

Feed aggregator
SQL macro with different table
user_tab_identity_cols.generation_type and BY DEFAULT ON NULL
Reducing SS contention with Local Temp Tablespace fails
M-Files didn’t fix your problem, your organization did.
Last week a wrote about the reasons why ECM projects fails.
M-Files is a wonderful tool and probably my favorite ECM, but it won’t solve your problem.
Companies that initiate digitalization projects like to convince themselves that investing in an ECM will solve all their problems: no more chaos, data loss, inefficiency, or lack of collaboration.

I’m sorry to break your dreams, but it won’t!
Tools AmplifySoftware like M-Files is powerful. No doubt about it.
It structures information, automates workflows, enables collaboration, and improves visibility. However, all of that depends on one thing:
What you put into it.
If your processes are unclear, M-Files will exacerbate the confusion.
Likewise, if your governance is weak, M-Files will amplify that weakness.
M-Files won’t magically make your teams start collaborating.
Tools don’t create discipline; they expose it, or the lack of it.
Think of M-Files less as a solution and more as a multiplier.
- Good processes become great.
- Broken processes break faster.
So why do organizations keep expecting tools to “fix everything”?
Because it’s easier.
Buying software seems like progress. It’s tangible, measurable and budgeted. It shows action.
On the other hand, fixing an organization requires:
- Alignment between teams
- Clear ownership
- Hard decisions on processes
- Cultural change
That’s messy, Political and Slow.
Instead, companies subconsciously shift the responsibility.
Once we have the tool, things will improve.
But what if they don’t?
They blame:
- The tool
- The implementation
- The users
Almost never the organization itself.
The Real Success FactorsWhen M-Files works really well, it’s never just about the tool.
It’s because a few key things were already in place or built alongside it.
Before digitizing anything, successful teams answer:
- What actually happens today?
- What should happen?
- Who is responsible at each step?
M-Files then becomes the execution layer, not the definition layer. It is not the job of M-Files to determine what should be done, but rather to ensure that the process is under control and follows organizational rules.
Ownership & AccountabilityEvery document, workflow, and decision needs an owner.
Without that:
- Workflows are stuck.
- Approvals take forever.
- Nobody feels responsible.
With it:
- M-Files flows naturally.
- Decisions are made faster.
- Accountability is visible.
Over-engineered systems fail.
The best M-Files setups are:
- Simple
- Intuitive
- Close to how people already work
Not “perfect.” Just usable and adopted.
Improving a work process is possible at any stage, but simplifying an existing one is challenging.
Change ManagementThe biggest challenge isn’t technical, it’s human.
People need to:
- Understand why things are changing
- Trust the system
- See personal value
Without that, even the best setup gets ignored.
Continuous ImprovementSuccessful organizations don’t “finish” their M-Files project.
They:
- Iterate
- Adjust workflows
- Refine metadata
- Listen to users
The system evolves with the business, which is the most important aspect, in my opinion, and one that is often overlooked.
Thinking differentlyThe real question is not: “What can M-Files do for us?”
Instead think: “Are we mature enough to successfully implement M-Files?”
It’s obviously not easy to answer that question, especially when you’re focused on your core business.
And that’s perfectly normal, that’s why we’re here to bridge the gap between software and the realities of business.
We’re not just here to install and configure systems; when we take on a digital transformation project, our primary role is to assess the organization’s readiness from an outside perspective, without passing judgment. Then we identify the necessary steps to reach the target.
To me, the real reward at the end of a project isn’t when the client says, “M-Files works well,” but when they say, “Thanks to M-Files, we’ve improved our collaboration and streamlined our interactions” and that makes a big difference.
L’article M-Files didn’t fix your problem, your organization did. est apparu en premier sur dbi Blog.
PostgreSQL 19: get_*_ddl functions
PostgreSQL already comes with plenty of system information functions to reconstruct the commands to create various objects, e.g. constraints or indexes. Starting with PostgreSQL 19 more functions will be available, namely those:
- pg_get_database_ddl
- pg_get_role_ddl
- pg_get_tablespace_ddl
As the names imply they can be used to recreate the commands to create a database, a role, or a tablespace.
To see what they do lets create a small setup:
postgres=# select version();
version
---------------------------------------------------------------------------------------
PostgreSQL 19devel dbi services build on x86_64-linux, compiled by gcc-15.1.1, 64-bit
(1 row)
postgres=# create user u with login password 'u';
CREATE ROLE
postgres=# \! mkdir /var/tmp/tbs
postgres=# create tablespace tbs location '/var/tmp/tbs' with ( random_page_cost = 1.1 );
CREATE TABLESPACE
postgres=# create database d with owner = u tablespace = tbs;
CREATE DATABASE
postgres=# alter database d connection limit = 10;
ALTER DATABASE
postgres=# \l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+-------------+-------------+-------------+-----------+-----------------------
d | u | UTF8 | icu | en_US.UTF-8 | en_US.UTF-8 | en-US-x-icu | |
postgres | postgres | UTF8 | icu | en_US.UTF-8 | en_US.UTF-8 | en-US-x-icu | |
template0 | postgres | UTF8 | icu | en_US.UTF-8 | en_US.UTF-8 | en-US-x-icu | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | icu | en_US.UTF-8 | en_US.UTF-8 | en-US-x-icu | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(4 rows)
