

Feed aggregator
Oracle.DataAccess.Client.OracleException ORA-03135: connection lost contact
With Oracle EBR, creating DML triggers when foreign keys are present
Connection lost with ORA-01335 with ODA server
Database DDL trigger
User Defined Extensions in SQLDeveloper Classic – something you can’t do in VSCode (yet)
I can tell you from personal experience that, when you reach a certain point in your life, you start looking for synonyms to use in place of “old”.
If your a venerable yet still useful Oracle IDE for example, you may prefer the term “Classic”.
One thing SQLDeveloper Classic isn’t is obsolete. It still allows customisations that are not currently available in it’s shiny new successor – the SQLDeveloper extension for VSCode.
Fortunately, there’s no reason you can’t run both versions at the same time – unless your corporate IT has been overzealous and either packaged VSCode in an MSI that prohibits installation of extensions or has a policy preventing extensions running because “security”.
Either way, SQLDeveloper Classic is likely to be around for a while.
One particular area where Classic still has the edge over it’s shiny new successor is when it comes to user-defined extensions.
In this case – finding out the partition key and method of a table without having to wade through the DDL for that object…
The following query should give us what we’re after – details of the partitioning and sub-partitioning methods used for a table, together with a list of the partition and (if applicable) sub-partition key columns :
with part_cols as
(
select
owner,
name,
listagg(column_name, ', ') within group ( order by column_position) as partition_key_cols
from all_part_key_columns
group by owner, name
),
subpart_cols as
(
select
owner,
name,
listagg(column_name, ', ') within group ( order by column_position) as subpartition_key_cols
from all_subpart_key_columns
group by owner, name
)
select
tab.owner,
tab.table_name,
tab.partitioning_type,
part.partition_key_cols,
tab.subpartitioning_type,
sp.subpartition_key_cols
from all_part_tables tab
inner join part_cols part
on part.owner = tab.owner
and part.name = tab.table_name
left outer join subpart_cols sp
on sp.owner = tab.owner
and sp.name = tab.table_name
where tab.owner = 'SH'
and table_name = 'SALES'
order by 1,2
/
That’s quite a lot of code to type in – let alone remember – every time we want to check this metadata, so let’s just add an extra tab to the Table view in SQLDeveloper.
Using this query, I’ve created an xml file called table_partitioning.xml to add a tab called “Partition Keys” to the SQLDeveloper Tables view :
<items>
<item type="editor" node="TableNode" vertical="true">
<title><![CDATA[Partition Keys]]></title>
<query>
<sql>
<![CDATA[
with part_cols as
(
select
owner,
name,
listagg(column_name, ', ') within group ( order by column_position) as partition_key_cols
from all_part_key_columns
group by owner, name
),
subpart_cols as
(
select
owner,
name,
listagg(column_name, ', ') within group ( order by column_position) as subpartition_key_cols
from all_subpart_key_columns
group by owner, name
)
select
tab.owner,
tab.table_name,
tab.partitioning_type,
part.partition_key_cols,
tab.subpartitioning_type,
sp.subpartition_key_cols
from all_part_tables tab
inner join part_cols part
on part.owner = tab.owner
and part.name = tab.table_name
left outer join subpart_cols sp
on sp.owner = tab.owner
and sp.name = tab.table_name
where tab.owner = :OBJECT_OWNER
and table_name = :OBJECT_NAME
order by 1,2
]]>
</sql>
</query>
</item>
</items>
Note that we’re using the SQLDeveloper supplied ( and case-sensitive) variables :OBJECT_OWNER and :OBJECT_NAME so that the data returned is for the table that is in context when we open the tab.
If you are familiar with the process of adding User Defined Extensions to SQLDeveloper and want to get your hands on this one, just head over to the Github Repo where I’ve uploaded the relevant file.
You can also find instructions for adding the tab to SQLDeveloper as a user defined extension there.
They are…
In SQLDeveloper select the Tools Menu then Preferences.
Search for User Defined Extensions

Click the Add Row button then click in the Type field and select Editor from the drop-down list

In the Location field, enter the full path to the xml file containing the extension you want to add

Hit OK
Restart SQLDeveloper.
