

Feed aggregator
Building Stateful AI Agents That Actually Remember : Moving Beyond RAG in Oracle AI
RAG (Retrieval-Augmented Generation) is great for looking things up. But it’s not memory. Real AI agents need continuity — they need to remember user preferences, past decisions, policies, and completed work across sessions. That’s where a proper memory system comes in.
This guide shows how to evolve basic RAG into a production-grade memory layer that gives your agents true statefulness, continuity, and governance.
Why Basic RAG Falls Short- No multi-turn continuity — agents forget what was just discussed
- No resumability — close the tab and everything is lost
- No long-term recall of user preferences or policies
- Prompts grow uncontrollably, leading to higher costs and lost-in-the-middle problems
RAG is retrieval. Memory is a write path + retrieval + governance loop.
What a Real Memory System Looks LikeA memory system adds a durable write path and a manager that decides what to store, how to retrieve it, and how to rebuild the prompt on every turn. It turns one-time lookup into reusable, governed knowledge.
Core loop per turn:
- Append user message to trace
- Retrieve relevant typed memory (policy, preferences, facts, episodes)
- Reassemble prompt from memory (never accumulate transcript)
- Call the model
- Extract and promote new artifacts through a gate
Don’t throw everything into one vector store. Separate concerns:
1. Policy MemoryRules, guardrails, compliance constraints. Exact-match lookup, never similarity.
2. Preference MemoryUser settings and personalization (“always return JSON”, “use DD/MM/YYYY”). Fast keyed lookup.
3. Fact MemoryDurable assertions with provenance (“Acme’s production DB is in us-east-1”). Hybrid lexical + semantic retrieval.
4. Episodic MemorySummaries of completed tasks. Reusable patterns for similar future work.
5. Trace MemoryRaw execution log for replay, debugging, and audit. Append-only, high volume.
Storage Tradeoffs That Matter- Short-term vs Long-term — Keep working set in RAM, durable state in the database
- Filesystem vs Database — Files are great for single-tenant prototypes; databases are required for multi-tenant production
- Typed tables vs single store — Separate tables per memory type give you the right indexes, retention, and access patterns
- Known-scope lookup — Policy and preferences (exact match, runs every turn)
- Semantic discovery — Facts and episodes (hybrid lexical + vector search)
Always filter by scope before ranking — never after.
How to Add Memory to Your Agent (Practical Steps)- Type your memory — label everything as policy, preference, fact, episodic, or trace
- Scope every record (tenant_id, user_id, agent_id)
- Build a promotion gate that decides what gets stored durably
- Reassemble the prompt on every turn from memory (don’t accumulate transcript)
- Instrument the entire loop for replay and audit
RAG gives you lookup. A memory system gives you continuity, personalization, and governed recall. The difference is the write path, typed storage, scoped retrieval, and a manager that reassembles context intelligently on every turn.
Once you have a real memory layer, your agents stop feeling stateless and generic. They start to feel like they actually know the user, remember past work, and follow the right rules — every single time.
Models are shared. Your memory system is what makes your AI product yours.
Start small, type your memory early, and build the promotion gate before you scale. The investment pays off the moment your users come back for a second conversation.
Oracle Deep Data Security in AI Database 26ai: Secure AI Agents at the Source
AI agents are powerful, but they introduce a serious new risk: they act as autonomous insiders with broad database access. Traditional application-layer security can’t keep up. Oracle Deep Data Security changes that by enforcing end-user authorization directly inside the database — even when AI agents, vibe-coded apps, or analytics tools query data on a user’s behalf.
Now available in Oracle AI Database 26ai, Deep Data Security brings true “security at the source” to the agentic era.
The Problem: Privileged Access in the AI EraMost applications use highly privileged database connections. The app layer is supposed to filter data for each user. But AI agents don’t follow predefined queries — they generate their own. This creates massive risk of unauthorized data exposure, especially with prompt injection or unexpected agent behavior.
Even vibe-coded or rapidly evolving applications can’t be trusted to enforce security perfectly every time.