To get the commands to recreate that database the new function “pg_get_database_ddl” can be used:
postgres=# select * from pg_get_database_ddl ( 'd'::regdatabase );
pg_get_database_ddl
---------------------------------------------------------------------------------------------------------------------------------------------------------
CREATE DATABASE d WITH TEMPLATE = template0 ENCODING = 'UTF8' LOCALE_PROVIDER = icu LOCALE = 'en_US.UTF-8' ICU_LOCALE = 'en-US-x-icu' TABLESPACE = tbs;
ALTER DATABASE d OWNER TO u;
ALTER DATABASE d CONNECTION LIMIT = 10;
(3 rows)
There are some options to control the output format and what gets reconstructed, e.g.:
postgres=# select * from pg_get_database_ddl ( 'd'::regdatabase, 'pretty', 'true' );
pg_get_database_ddl
-----------------------------------------
CREATE DATABASE d +
WITH TEMPLATE = template0 +
ENCODING = 'UTF8' +
LOCALE_PROVIDER = icu +
LOCALE = 'en_US.UTF-8' +
ICU_LOCALE = 'en-US-x-icu' +
TABLESPACE = tbs;
ALTER DATABASE d OWNER TO u;
ALTER DATABASE d CONNECTION LIMIT = 10;
(3 rows)
postgres=# select * from pg_get_database_ddl ( 'd'::regdatabase, 'pretty', 'true', 'owner', 'false' );
pg_get_database_ddl
-----------------------------------------
CREATE DATABASE d +
WITH TEMPLATE = template0 +
ENCODING = 'UTF8' +
LOCALE_PROVIDER = icu +
LOCALE = 'en_US.UTF-8' +
ICU_LOCALE = 'en-US-x-icu' +
TABLESPACE = tbs;
ALTER DATABASE d CONNECTION LIMIT = 10;
(2 rows)
postgres=# select * from pg_get_database_ddl ( 'd'::regdatabase, 'pretty', 'true', 'owner', 'false', 'tablespace', 'false' );
pg_get_database_ddl
-----------------------------------------
CREATE DATABASE d +
WITH TEMPLATE = template0 +
ENCODING = 'UTF8' +
LOCALE_PROVIDER = icu +
LOCALE = 'en_US.UTF-8' +
ICU_LOCALE = 'en-US-x-icu';
ALTER DATABASE d CONNECTION LIMIT = 10;
(2 rows)
The other two functions behave the same (but do not have exactly the same options):
postgres=# select * from pg_get_tablespace_ddl('tbs');
pg_get_tablespace_ddl
---------------------------------------------------------------
CREATE TABLESPACE tbs OWNER postgres LOCATION '/var/tmp/tbs';
ALTER TABLESPACE tbs SET (random_page_cost='1.1');
(2 rows)
postgres=# select * from pg_get_tablespace_ddl('tbs', 'pretty', 'true');
pg_get_tablespace_ddl
----------------------------------------------------
CREATE TABLESPACE tbs +
OWNER postgres +
LOCATION '/var/tmp/tbs';
ALTER TABLESPACE tbs SET (random_page_cost='1.1');
(2 rows)
postgres=# select * from pg_get_tablespace_ddl('tbs', 'pretty', 'true', 'owner', 'false');
pg_get_tablespace_ddl
----------------------------------------------------
CREATE TABLESPACE tbs +
LOCATION '/var/tmp/tbs';
ALTER TABLESPACE tbs SET (random_page_cost='1.1');
(2 rows)
… and finally for the roles:
postgres=# select * from pg_get_role_ddl ('u');
pg_get_role_ddl
--------------------------------------------------------------------------------------------
CREATE ROLE u NOSUPERUSER INHERIT NOCREATEROLE NOCREATEDB LOGIN NOREPLICATION NOBYPASSRLS;
(1 row)
postgres=# select * from pg_get_role_ddl ('u', 'pretty', 'true');
pg_get_role_ddl
-------------------
CREATE ROLE u +
NOSUPERUSER +
INHERIT +
NOCREATEROLE +
NOCREATEDB +
LOGIN +
NOREPLICATION+
NOBYPASSRLS;
(1 row)
postgres=# select * from pg_get_role_ddl ('u', 'pretty', 'true', 'memberships', 'false');
pg_get_role_ddl
-------------------
CREATE ROLE u +
NOSUPERUSER +
INHERIT +
NOCREATEROLE +
NOCREATEDB +
LOGIN +
NOREPLICATION+
NOBYPASSRLS;
(1 row)
Nice, and again: Thanks to all involved.
L’article PostgreSQL 19: get_*_ddl functions est apparu en premier sur dbi Blog.
PostgreSQL 19: json format for “copy to”
PostgreSQL already has impressive support for working with data in json format. If you look at the jsonb data type and all the built-in functions and operators you can use, there is so much you can do with it by default. Starting with PostgreSQL 19 there is one feature more when it comes to working with data in json format.
“COPY” already is quite powerful and the fastest way to get data in and out of PostgreSQL (you may read some previous posts about copy here, here, and here).
As usual lets start with a simple table:
postgres=# create table t ( a int primary key, b text );
CREATE TABLE
postgres=# insert into t select i, md5(i::text) from generate_series(1,1000000) i;
INSERT 0 1000000
To get that data out in text format you might simply do this:
postgres=# copy t to '/var/tmp/t';
COPY 1000000
postgres=# \! head /var/tmp/t
1 c4ca4238a0b923820dcc509a6f75849b
2 c81e728d9d4c2f636f067f89cc14862c
3 eccbc87e4b5ce2fe28308fd9f2a7baf3
4 a87ff679a2f3e71d9181a67b7542122c
5 e4da3b7fbbce2345d7772b0674a318d5
6 1679091c5a880faf6fb5e6087eb1b2dc
7 8f14e45fceea167a5a36dedd4bea2543
8 c9f0f895fb98ab9159f51fd0297e236d
9 45c48cce2e2d7fbdea1afc51c7c6ad26
10 d3d9446802a44259755d38e6d163e820
Starting with PostgreSQL 19 you can do the same in json format:
postgres=# copy t to '/var/tmp/t1' with (format json);
COPY 1000000
postgres=# \! head /var/tmp/t1
{"a":1,"b":"c4ca4238a0b923820dcc509a6f75849b"}
{"a":2,"b":"c81e728d9d4c2f636f067f89cc14862c"}
{"a":3,"b":"eccbc87e4b5ce2fe28308fd9f2a7baf3"}
{"a":4,"b":"a87ff679a2f3e71d9181a67b7542122c"}
{"a":5,"b":"e4da3b7fbbce2345d7772b0674a318d5"}
{"a":6,"b":"1679091c5a880faf6fb5e6087eb1b2dc"}
{"a":7,"b":"8f14e45fceea167a5a36dedd4bea2543"}
{"a":8,"b":"c9f0f895fb98ab9159f51fd0297e236d"}
{"a":9,"b":"45c48cce2e2d7fbdea1afc51c7c6ad26"}
{"a":10,"b":"d3d9446802a44259755d38e6d163e820"}
Specifying a SQL is also supported:
postgres=# copy (select a from t) to '/var/tmp/t1' with (format json);
COPY 1000000
postgres=# \! head /var/tmp/t1
{"a":1}
{"a":2}
{"a":3}
{"a":4}
{"a":5}
{"a":6}
{"a":7}
{"a":8}
{"a":9}
{"a":10}
As noted in the commit message there are some options which are not compatible with the json format:
- HEADER
- DEFAULT
- NULL
- DELIMITER
- FORCE QUOTE
- FORCE NOT NULL
- and FORCE NULL
Also not supported (currently) is “copy from”.