When you select an object of the type for which this extension is defined ( Tables in this example), you will see the new tab has been added

The new tab will work like any other :
 Useful Links
Useful Links
The documentation for Extensions has been re-organised in recent years, but here are some links you may find useful :
As you’d expect, Jeff Smith has published a few articles on this topic over the years. Of particular interest are :
- An Introduction to SQLDeveloper Extensions
- Using XML Extensions in SQLDeveloper to Extend SYNONYM Support
- How To Add Custom Actions To Your User Reports
The Oracle-Samples GitHub Repo contains lots of example code and some decent instructions.
I’ve also covered this topic once or twice over the years and there are a couple of posts that you may find helpful :
- SQLDeveloper XML Extensions and auto-navigation includes code for a Child Tables tab, an updated version of which is also in the Git Repo.
- User-Defined Context Menus in SQLDeveloper
Looking for help with JSON object
Setup Apex 22.1 email with MS O365 Outlook SMTP
unique index
Pagination Cost – 2
This note is a follow-on to a note I published a couple of years ago, and was prompted by a question on the MOS community forum (needs an acount) about the performance impact of using bind variables instead of literal values in a clause of the form: offset 20 rows fetch next 20 rows only
The issue on MOS may have been to do with the complexity of the view that was was being queried, so I thought I’d take a look at what happened when I introduced bind variables to the simple tests from the previous article. Here’s the (cloned) script with the necessary modification:
rem
rem Script: fetch_first_offset_3.sql
rem Author: Jonathan Lewis
rem Dated: May 2025
rem
create table t1
as
select
*
from
all_objects
where rownum <= 50000
order by
dbms_random.value
/
create index t1_i1 on t1(object_name);
alter session set statistics_level = all;
set serveroutput off
column owner format a32
column object_type format a12
column object_name format a32
spool fetch_first_offset_3.lst
prompt ===================================
prompt SQL with literals (non-zero offset)
prompt ===================================
select
owner, object_type, object_name
from
t1
order by
object_name
offset
10 rows
fetch next
20 rows only
/
select * from table(dbms_xplan.display_cursor(format=>'+cost allstats last peeked_binds'));
variable offset_size number
variable fetch_size number
begin
:offset_size := 10; :fetch_size := 20;
end;
/
prompt ==============
prompt SQL with binds
prompt ==============
alter session set events '10053 trace name context forever';
select
owner, object_type, object_name
from
t1
order by
object_name
offset
:offset_size rows
fetch next
:fetch_size rows only
/
alter session set events '10053 trace name context off';
select * from table(dbms_xplan.display_cursor(format=>'+cost allstats last peeked_binds'));
I’ve created a simple data set by copying 50,000 rows from the view all_objects and creating an index on the object_name column then, using two different strategies, I’ve selected the 21st to 30th rows in order of object_name. The first strategy uses literal values in the offset and fetch first/next clauses to skip 10 rows then fetch 20 rows; the second strategy creates a couple of bind variables to specify the offset and fetch sizes.
Here’s the execution plan (pulled from memory, with the rowsource execution statistics enabled) for the example using literal values:
SQL_ID d7tm0uhcmpwc4, child number 0
-------------------------------------
select owner, object_type, object_name from t1 order by object_name
offset 10 rows fetch next 20 rows only
Plan hash value: 3254925009
-----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 33 (100)| 20 |00:00:00.01 | 35 | 333 |
|* 1 | VIEW | | 1 | 30 | 33 (0)| 20 |00:00:00.01 | 35 | 333 |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 30 | 33 (0)| 30 |00:00:00.01 | 35 | 333 |
| 3 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 50000 | 33 (0)| 30 |00:00:00.01 | 35 | 333 |
| 4 | INDEX FULL SCAN | T1_I1 | 1 | 30 | 3 (0)| 30 |00:00:00.01 | 5 | 28 |
-----------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("from$_subquery$_002"."rowlimit_$$_rownumber"<=30 AND
"from$_subquery$_002"."rowlimit_$$_rownumber">10))
2 - filter(ROW_NUMBER() OVER ( ORDER BY "OBJECT_NAME")<=30)
As you can see, the optimizer has used (started) an index full scan to access the rows in order of object_name, but the A-Rows column tells you that it has passed just 30 rowids (the 10 to be skipped plus the 20 to be fetched) up to its parent (table access) operation, and the table access operation has passed the required columns up to its parent (window nosort stopkey) which can conveniently discard the first 10 rows that arrive and pass the remain 20 rows up and on to the client without actually doing any sorting.