How Oracle Deep Data Security Solves ItDeep Data Security lets you propagate the real end-user identity and context (via OAuth tokens or direct authentication) into the database at runtime. Declarative data grants then enforce row-level, column-level, and cell-level access based on who the user is — not on what the application or agent asks for.
The database automatically rewrites every query to apply the correct authorization rules before any data is returned. This works consistently whether the request comes from a traditional app, an AI agent, or a direct SQL query.
Real-World Example: Human Capital Management (HCM)Consider an HR table containing sensitive employee data (SSN, salary, phone number, etc.).
- Emma (employee) should only see her own record.
- Marvin (her manager) should see his own record plus his direct reports, but not SSN or home address.
With Deep Data Security, both users (or any AI agent acting on their behalf) can query the same table. The database automatically returns only the data each person is authorized to see — no application code required.
Key Capabilities- End users (distinct from schema users) authenticate directly to the database
- Data roles + data grants define precise row/column access using predicates
ORA_END_USER_CONTEXT.usernameresolves the current user’s identity at runtime- Works for AI agents, traditional apps, analytics tools, and direct SQL
- Centralized policy management — no duplication of security logic across layers
Oracle provides a complete LiveLab to explore Deep Data Security in minutes. Here’s the core flow:
- Create end users (Emma and Marvin)
- Define data roles (HRAPP_EMPLOYEES and HRAPP_MANAGERS)
- Create data grants with predicates like:
or manager lookup logicWHERE upper(user_name) = upper(ORA_END_USER_CONTEXT.username) - Connect as each user and run queries — the database enforces boundaries automatically
Even if an AI agent generates unexpected SQL, the results are still correctly restricted.
Analyst PerspectiveLeading analysts agree this is a critical shift for the agentic era:
“Oracle Deep Data Security introduces identity-aware, fine-grained access control enforced at the database layer… This is a big step up from application-layer controls that are hard to enforce consistently across rapidly evolving agentic workflows.” — Steve McDowell, NAND Research ConclusionIn the age of autonomous AI agents, security at the application layer is no longer enough. Oracle Deep Data Security moves enforcement to the database — where the data lives — giving you consistent, trustworthy, and auditable protection regardless of how data is accessed.
Cloudflare@OCI: Edge Security & Performance for Your OCI Applications and AI Workloads
Modern applications and AI workloads demand global speed, strong security, and simple operations. Cloudflare@OCI delivers exactly that by combining Oracle Cloud Infrastructure’s powerful compute and AI platform with Cloudflare’s massive global edge network (330+ cities worldwide).
This strategic partnership lets you accelerate and protect your OCI workloads without managing multiple vendors or complex integrations.
Key Benefits of Cloudflare@OCI- Significantly reduce latency for users worldwide with Cloudflare’s global CDN
- Protect against DDoS, bots, and API threats at the edge — before traffic reaches OCI
- Apply consistent security policies across hybrid, multicloud, and on-premises environments
- Simplify procurement and billing — everything is available directly in the OCI Console
- Lower data transfer costs through the Bandwidth Alliance (zero egress fees for OCI Object Storage in North America)
Choose the right level of edge protection and performance:
- Cloudflare Business Services — Essential CDN, DDoS protection, WAF, and basic rate limiting
- Cloudflare Enterprise Entry — Advanced certificate management, load balancing, and logging
- Cloudflare Enterprise Essential — Optimized routing, enhanced DDoS protection, and accelerated DNS
- Cloudflare Enterprise Advanced — Full security suite including Bot Management, advanced rate limiting, content scanning, and client-side protection
AI applications require low latency, strong security, and reliable global delivery. Cloudflare@OCI helps you:
- Accelerate AI inference and model serving at the edge
- Secure AI APIs and vector search endpoints
- Protect against prompt injection and other emerging AI threats
- Deliver consistent performance for distributed AI systems across regions
- Log in to the OCI Console
- Navigate to Identity & Security
- Browse and select the Cloudflare@OCI package that fits your needs
- Purchase and connect your OCI workloads to Cloudflare
- Configure policies and deploy in minutes
Cloudflare@OCI gives you the best of both worlds: OCI’s high-performance cloud infrastructure paired with Cloudflare’s industry-leading edge security and global performance platform — all managed through a single, Oracle-led experience.