L’article PostgreSQL 19: json format for “copy to” est apparu en premier sur dbi Blog.
OGG-30007 : How To Register Certificates In GoldenGate ?
After working on a GoldenGate deployment recently, I felt that the OGG-30007 error would be worth writing about. This error happens when registering certificates in GoldenGate. Whether you do it from the web UI or with the REST API, this GoldenGate error is detailed as such:
Processing of the certificate PEM portion of the certificate bundle resulted in more than one (1) certificate objects.
Code: OGG-30007
Cause: The read and decode processing of the specified portion of the certificate bundle produced more than one (1) objects. More than one PEM encoded object is present in the data.
Action: Review the specified portion of the certificate bundle and correct as needed. Only a single PEM encoded object is expected.This error occurs because GoldenGate expects exactly one PEM object per import, while a certificate chain file contains multiple certificates. In the web UI, a pop-up will alert you that something is wrong:
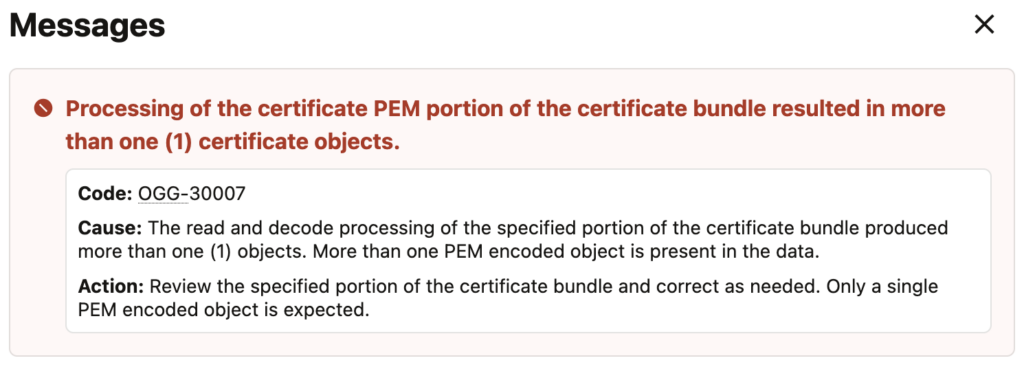
As mentioned, this typically happens when registering a certificate chain. For instance, you could face the issue when connecting two deployments secured with NGINX. The server presents a certificate chain including the intermediate, while the client (GoldenGate) must trust both the root and the intermediate.
But when the Certificate Authority doesn’t sign your certificate directly with the Root Certificate, but with an Intermediate Certificate, the server presents a certificate chain including the intermediate. A certificate like the following will generate an OGG-30007 error if you try to add it to the truststore:
-----BEGIN CERTIFICATE-----
(intermediate)
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
(root)
-----END CERTIFICATE-----And to make sure that your connections work, you should not only add the root certificate, but also the intermediate certificate. Because of the way GoldenGate stores these certificates, two separate entries must be created in the truststore. To ease monitoring and certificate management, you can name them rootCA_ogg_target and intermediateCA_ogg_target

With this, you should have no problem connecting GoldenGate deployments ! To avoid OGG-30007, ensure that each certificate is imported separately. In practice, this means extracting the root and intermediate certificates from the chain file and registering them as individual entries in the GoldenGate truststore.
L’article OGG-30007 : How To Register Certificates In GoldenGate ? est apparu en premier sur dbi Blog.
PostgreSQL 19: The “repack” command
Before PostgreSQL 19 you had two commands to completely rewrite a table: Either you can use the “vacuum full” or the “cluster” command to achieve this. Both operations are blocking and the table cannot be used until those operations complete. This can easily be verified with the following simple test cases:
-- session 1
postgres=# create table t ( a int primary key, b text );
CREATE TABLE
postgres=# insert into t select i, md5(i::text) from generate_series(1,10000000) i;
INSERT 0 1000000
postgres=# vacuum full t;
-- session 2
postgres=# select count(*) from t; -- this blocks until vacuum full completes
The same is true for the “cluster” command:
-- session 1
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
Indexes:
"t_pkey" PRIMARY KEY, btree (a)
postgres=# cluster t using t_pkey;
-- session 2
postgres=# select count(*) from t; -- this blocks until clustering completes
Starting with PostgreSQL 19 (scheduled to be released later this year) these two functionalities are combined into the “repack” command. The commit message makes the reason behind this pretty clear:
Introduce the REPACK command
REPACK absorbs the functionality of VACUUM FULL and CLUSTER in a single
command. Because this functionality is completely different from
regular VACUUM, having it separate from VACUUM makes it easier for users
to understand; as for CLUSTER, the term is heavily overloaded in the
IT world and even in Postgres itself, so it's good that we can avoid it.