You can also see in the Predicate Information that the window operation has used the row_number() function to limit itself to the first 30 (i.e. 10 + 20) rows, passing them up to its parent where the “30 rows” predicate is repeated with a further predicate that eliminates the first 10 of those rows, leaving only the 20 rows requested.
So what does the plan look like when we switch to bind variables:
SQL_ID 5f85rkjc8bv8a, child number 0
-------------------------------------
select owner, object_type, object_name from t1 order by object_name
offset :offset_size rows fetch next :fetch_size rows only
Plan hash value: 1024497473
--------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 933 (100)| 20 |00:00:00.03 | 993 | 990 | | | |
|* 1 | VIEW | | 1 | 50000 | 933 (1)| 20 |00:00:00.03 | 993 | 990 | | | |
|* 2 | WINDOW SORT PUSHED RANK| | 1 | 50000 | 933 (1)| 30 |00:00:00.03 | 993 | 990 | 11264 | 11264 |10240 (0)|
|* 3 | FILTER | | 1 | | | 50000 |00:00:00.02 | 993 | 990 | | | |
| 4 | TABLE ACCESS FULL | T1 | 1 | 50000 | 275 (1)| 50000 |00:00:00.01 | 993 | 990 | | | |
--------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("from$_subquery$_002"."rowlimit_$$_rownumber" <= GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:OFFSET_SIZE))),0)+:FETCH_SIZE AND
"from$_subquery$_002"."rowlimit_$$_rownumber" > :OFFSET_SIZE))
2 - filter(ROW_NUMBER() OVER ( ORDER BY "OBJECT_NAME") <= GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:OFFSET_SIZE))),0)+:FETCH_SIZE)
3 - filter(:OFFSET_SIZE < GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:OFFSET_SIZE))),0)+:FETCH_SIZE)
This looks like bad news – we haven’t taken advantage of an index to avoid visiting and sorting all the rows in the table, operation 4 shows us a table scan passing 50,000 rows through a filter up to the window sort at operation 2 which discards the 49,970 rows we definitely don’t want before passing the remaining 30 rows to the view operation that discards the first 10 that we needed to skip. Why don’t we see the far more efficient index scan?
You may have noticed a couple of oddities in the Predicate Information.
- Wherever you see the :offset_size bind variable the optimizer has wrapped it in to_number(to_char()) – why?! My first thought about this was that the double conversion made it impossible for the optimizer to peek at the value and use it to get a better estimate of cost, but that’s (probably) not why the index full scan disappeared.
- The offset and fetch first are both supposed to be numeric (according to the tram-tracks in the manual) so it seems a little strange that Oracle treats just one of them to a double conversion.
- What is that filter() in operation 3 actually trying to achieve? If you tidy up the messy bits it’s just checking two bind variables to make sure that the offset is less than the offset plus fetch size. This is just an example of “conditional SQL”. In this case it’s following the pattern for “columnX between :bind1 and :bind2” – allowing Oracle to short-circuit the sub-plan if the value of bind2 is less than that of bind1. (It wasn’t needed for the example where we used literals because Oracle could do the artithmetic at parse time and see that 10 was – and always would be – less than 30.)
- What are the checks actually saying about the optimizer’s (or developer’s) expectation for the way you might use the feature? The generated SQL actually allows for negative, non-integer values here. Negative offsets are replaced by zero, negative fetch sizes result in the query short-circuiting and returning no data (in fact any fetech size strictly less than 1 will return no rows).