Whether you’re building traditional web apps, modern microservices, or production AI systems, this partnership helps you deliver faster, safer, and more reliable experiences to users everywhere.
Master Regular Expressions in Oracle AI Database: Powerful Pattern Matching for Developers
Regular expressions (regex) are one of the most powerful tools for working with text in Oracle AI Database. Whether you need to validate phone numbers, extract email addresses, clean messy data, or enforce complex business rules, Oracle’s built-in regex support makes it fast, efficient, and easy to implement directly in SQL.
Why Use Regular Expressions in Oracle?- Centralize complex pattern-matching logic in the database instead of the application layer
- Enforce data quality and business rules with CHECK constraints
- Search, replace, and transform text with simple SQL functions
- Greatly simplify data validation, extraction, and cleansing tasks
Oracle provides five powerful functions/conditions for regular expressions:
Function / ConditionDescription REGEXP_LIKEReturns TRUE if the string matches the pattern (perfect for WHERE clauses and CHECK constraints) REGEXP_COUNTCounts how many times the pattern appears REGEXP_INSTRReturns the position where the pattern starts REGEXP_SUBSTRExtracts the matching substring REGEXP_REPLACEReplaces matching text with new content Basic Syntax and OptionsREGEXP_LIKE(source_string, pattern [, match_parameter])Common match parameters:
'i'— case-insensitive'c'— case-sensitive (default)'n'— dot (.) matches newline'm'— multiline mode (^ and $ match start/end of lines)'x'— ignore whitespace in pattern
CREATE TABLE contacts (
last_name VARCHAR2(30),
phone VARCHAR2(30)
CONSTRAINT valid_phone
CHECK (REGEXP_LIKE(phone, '^\(\d{3}\) \d{3}-\d{4}$'))
);SELECT REGEXP_COUNT('Albert Einstein', 'e', 1, 'i') AS count_e
FROM dual;SELECT REGEXP_SUBSTR(email, '\w+@\w+(\.\w+)+') AS email_address
FROM employees;SELECT
names,
REGEXP_REPLACE(names, '^(\S+)\s(\S+)\s(\S+)$', '\3, \1 \2') AS formatted_name
FROM famous_people;Oracle supports the full set of POSIX operators plus useful PERL-style shortcuts:
\d— digit\w— word character (alphanumeric + underscore)\s— whitespace\A,\Z,\z— string anchors- Nongreedy quantifiers (
+?,*?, etc.)
- Use regex in CHECK constraints to enforce data quality at the database level
- Prefer regex over complex string functions when pattern matching is involved
- Test thoroughly — regex can be tricky with edge cases
- Use the
'x'flag to make complex patterns more readable - Combine with other SQL features (e.g., REGEXP_REPLACE inside UPDATE statements)
Regular expressions in Oracle AI Database give you enterprise-grade text processing power directly in SQL. From simple validation to complex data transformation, regex lets you solve real-world text problems efficiently without leaving the database.
Whether you’re cleaning data, enforcing business rules, or building sophisticated search features, mastering Oracle regex will make you a much more effective developer.
Real-World Performance Best Practices for Oracle AI Database Applications
Building applications on Oracle AI Database that scale, stay fast, and remain secure in production requires deliberate design choices. The Oracle Real-World Performance group has proven over years of testing that three simple practices make the biggest difference: **bind variables**, **instrumentation**, and **set-based processing**.
These techniques are even more critical in the AI era, where applications often combine transactional workloads with AI agents, vector search, and MCP Server interactions.