We retain those older commands, but de-emphasize them in the
documentation, in favor of REPACK; the difference between VACUUM FULL
and CLUSTER (namely, the fact that tuples are written in a specific
ordering) is neatly absorbed as two different modes of REPACK.
This allows us to introduce further functionality in the future that
works regardless of whether an ordering is being applied, such as (and
especially) a concurrent mode.
So, instead of spreading the functionality over two commands, there is a new command which combines both:
postgres=# \h repack
Command: REPACK
Description: rewrite a table to reclaim disk space
Syntax:
REPACK [ ( option [, ...] ) ] [ table_and_columns [ USING INDEX [ index_name ] ] ]
REPACK [ ( option [, ...] ) ] USING INDEX
where option can be one of:
VERBOSE [ boolean ]
ANALYZE [ boolean ]
CONCURRENTLY [ boolean ]
and table_and_columns is:
table_name [ ( column_name [, ...] ) ]
URL: https://www.postgresql.org/docs/devel/sql-repack.html
The really cool stuff about this is, that this can be run concurrently which means the table is not locked for others while the command is doing its work:
-- session 1
postgres=# repack (concurrently) t;
-- or
postgres=# repack (concurrently) t using index t_pkey;
-- session 2
postgres=# select count(*) from t; -- not blocking
Nice, thanks to all involved.
L’article PostgreSQL 19: The “repack” command est apparu en premier sur dbi Blog.
Retirement Planning
https://www.irs.gov/filing/federal-income-tax-rates-and-brackets

What is the % difference for 12% vs 22% ???
The goal is to stay below 22% bracket.
Roth IRA is TAX FREE!
Traditional IRA is TAX DEFER.
Plan accordingly.
Anyone Still Read My Blog?
Been out of tech for some times after layoff.
3 wks vacations to Asia a yr.
What R MAN?
TaxAct Software/Support 2025 Is CRAP!!!
I KNOW TAXES. Retired from HR Block after 19yrs.
IRS simplify the process and TaxAct made it convoluted!!!
So how does IRS knows the purchase price? The don’t !!!
So if purchase at 14$ I can put $ 20 for lower Capital Gains Tax?
NO! NO! NO! That is FRAULD !!!
Before, ONLY THE PROCEEDS were reported to IRS!
Now, proceeds and sales are reported to IRS.
This makes it easier to file taxes and harder to cheat.
TaxAct software and technical support were clueles
FINALLY
Your Requested 2025 TaxAct E-file Notice: Federal Return Accepted
Your Requested 2025 TaxAct E-file Notice: California Return Accepted
Why ECM Projects fail (even with good tools)
Today, I would like to take a step back and think about failure, because it’s part of life and sometimes things don’t go as planned. Analyzing failures can help to prevent them from happening again.

Firstly, in most cases, your ECM project did not fail because of the tool!
That’s the uncomfortable truth
It wasn’t because the platform was bad.
It wasn’t because the features were missing.
It wasn’t even because users ‘resisted change’.
And yet, the project still underdelivered. Or worse, it quietly failed.
After years of working on ECM implementations, I have seen the same pattern emerge time and time again: Good tools. Smart people. Disappointing results.
So what’s really going wrong?
The illusion of the “Right Tool”Let’s start with the most common misconception:
If we choose the right ECM solution, everything else will fall into place.
It won’t.
Modern ECM platforms are powerful. They can manage documents, automate workflows, enforce governance and integrate with almost anything.
But here’s the reality, A tool can’t fix a broken organization. It exposes it.
- If your processes are unclear, the system will amplify the confusion.
- If ownership is undefined, governance will collapse.
- If users don’t see the value, adoption will stall.
The tool is not the problem. It’s a mirror.
Business and IT are not solving the same problemMost ECM projects start with a misalignment that no one explicitly addresses.
IT is thinking:
- architecture
- security
- scalability
The business is thinking:
- “Where is my document?”
- “Why is this so slow?”
- “Why do I have to click 12 times?”
Both are valid. But they are not the same problem.
So what happens?
You get:
- technically solid systems
- that don’t solve day-to-day frustrations
And users disengage, not because they’re resistant, but because the system doesn’t help them.
Over-engineering everythingThis is an incredibly common issue.
In the name of ‘doing things properly’, projects end up with overly complex metadata models.
- overly complex metadata models
- workflows for every edge case
- validation rules everywhere.
On paper, this looks impressive.
In reality, the system becomes fragile, slow and difficult to use.
Complexity is often mistaken for maturity. In ECM, complexity is usually the fastest way to kill off adoption.
Governance that exists only in slidesEvery project has governance.
Or at least, a document describing it:
- Naming conventions
- Validation rules
- Lifecycle definitions
Everything is defined and then… ignored.
Because:
- no one owns it
- no one enforces it
- no one adapts it
It looks good during the project, but it disappears in real life.
The “Quick Win” trapQuick wins are supposed to build momentum and it’s true, however they often create long-term problems.
Why? Because they:
- bypass proper design
- introduce shortcuts
- create inconsistencies
And what about those “temporary” solutions? They never get fixed.
Months later, the system becomes:
- inconsistent
- hard to maintain
- confusing for users
You haven’t gained any speed. You just made things more complicated.
Quick wins are essential for driving user adoption, but this must be taken into account when designing the project as a whole. Consider the pros and cons, but do not compromise on the project’s overall quality.
No one owns the system after Go-liveThis is where many projects quietly fail.
Once the system is live:
- the project team disappears
- IT moves to other priorities
- the business assumes “it’s done”
ECM is not a one-time project. It’s a living system.
Without ownership:
- governance degrades
- usage diverges
- value decreases over time
And nobody reacts until it’s too late.
What actually worksHaving seen what fails, the question becomes:
What makes an ECM project succeed?
Not perfectly. But sustainably.