Hoping to find further clues about the poor choice of plan, I took a look at the “UNPARSED QUERY” from the CBO (10053) trace, and cross-checked against the result from using the dbms_utility.expand_sql() procedure; the results were (logically, though not cosmetically) the same. Here, with a little extra cosmetic tidying is the SQL the optimizer actually works with:
select
a1.owner owner,
a1.object_type object_type,
a1.object_name object_name
from (
select
a2.owner owner,
a2.object_type object_type,
a2.object_name object_name,
a2.object_name rowlimit_$_0,
row_number() over (order by a2.object_name) rowlimit_$$_rownumber
from
test_user.t1 a2
where
:b1 < greatest(floor(to_number(to_char(:b2))),0)+:b3
) a1
where
a1.rowlimit_$$_rownumber <= greatest(floor(to_number(to_char(:b4))),0) + :b5
and a1.rowlimit_$$_rownumber > :b6
order by
a1.rowlimit_$_0
;
It’s fascinating that the optimizer manages to expand the original two bind variables to six bind variables (lots of duplication) and then collapse them back to two named bind variables for the purposes of reporting the Predicate Information. For reference:
- b1 = b3 = b5 = fetch_size
- b2 = b4 = b5 = offset_size
Line 15, which I’ve highlighted, is clearly the source of the “conditional SQL” filter predicate at operation 3 of the previous execution plan, so I thought I’d try running this query (pre-defining all 6 bind variables correctly) to see if I could get the index-driven plan by modifying that line.
My first attempt was simply to remove the (highly suspect) to_number(to_char()) – but that didn’t help. Then I thought I’d make it really simple by getting rid of the greatest(floor()) functions – and that didn’t help either,. Finally I decided to change what was now :b4 + :b5 to a single bind variable :b7 with the right values – and that’s when I got the plan I wanted:
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20 |00:00:00.01 | 35 |
|* 1 | VIEW | | 1 | 30 | 20 |00:00:00.01 | 35 |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 30 | 30 |00:00:00.01 | 35 |
|* 3 | FILTER | | 1 | | 30 |00:00:00.01 | 35 |
| 4 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 50000 | 30 |00:00:00.01 | 35 |
| 5 | INDEX FULL SCAN | T1_I1 | 1 | 30 | 30 |00:00:00.01 | 5 |
--------------------------------------------------------------------------------------------------
Of course this doesn’t help answer the question – how do I make the query faster – it just highlights where in the current transformation the performance problem appears. Maybe it’s a pointer to some Oracle developer that there’s some internal code that could be reviewed – possibly for a special (but potentially common) pattern. Perhaps there’s a point of interception where a fairly small, isolated piece of code could be modified to give the optimizer the simpler expression during optimisation.
As for addressing the problem of finding a “client-oriented” mechanism, I found two solutions for my model. First add the (incomplete, but currently adequate) hint /*+ index(t1) */ to the SQL to get:
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 50311 (100)| 20 |00:00:00.01 | 25 |
|* 1 | VIEW | | 1 | 50000 | 50311 (1)| 20 |00:00:00.01 | 25 |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 50000 | 50311 (1)| 20 |00:00:00.01 | 25 |
|* 3 | FILTER | | 1 | | | 20 |00:00:00.01 | 25 |
| 4 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 50000 | 50311 (1)| 20 |00:00:00.01 | 25 |
| 5 | INDEX FULL SCAN | T1_I1 | 1 | 50000 | 339 (1)| 20 |00:00:00.01 | 5 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("from$_subquery$_002"."rowlimit_$$_rownumber"<=GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0
)+:B2 AND "from$_subquery$_002"."rowlimit_$$_rownumber">:B1))
2 - filter(ROW_NUMBER() OVER ( ORDER BY "OBJECT_NAME")<=GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0)+:
B2)
3 - filter(:B1<GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0)+:B2)
As you can see we now do the index full scan, but it stops after only 20 rowids have been passed up the plan. This isn’t a good solution, of course, since (a) it’s specific to my model and (b) the estimates still show the optimizer working on the basis of handling and forwarding 50,000 rows (E-rows).
