is
-- tied to and can only be set by a specific invokers rights package. This
-- allows you to procedurally enable a role for a user's session based on
-- criteria you define, and have that role contain all the privs needed to
-- execute a set of packages to run a particular application.
spool secure_role_example.txt;
set echo on;
connect mydba/orcl;
create role secure_role identified using mydba.secure_role_pkg;
create table secure_table (a int, b int);
create package secure_app as
procedure do_stuff;
procedure display_stuff;
end;
/
show errors
create package body secure_app as
procedure do_stuff is
begin
insert into secure_table values (1, 1);
commit;
end;
procedure display_stuff is
l_count number;
begin
select count(*) into l_count from secure_table;
dbms_output.put_line(l_count);
end;
end;
/
show errors
grant execute on secure_app to secure_role;
create package secure_role_pkg authid current_user as
procedure enable_role;
procedure disable_role;
end;
/
show...
Well hello i just wanted to ask you a question. Before 1.5 years i installed 23ai version and i downloaded sql developer. Before 1 month i opened my sql developer and i saw that my hr user is locked so i had to connect to sys user and then i pressed the following code ->
<code>ALTER SESSION SET CONTAINER = FREEPDB1;
ALTER USER hr ACCOUNT UNLOCK; -- or ALTER USER hr IDENTIFIED BY ** (password: hr) ACCOUNT UNLOCK; </code>
My question is from the time that i unlocked the user hr so i can connect again when the account will lock again? is there any query so i can see the remaining time that when is finished it will lock again the hr user? thanks.
Hello,
We have a Java process that calls OR stored procedure via JPA.
This procedure was initially declared outside of a package, and everything worked fine, but when we moved it into a package, we encountered date conversion problems related to the incorrectly initialized Oracle NLS_DATE_FORMAT variable.
When our call is made via a Windows SQL client, NLS_DATE_FORMAT has the value 'DD/MM/YYYY'.
However, when the call is made via Java Process, this variable has the value 'DD-MON-RR' => This causes problems in the procedure where date conversions are sometimes used without specifying the format, and Oracle then uses the NLS_DATE_FORMAT variable. This can lead to a TO_DATE(27/02/2026) operation when the session format is 'DD-MON-RR'... and therefore results in the Oracle error -1843 "not a valid month".
When the stored procedure was outside of a package, we forced this format at the beginning of our procedure with the command:
execute immediate 'ALTER SESSION SET NLS_DATE_FORMAT=''dd/mm/yyyy''';
But this doesn't work when the procedure is inside a package because it is apparently compiled and cached before the ALTER SESSION operation is performed...
The code is below:
<code>
CREATE OR REPLACE PACKAGE GRASE_WSDATEBUTOIR_PG is
/*
Traitement effectue par le package :
Appel procedure de recuperation date butoire pour ws sme avantage
--*/
--
-- C O N S T A N T E S P U B L I Q U E S
-- ============================================================================
P_CST_module CONSTANT STD_desc_PG.P_ST_module DEFAULT 'GRASE_WSDATEBUTOIR_PG';
P_CST_fonction_adm CONSTANT STD_desc_PG.P_ST_fonction_adm DEFAULT 'SERVICE';
P_CST_version CONSTANT STD_desc_PG.P_ST_version DEFAULT '26.2.0.01';
P_CST_version_date CONSTANT DATE DEFAULT '23/02/2026';
-- ============================================================================
--+Nom : proc_ws_datebutoir_pr
--+traitement : dans le cadre du ws sme avantage (creation montant)
--+Parametres : I_idpersonn IN co.graseuvp_pg.P_ST_identifiant_personne,
-- I_dtjour IN DATE,
-- I_dttraitement IN DATE,
--+Description : recupere la date butoire necessaire a la creation occ rrx1tmtavtg
-- ****************************************************************************
PROCEDURE ws_datebutoir_pr
(
I_idpersonn IN co.graseuvp_pg.P_ST_identifiant_personne,
I_cdsynretveu IN co.graseuvp_pg.P_ST_code_synthese,
I_termapayer IN co.graseuvp_pg.P_ST_code_terme_a_payer,
O_dtbutoir OUT co.graseuvp_pg.P_ST_date_butoire,
O_dtbutoir_gen OUT co.graseuvp_pg.P_ST_date_butoire,
O_dtbutoir_pts OUT co.graseuvp_pg.P_ST_date_butoire,
O_dtbutoir_cg OUT co.graseuvp_pg.P_ST_date_butoire,
O_code_retour OUT RRX1TERRPGM.coderetour%TYPE,
O_module OUT RRX1TERRPGM.module%TYPE,
O_errproc OUT RRX1TERRPGM.errproc%TYPE,
O_sqltra...
Pages

|