From my experience, here’s what consistently makes the difference:
Start with real user problemsNot features. Not architecture.
Ask:
- Where do people lose time?
- What frustrates them daily?
Solve that first.
Keep it simpler than you think- Fewer metadata fields
- Fewer workflows
- Clearer rules
You can always add complexity later, but it’s rare that you can remove it.
Make ownership explicitSomeone must:
- own the system
- enforce governance
- evolve the platform
No owner = slow decay
Design for reality, not theoryPeople will:
- take shortcuts
- ignore rules
- prioritize speed
During the design phase keep that in mind.
Treat ECM as a product, not a projectProjects end, but Products evolve.
To create long-term value, you need:
- continuous improvement
- feedback loops
- adaptation.
When I started working in ECM, data was made up of static documents with few or no relationships between them. Now, we have various types of content, such as pictures and videos, as well as more interaction and workflows. Therefore, what is suitable now might not be in two or three years.
Final ThoughtIn conclusion, most ECM projects don’t fail spectacularly. They fail quietly.
Users stop using advanced features, workarounds appear and value slowly erodes.
Eventually, people say:
The system is not that useful.
Not because the tool was bad. It’s because the project misunderstood what success actually looks like.
A good ECM system is not necessarily the one with the most or the trendiest features. Rather, it’s the one that people actually use because it simplifies their work.
As a result, the tool itself is not as important as you might expect. Of course, some are more relevant than others depending on the case. That is why, at dbi services, we support several of them.
The real key to the success of an ECM project lies in its management and long-term vision.
L’article Why ECM Projects fail (even with good tools) est apparu en premier sur dbi Blog.
Overcome GoldenGate 26ai Bug On Custom Profiles
In GoldenGate, processes have a few options that can be managed to fit your needs. When creating an extract, for instance, you can act on the following parameters:
autoStart.enabled: whether the process will start automatically after the Administration Server starts.autoStart.delay: delay in seconds before starting the process.autoRestart.enabled: whether to restart the process after it fails.autoRestart.onSuccess: the process is only restarted if it fails.autoRestart.delay: waiting time (in seconds) before attempting to restart a process once it fails.autoRestart.retries: maximum number of retries before stopping restart attempts.autoRestart.window: timeframe before GoldenGate will attempt to restart the process again.autoRestart.disableOnFailure: if set to True, GoldenGate will disable the restart if it fails to restart within theretries/windowsetting. You will have to start the process manually if this happens.
In the web UI, an extract profile can be customized during the third step of an extract creation called Managed Options. Here, you can choose to use the default profile, a user-defined profile or custom settings specific to the new process.
However, a bug was introduced in GoldenGate 26ai. If you create a custom profile with the adminclient, the web UI will sometimes hang when creating any new extract or replicat. This also affects 23ai installations that are patched to 26ai, so be very careful when patching an existing GoldenGate 23ai setup containing custom profiles ! After patching, you will not be able to access and manage your profiles anymore from the web UI.
To reproduce the bug, simply create an extract from the adminclient.
OGG (https://vmogg ogg_test_01) 1> info profile *
Auto Delay Auto Wait Reset Disable
Name Start Seconds Restart Retries Seconds Seconds on Failure
-------------------------------- ----- -------- ------- -------- -------- -------- ----------
Default No No
OGG (https://vmogg ogg_test_01) 2> add profile TestProfile autostart no
OGG (https://vmogg ogg_test_01) 3> info profile *
Auto Delay Auto Wait Reset Disable
Name Start Seconds Restart Retries Seconds Seconds on Failure
-------------------------------- ----- -------- ------- -------- -------- -------- ----------
Default No No
TestProfile No NoIn a GoldenGate 23ai web UI, you will see the following when creating an extract, in the Managed Options step:
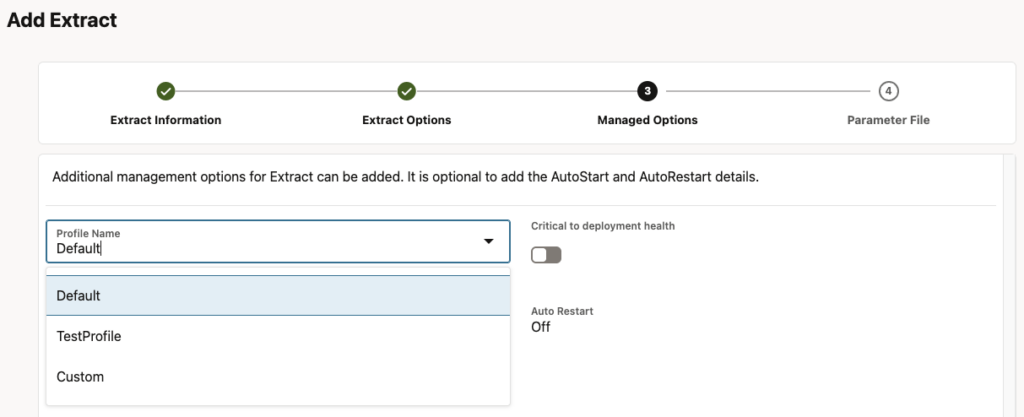
However, in GoldenGate 26ai, the extract creation hangs indefinitely, and no error gets reported.