The alternative was to tell the optimizer that since we’re doing pagination queries we’re only expecting to fetch a little data each time we execute the query – let’s add the hint /*+ first_rows(30) */ which gives us:
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 33 (100)| 20 |00:00:00.01 | 25 |
|* 1 | VIEW | | 1 | 30 | 33 (0)| 20 |00:00:00.01 | 25 |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 30 | 33 (0)| 20 |00:00:00.01 | 25 |
|* 3 | FILTER | | 1 | | | 20 |00:00:00.01 | 25 |
| 4 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 50000 | 33 (0)| 20 |00:00:00.01 | 25 |
| 5 | INDEX FULL SCAN | T1_I1 | 1 | 30 | 3 (0)| 20 |00:00:00.01 | 5 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("from$_subquery$_002"."rowlimit_$$_rownumber"<=GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0
)+:B2 AND "from$_subquery$_002"."rowlimit_$$_rownumber">:B1))
2 - filter(ROW_NUMBER() OVER ( ORDER BY "OBJECT_NAME")<=GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0)+:
B2)
3 - filter(:B1<GREATEST(FLOOR(TO_NUMBER(TO_CHAR(:B1))),0)+:B2)
This is likely to be a much better strategy than “micro-management” hinting; and it may even be appropriate to set the optimizer_mode at the session level with a logon trigger, first_rows_10 or first_rows_100 could well be a generally acceptable result if most of the queries tended to be about reporting the first few rows of a large result set. A key point to note is that both E-Rows and Cost are reasonably representative of the work done, while the corresponding figures when we hinted the use of the index were wildly inaccurate.
MacIntyre, Memory Eternal
There are a handful of living thinkers that have made me re-think fundamental presuppositions that I held consciously (or not) for some time in my early life. Each, in his own way, a genius - but in particular a genius in re-shaping the conceptualization of an intellectual space for me. Until yesterday they were in no particular order, Noam Chomsky, David Bentley Hart, John Milbank, Michael Hudson, Alain de Benoist and Alasdair MacIntyre. We recently lost Rene Girard. Now MacIntyre is no longer with us. His precise analytics, pulling insights from thinkers ranging from Aristotle to Marx, was rarely matched in the contemporary world. The hammer blow that After Virtue was to so many of my assumptions and beliefs is hard to describe - my entire view of the modern project, especially around ethics, was undone. But it was also his wisdom about the human animal and what really mattered in terms of being a human being that set him apart.
SQL Server 2025 – ZSTD – A new compression algorithm for backups
SQL Server 2025 introduces a new algorithm for backup compression: ZSTD. As a result, SQL Server 2025 now offers three solutions for backup compression:
- MS_XPRESS
- QAT
- ZSTD
In this blog, we will compare MS_XPRESS and ZSTD.
EnvironmentTo perform these tests, the following virtual machine was used:
- OS: Windows Server 2022 Datacenter
- SQL Server: 2025 Standard Developer
- CPU: 8 cores
- VM memory: 12 GB
- (SQL) Max server memory: 4 GB
Additionally, I used the StackOverflow database to run the backup tests (reference: https://www.brentozar.com/archive/2015/10/how-to-download-the-stack-overflow-database-via-bittorrent/).
ZSTD usageThere are several ways to use the new ZSTD compression algorithm. Here are two methods:
- Add the following terms to the SQL backup commands: WITH COMPRESSION (ALGORITHM = ZSTD)
BACKUP DATABASE StackOverflow TO DISK = 'T:\S1.bak' WITH INIT, FORMAT, COMPRESSION (ALGORITHM = ZSTD), STATS = 5- Change the compression algorithm at the instance level:
EXECUTE sp_configure 'backup compression algorithm', 3;
RECONFIGURE;
The StackOverflow database used has a size of approximately 165 GB. To perform an initial test using the MS_XPRESS algorithm, the commands below were executed:
SET STATISTICS TIME ON
BACKUP DATABASE StackOverflow TO DISK = 'T:\S1.bak' WITH INIT, FORMAT, COMPRESSION, STATS = 5;Here is the result:
BACKUP DATABASE successfully processed 20 932 274 pages in 290.145 seconds (563.626 MB/sec).
SQL Server Execution Times: CPU time = 11 482 ms, elapsed time = 290 207 ms.For the second test, we are using the ZSTD algorithm with the commands below:
SET STATISTICS TIME ON
BACKUP DATABASE StackOverflow TO DISK = 'T:\S1.bak' WITH INIT, FORMAT, COMPRESSION (ALGORITHM = ZSTD), STATS = 5Here is the result:
BACKUP DATABASE successfully processed 20 932 274 pages in 171.338 seconds (954.449 MB/sec).
CPU time = 10 750 ms, elapsed time = 171 397 ms.It should be noted that my storage system cannot sustain its maximum throughput for an extended period. In fact, when transferring large files (e.g., 100 GB), the throughput drops after about 15 seconds (for example, from 1.2 GB/s to 500 MB/s).