1. Always Use Bind VariablesBind variables are one of the easiest ways to dramatically improve scalability and security.
Instead of concatenating strings into SQL (which causes hard parsing, latch contention, and SQL injection risks), use placeholders:
-- Bad: String concatenation
INSERT INTO test (x, y) VALUES (''' || REPLACE(x, '''', '''''') || ''', ''' || REPLACE(y, '''', '''''') || '''');
-- Good: Bind variables
INSERT INTO test (x, y) VALUES (:x, :y);Benefits:
- Only one statement is parsed and cached in the shared pool
- Massive reduction in latches and CPU overhead
- Supports thousands of users without performance degradation
- Protects against SQL injection attacks
Instrumentation means adding debug/trace code that helps you understand exactly what your application is doing at runtime.
In Oracle, this is as simple as setting MODULE and ACTION in V$SESSION or enabling SQL Trace. When something goes wrong in a multi-tier or AI-augmented application, trace files quickly show you which tier is causing the issue.
Good practice in PL/SQL or application code:
DBMS_APPLICATION_INFO.SET_MODULE(module_name => 'AI_AGENT_WORKFLOW',
action_name => 'PROCESS_CUSTOMER_DATA');Instrumentation is essential when working with AI agents, MCP Server, or Private Agent Factory — it lets you trace exactly what the LLM is doing in the database.
3. Prefer Set-Based Processing Over Iterative (Row-by-Row)For large data volumes, set-based SQL is orders of magnitude faster than row-by-row processing.
Row-by-Row (Slow)DECLARE
CURSOR c IS SELECT * FROM ext_scan_events;
BEGIN
FOR r IN c LOOP
INSERT INTO stage1_scan_events VALUES r;
COMMIT; -- Very expensive!
END LOOP;
END;ALTER SESSION ENABLE PARALLEL DML;
INSERT /*+ APPEND */ INTO stage1_scan_events
SELECT * FROM ext_scan_events;
COMMIT;Why set-based wins:
- Eliminates network round-trips and repeated parsing
- Leverages Oracle’s parallel execution and direct-path loads
- Reduces commits dramatically
- Handles billions of rows efficiently
Array processing and manual parallelism are better than pure row-by-row, but set-based SQL remains the clear winner for performance.
Summary: Three Rules for Real-World Performance- Use bind variables everywhere — for security and scalability
- Instrument your code — so you can debug and monitor AI-augmented workflows
- Think in sets, not rows — let the database do the heavy lifting
In the AI era, applications are more complex than ever — mixing OLTP, vector search, agents, and analytics. Following these three real-world performance practices will keep your Oracle AI Database applications fast, scalable, and easy to maintain.
Small design decisions made early (bind variables, instrumentation, set-based SQL) deliver massive returns in production.
Aggregation Filters in Oracle AI Database 26ai: Cleaner Conditional Aggregates
Need to calculate different aggregates based on conditions in a single query — without multiple subqueries or CASE statements? Oracle AI Database 26ai introduces **Aggregation Filters**, a clean and powerful new feature that makes conditional SUM, COUNT, AVG, and other aggregates much simpler.
What Are Aggregation Filters?Aggregation filters let you apply a WHERE condition directly inside an aggregate function. Only rows that match the condition are included in that specific calculation.
aggregate_function ( expression ) FILTER ( WHERE condition )Works with any aggregate function: SUM, COUNT, AVG, MAX, MIN, etc.
SELECT COUNT(*) FILTER (WHERE status = 'ACTIVE') AS active_count
FROM employees;SELECT SUM(salary) FILTER (WHERE department = 'SALES') AS sales_total
FROM employees;SELECT
COUNT(*) FILTER (WHERE status = 'ACTIVE') AS active_count,
COUNT(*) FILTER (WHERE status = 'INACTIVE') AS inactive_count
FROM employees;SELECT
year,
SUM(sales) AS year_sales,
SUM(sales) FILTER (WHERE qtr_num IN (1, 2)) AS q1q2_sales,
SUM(sales) FILTER (WHERE qtr_num IN (3, 4)) AS q3q4_sales
FROM sales_fact f
LEFT OUTER JOIN time_dim t ON (f.time_id = t.month_id)
GROUP BY year
ORDER BY year;- Aggregation filters are evaluated after the main
WHEREclause of the query. - They provide a much cleaner alternative to writing separate subqueries or complex CASE expressions.
- You can combine multiple filtered aggregates in the same
SELECTlist.