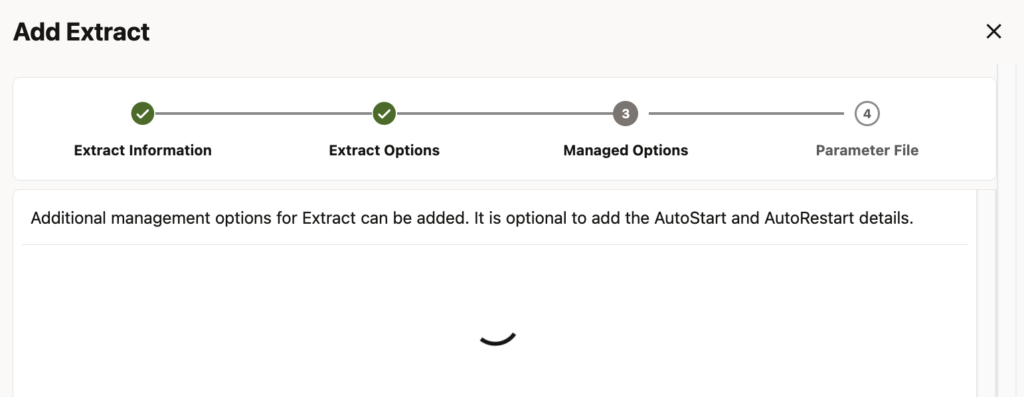
Before the bug is solved by Oracle, what can you do ? The first thing you can do is modify the Default GoldenGate profile, so that all extracts with this profile are affected. However, it means that you cannot fine-tune the settings for different processes, with different needs. After all, it is the reason why you should define profiles in the first place.
But if you still want to overcome this bug and having working profiles on 26ai until the bug gets corrected, you have two ways of doing this:
- Create profiles from the web UI. You can do this in the Managed Process Profiles tab of your deployment. Profiles created through this tab do not make the web UI hang indefinitely.
- Create profiles with the REST API. As presented in this blog, you can do this in two steps :
- Creation of a new profile with the Create Configuration Value endpoint on the
ogg:managedProcessSettingstype. - Creation of a new configuration
isDefaultset toFalseon theogg:configDataDescriptiontype.
- Creation of a new profile with the Create Configuration Value endpoint on the
This way, you can create or recreate your profiles until the bug is solved.
L’article Overcome GoldenGate 26ai Bug On Custom Profiles est apparu en premier sur dbi Blog.
Using Oracle SQLcl Project to deploy multiple schemas to environments with different schema names
DBMS_DEBUG_JDWP
DBMS_REDEFINITION generates ORA-42000 when using col_mapping and part_name
Splitting table into chunks for load doesn't work on partitioned table
Scaling SSRS Migrations: Multi-Threaded Automation for PBIRS 2025
Modernizing a reporting platform is a pivotal milestone for any BI infrastructure. Whether it’s a standard upgrade or a forced transition to Power BI Report Server (PBIRS) following the decommissioning of SSRS in SQL Server 2025, the operation is critical. For the purposes of our lab, we will use an SSRS 2017 source, but the logic remains universal: regardless of the original version, the goal is to ensure the continuity of your decision-making services without sacrificing your mental health in the process.
As my colleague Amine Haloui explained in a recent blog post, several strategies exist for migrating an instance. The “Lift and Shift” method (restoring the ReportServer database onto a new instance) is often the most attractive on paper. However, the reality on the ground can be more temperamental.
In some production environments, the target PBIRS instance already exists, hosts its own content, or follows specific configurations that prohibit simply overwriting its underlying ReportServer database. Therefore, we are proceeding here on the premise of a selective and granular migration: we must inject the SSRS catalog into an active PBIRS environment without burning everything to the ground in the process.
When faced with inventories exceeding hundreds or even thousands of reports (RDL), folders, and datasources, a manual approach via the web interface is not an option and automation becomes a necessity.
This article analyzes a systematic approach based on the ReportingServicesTools PowerShell module. The objective is to provide a robust methodology to extract your catalog and redeploy it intelligently, while managing the necessary reconfigurations along the way.
To migrate cleanly, objects must first be isolated. The idea is not to blindly vacuum everything, but to target the critical folders of your SSRS instance and transform them into flat files (.rdl and .rds) within a local staging area. If your SSRS instance contains specific object types, the scripts can easily be adapted to include them as well.
This is where the power of the SOAP Proxy comes into play. Rather than multiplying slow HTTP calls, we use the native service interface to list and extract our components:
$sourceUrl = "http://your-ssrs-server/ReportServer"
$exportRoot = "H:\Migration_Dump"
$proxySource = New-RsWebServiceProxy -ReportServerUri $sourceUrl
In a production environment, SSRS folders are often a messy mix of reports, data sources, images, and sometimes obsolete semantic models. To maintain total control over what we export, we isolate the filtering logic.
This Get-AllItemsByType function allows us to retrieve only what truly matters to us, based on the TypeName and file extension returned by the API.
function Get-AllItemsByType {
param(
[string]$CurrentPath,
$Proxy,
[string]$TypeName
)
try {
return $Proxy.ListChildren($CurrentPath, $true) | Where-Object { $_.TypeName -eq $TypeName }
} catch {
Write-Host " [!] Error on $CurrentPath : $($_.Exception.Message)" -ForegroundColor Red
return $null
}
}
This mapping between the file type and its extension must be defined upfront in a dictionary:
$extensionMap = @{
"Report" = ".rdl"
"DataSource" = ".rds"
}
A crucial point in extracting SSRS objects is preserving their context. To ensure a seamless import into PBIRS 2025, we must recreate the exact folder hierarchy of the source server locally.
The trick lies in transforming the SSRS path (formatted as /Folder/SubFolder/Report) into a valid Windows path, while simultaneously handling the extension mapping (.rdl for reports, .rds for DataSources).
function Export-SsrsItems {
param(
[string]$RootPath,
$Proxy,
[string]$TypeName,
[string]$ExportRoot
)
$items = Get-AllItemsByType -CurrentPath $RootPath -Proxy $Proxy -TypeName $TypeName
foreach ($item in $items) {
$relativeItemPath = $item.Path.TrimStart('/').Replace("/", "\")
$localFilePath = Join-Path $ExportRoot $relativeItemPath
$localDirectory = Split-Path -Path $localFilePath -Parent
if (-not (Test-Path $localDirectory)) {
New-Item -ItemType Directory -Path $localDirectory -Force | Out-Null
}
Out-RsCatalogItem -Path $item.Path -Destination $localDirectory -Proxy $Proxy
}
}
By doing this, your H:\Migration_Dump becomes the exact mirror of your SSRS portal. This structural rigor is what will allow us, in the next step, to remap our data sources without having to hunt down which report belongs to which department.