According to the initial data, the CPU time between MS_XPRESS and ZSTD is generally the same. However, since ZSTD allows backups to be performed more quickly (based on the tests), the overall CPU time is lower with the ZSTD algorithm. Indeed, because the backup duration is reduced, the time the CPU spends executing instructions (related to backups) is also lower.
Comparison table for elapsed time with percentage gain:
During the tests, performance counters were set up to gain a more accurate view of the behavior of the two algorithms during a backup. For this, we used the following counters:
- Backup throughput/sec (KB)
- Disk Read KB/sec (in my case, Disk Read KB/sec is equal to the values of the Backup Throughput/sec (KB) counter). In fact, the “Backup throughput/sec (KB)” counter reflects the reading of data pages during the backup.
- Disk Write KB/sec
- Processor Time (%)
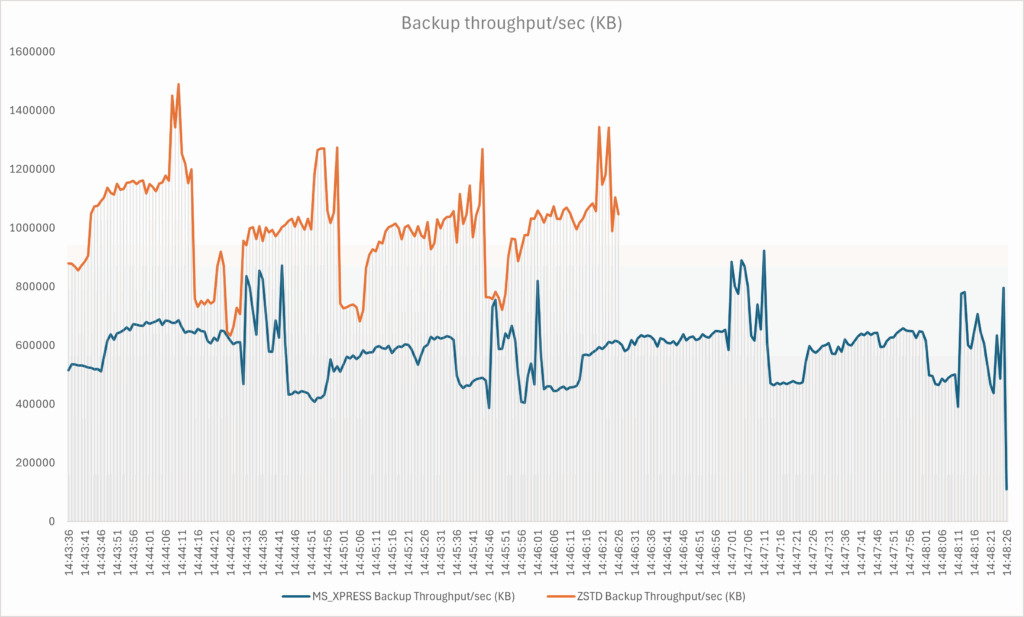
We observe that the throughput is higher with the ZSTD algorithm. The drop that appears is explained by the fact that ZSTD enabled the backup to be completed more quickly. As a result, the backup operation took less time, and the amount of data collected is lower compared to the other solution. Additionally, it should be noted that the database is hosted on volume (S) while the backups are stored on another volume (T).