Finally, we define the folders we wish to export along with the document types they contain (since a migration is often the perfect time for a bit of spring cleaning):
$exportTasks = @(
@{ Path = "/Migration_Source_2"; Types = @("Report") },
@{ Path = "/Data Sources"; Types = @("DataSource") }
)
Write-Host "--- Selective Export Started ---" -ForegroundColor Cyan
foreach ($task in $exportTasks) {
foreach ($typeName in $task.Types) {
$ext = $extensionMap[$typeName]
Export-SsrsItems `
-RootPath $task.Path `
-Proxy $proxySource `
-TypeName $typeName `
-Extension $ext `
-ExportRoot $exportRoot
}
}
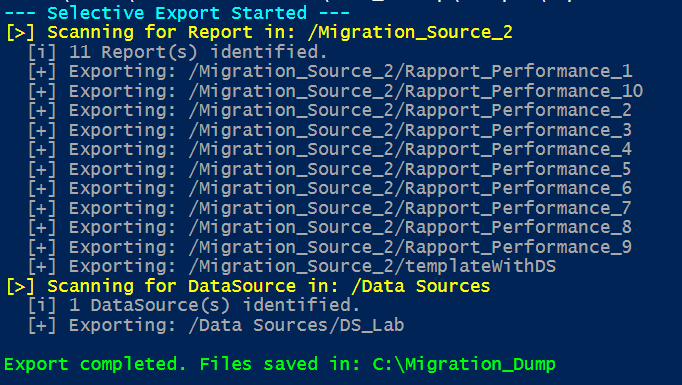
Once the extraction is complete, you have a local mirror of your source instance, but the data sources still point to the legacy infrastructure.
Instead of manually fixing each connection after the import (the best way to miss half of them), we will apply an automated transformation directly to our local XML files. This allows us to update connection strings in bulk before a single report even hits the target server.
The idea is simple: use PowerShell to inject the new SQL instance wherever necessary, ensuring a functional deployment from the very first second:
$allDataSources = Get-ChildItem -Path $exportRoot -Filter "*.rds" -Recurse
Write-Host "[>] Datasources updated in : $exportRoot" -ForegroundColor Yellow
foreach ($dsFile in $allDataSources) {
[xml]$xmlContent = Get-Content $dsFile.FullName
$node = $xmlContent.SelectSingleNode("//ConnectString")
if ($null -ne $node) {
$oldValue = $node."#text"
if ($null -eq $oldValue) { $oldValue = $node.InnerText }
$newValue = $oldValue -replace "OLD_REPORTING_INSTANCE", "NEW_REPORTING_INSTANCE"
if ($oldValue -ne $newValue) {
$node.InnerText = $newValue
$xmlContent.Save($dsFile.FullName)
Write-Host " [v] ConnectString updated in : $($dsFile.Name)" -ForegroundColor Green
}
} else {
Write-Host " [!] ConnectString not found in file $($dsFile.Name)" -ForegroundColor Red
}
}
Moreover, since we are interacting directly with the file’s XML structure, this logic isn’t limited to connection strings: you can apply the same principle to automate changes for any XML property, from timeouts to provider names.
Phase 3: Mass Deployment – Rebuilding the Reporting PortalAt this stage, the operation is purely mechanical. We once again leverage the ReportingServicesTools module to recreate the folder structure and upload the .rds and .rdl files. By following this specific order, PBIRS will automatically restore the links between your reports and their newly patched data sources.
It is worth noting that the script allows for importing into a specific root folder (defined by the $destroot variable). This is particularly useful if you want to isolate the migrated assets into a dedicated directory, such as SSRS_Folder to keep them distinct from the existing hierarchy. Furthermore, this script is designed with safety in mind: it cannot overwrite or delete anything. If a report with the same name already exists in the same location, the -Overwrite:$false argument prevents replacement, ensuring that the import process never destroys existing content.
Here is the final block to complete your migration:
$destUrl = "http://your-pbirs-server/ReportServer"
$localDump = "H:\Migration_Dump"
$destRoot = "/" #Start import in the root folder
$proxyDest = New-RsWebServiceProxy -ReportServerUri $destUrl
$extensionMap = @{
"Report" = ".rdl"
"DataSource" = ".rds"
}
function Ensure-RsFolderBruteForce {
param($fullFolderPath, $Proxy)
$parts = $fullFolderPath.Split('/') | Where-Object { $_ -ne '' }
$currentPath = ''
foreach ($part in $parts) {
$parent = if ($currentPath -eq '') { "/" } else { $currentPath }
$target = if ($currentPath -eq '') { "/$part" } else { "$currentPath/$part" }
try {
$Proxy.CreateFolder($part, $parent, $null) | Out-Null
Write-Host " [DIR] Created : $target" -ForegroundColor Cyan
} catch {
if ($_.Exception.Message -match "AlreadyExists") {
# Folder already exists but we continue
} else {
Write-Host " [!] Error for folder $target : $($_.Exception.Message)" -ForegroundColor Red
}
}
$currentPath = $target
}
}
function Import-SsrsItem {
param(
[System.IO.FileInfo]$File,
[string]$LocalDump,
[string]$DestRoot,
$Proxy
)
$relativeDir = $File.DirectoryName.Replace($LocalDump, '').Replace("\", "/")
$targetFolderPath = ($DestRoot + $relativeDir).Replace("//", "/")
$fullItemPath = ($targetFolderPath + "/" + $File.BaseName).Replace("//", "/")
Ensure-RsFolderBruteForce -fullFolderPath $targetFolderPath -Proxy $Proxy
try {
Write-RsCatalogItem -Path $File.FullName -Destination $targetFolderPath -Proxy $Proxy -Overwrite:$false
Write-Host " [DONE] Imported: $fullItemPath" -ForegroundColor Green
}
catch {
if ($_.Exception.Message -match "already exists") {
Write-Host " [SKIP] Already created : $fullItemPath" -ForegroundColor Gray
} else {
Write-Host " [FAIL] Error $fullItemPath : $($_.Exception.Message)" -ForegroundColor Red
}
}
}
$importOrder = @("DataSource", "Report")
foreach ($typeName in $importOrder) {
$extension = $extensionMap[$typeName]
Write-Host "`n[PASS] Import of object with type : $typeName ($extension)" -ForegroundColor Magenta
$filesToImport = Get-ChildItem -Path $localDump -Filter "*$extension" -Recurse
if ($filesToImport.Count -eq 0) {
Write-Host " [i] No file with $extension found." -ForegroundColor Gray
continue
}
foreach ($file in $filesToImport) {
Import-SsrsItem -File $file -LocalDump $localDump -DestRoot $destRoot -Proxy $proxyDest
}
}
Write-Host "`nImport done!" -ForegroundColor Green
Importing via SOAP is more resource-intensive than extraction, as the server must validate every piece of metadata and physically recreate the path for each report. On large volumes, this stage can become a bottleneck (averaging ~1 second per report).
To overcome this, we can parallelize the import by folder, creating multiple background jobs running on separate threads. Here is the general skeleton to implement this multi-threaded approach:
$maxJobs = 5
foreach ($file in $filesToImport) {
while ((Get-Job -State Running).Count -ge $maxJobs) {
Start-Sleep -Milliseconds 500
}
Start-Job -Name "Import_$($file.Name)" -ScriptBlock {
param($f, $url, $targetPath)
$Proxy = New-RsWebServiceProxy -ReportServerUri $url
try {
Write-RsCatalogItem -Path $f.FullName -Destination $targetPath -Proxy $Proxy -Overwrite:$false
return "SUCCESS: $($f.Name)"
} catch {
return "ERROR: $($f.Name) -> $($_.Exception.Message)"
}
} -ArgumentList $file, $destUrl, $targetFolderPath
}
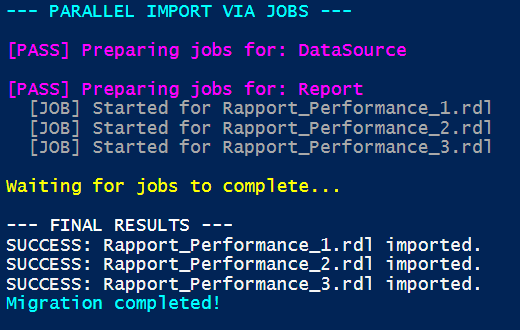
Note : The -Parallel parameter is a feature of the ForEach-Object cmdlet introduced in PowerShell 7 to enable native multi-threading. While it allows for processing multiple objects simultaneously, it is not reliably supported by the ReportingServicesTools library as the underlying API is not thread-safe. To ensure stability and avoid session collisions, it is recommended to use the Start-Job method instead, as it provides better process isolation for each task.
Migrating to Power BI Report Server shouldn’t be a manual challenge. By adopting this PowerShell-driven ETL approach, you replace the uncertainty of manual intervention with industrial-grade rigor.
The primary advantage lies in consistency: regardless of the report volume or folder complexity, the script guarantees an identical and predictable result every single time. By isolating extraction, XML transformation, and ordered importation, you maintain total control over your data integrity.
Ultimately, automation is about securing your delivery and freeing up time for what truly matters: leveraging your data on your brand-new PBIRS 2025 platform.
Happy migrating!
L’article Scaling SSRS Migrations: Multi-Threaded Automation for PBIRS 2025 est apparu en premier sur dbi Blog.
LLM Generates Summary of Detailed Report
DBAs spend a lot of time reviewing reports about the health of their databases. I’ve used an LLM to speed up that process.
I took a daily report about our Oracle databases and used an LLM to generate a short summary that lets a DBA immediately see which databases need attention.
A typical report looks like this for each database:
The full report has over 2,000 lines that must be manually scanned by the on-call DBA each day.
The LLM-generated summary looks like this:
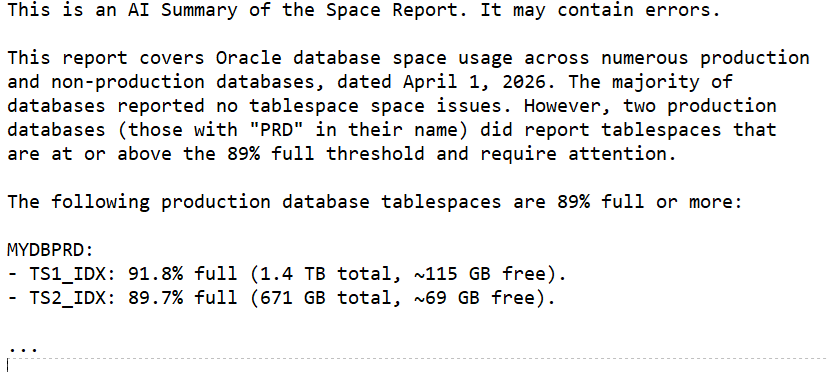
This summary immediately shows which databases need attention. We still manually scan the entire report but having the summary in the body of the email (with the full report attached) lets us see at a quick glance what needs attention and how urgent it is. The summary does not replace the full report; it only highlights the items that are most likely to be important. In our environment we chose 89% full as the point where we start reporting on space issues.
I’m using AWS Bedrock with the Claude Sonnet 4.6 model. Here is the Python
function that sends the combined prompt and report to Bedrock and returns the summary:
Here is the prompt that preceeds the report:

This simple use of an LLM has saved me time by putting a quick summary in the email body while preserving the full report for detailed review.
Bobby