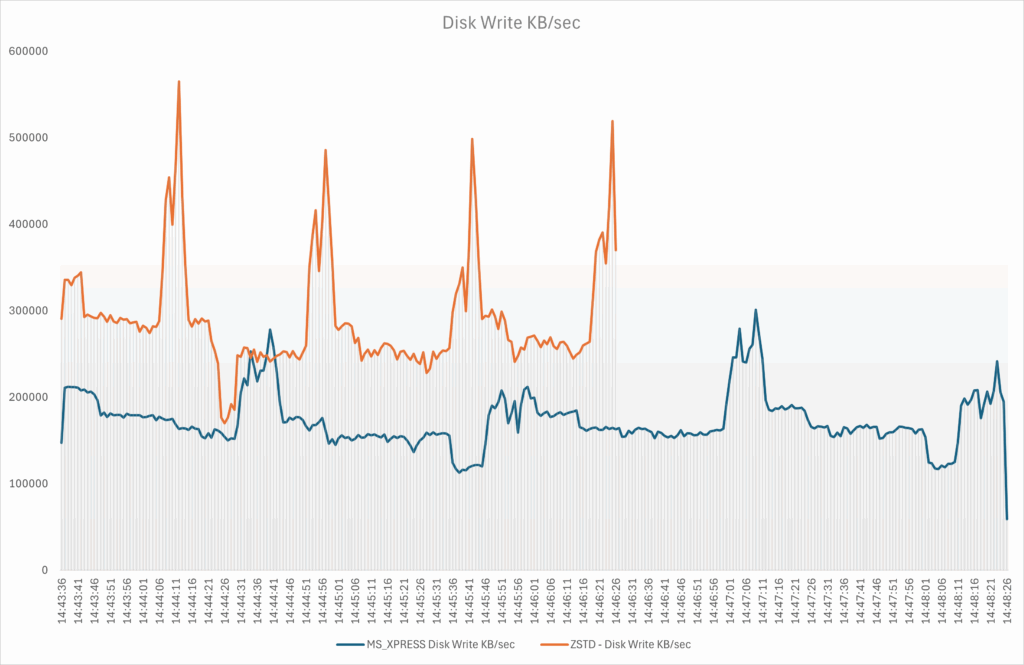
We also observe that the write throughput is higher when using the ZSTD algorithm.
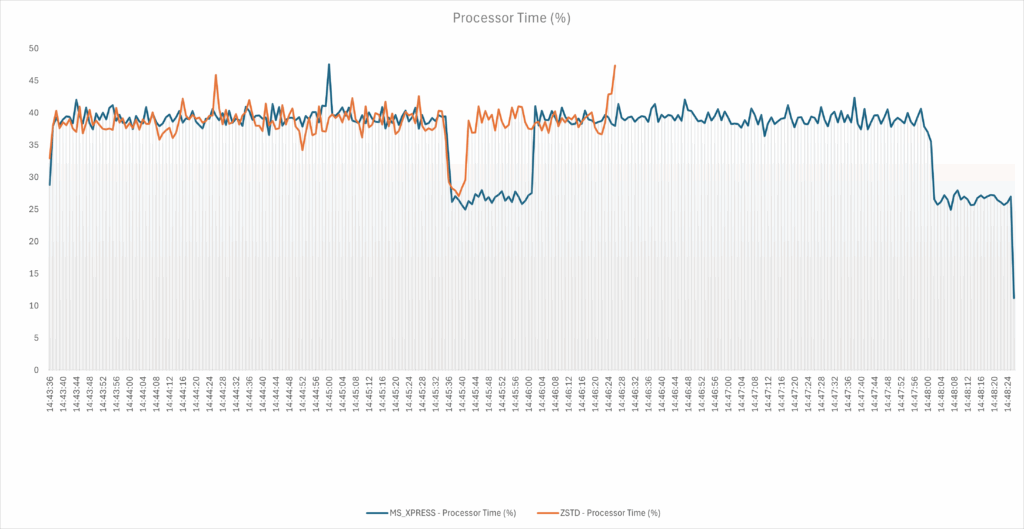
For the same observed period, the CPU load is generally the same however ZSTD allows a backup to be completed more quickly (in our case). As a result, the overall CPU load is generally lower.
We also observe that the backup ratio (on this database) is higher with the ZSTD algorithm. This indicates that the size occupied by the compressed backup is smaller with ZSTD.
backup_ratiodatabase_namebackup_typecompressed_backup_size (bytes)compression_algorithm3.410259900691847063StackOverflowFull50 283 256 836MS_XPRESS3.443440933211591093StackOverflowFull49 798 726 852ZSTD ConclusionBased on the tests performed, we observe that the ZSTD algorithm allows:
- Faster backup creation
- Reduced CPU load because backups are produced more quickly
- Reduced backup size
However, it should be noted that further testing is needed to confirm the points above.
Thank you, Amine Haloui.
L’article SQL Server 2025 – ZSTD – A new compression algorithm for backups est apparu en premier sur dbi Blog.