- Use aggregation filters whenever you need different conditional totals in the same result set
- They are especially powerful for reporting, dashboards, and analytics queries
- Combine with
GROUP BYfor even more flexible breakdowns - Great for simplifying queries that previously required multiple CTEs or subqueries
Aggregation filters are a small but incredibly useful enhancement in Oracle AI Database 26ai. They make your SQL cleaner, more readable, and more performant by eliminating unnecessary subqueries and complex logic.
Whether you’re building reports, dashboards, or analytical applications, aggregation filters will quickly become one of your favorite new SQL features.
How to Create JSON-Relational Duality Views in Oracle AI Database 26ai
JSON-Relational Duality Views let you expose your relational tables as flexible JSON documents — and update them both ways — without any data duplication. Here’s a practical, step-by-step guide to creating them.
- Developers get simple JSON documents for modern apps
- DBAs keep normalized, relational tables for consistency and analytics
- Both views work on the exact same underlying data
-- 1. Create the underlying relational table
CREATE TABLE dept_tab (
deptno NUMBER(2,0) PRIMARY KEY,
dname VARCHAR2(14),
code NUMBER(13,0),
state VARCHAR2(15),
country VARCHAR2(15)
);
-- 2. Create the Duality View
CREATE JSON RELATIONAL DUALITY VIEW dept_dv AS
SELECT JSON { '_id' : d.deptno,
'deptName' : d.dname,
'location' : { 'zipcode' : d.code,
'country' : d.country }
FROM dept_tab d
WITH UPDATE INSERT DELETE;This view now supports clean JSON documents while the data stays normalized in the table.
More Complex Example: Orders with Nested DataCREATE OR REPLACE JSON RELATIONAL DUALITY VIEW orders_ov AS
SELECT JSON { '_id' : ord.order_id,
'orderTime' : ord.order_datetime,
'orderStatus' : ord.order_status,
'customerInfo' : (SELECT JSON { 'customerId' : cust.customer_id,
'customerName' : cust.full_name,
'customerEmail': cust.email_address }
FROM customers cust
WHERE cust.customer_id = ord.customer_id),
'orderItems' : (SELECT JSON_ARRAYAGG(
JSON { 'orderItemId' : oi.line_item_id,
'quantity' : oi.quantity,
'productInfo' : ...,
'shipmentInfo': ... }
)
FROM order_items oi
WHERE ord.order_id = oi.order_id)
}
FROM orders ord
WITH INSERT UPDATE DELETE;Use the WITH clause to control what operations are allowed:
WITH INSERT UPDATE DELETE— Fully updatable (default for root table)WITH NOINSERT NODELETE NOUPDATE— Read-only- You can override at column level:
WITH NOUPDATEorWITH UPDATE
- Every underlying table needs at least one identifying column (primary key, unique key, or identity column)
- Use nested subqueries for 1-to-N relationships → becomes a JSON array
- Use
UNNESTfor 1-to-1 relationships to merge into the same object - Supported column types include VARCHAR2, NUMBER, DATE, JSON, VECTOR, etc.
- Each duality view has a single
DATAcolumn of type JSON
Every document automatically includes:
{
"_metadata": {
"etag": "abc123...", -- for optimistic concurrency
"asof": 1234567890 -- system change number (SCN)
}
}- Start with simple single-table views to learn the pattern
- Use meaningful field names in JSON (not just column names)
- Combine with AI Vector Search or Private Agent Factory for powerful AI apps
- Always test updates through both the document view and relational tables
Creating JSON-Relational Duality Views is straightforward with a simple SQL statement. You get the best of both worlds: document flexibility for modern apps and relational power for analytics and integrity — all on the same data.
JSON-Relational Duality Views in Oracle AI Database: The Best of Documents and Tables
Oracle AI Database 26ai introduces **JSON-Relational Duality Views** — a powerful feature that lets you access the exact same data as either relational tables **or** JSON documents, without any data duplication or complex synchronization.
It gives you the flexibility of documents and the power of relational databases at the same time.
Why Duality Views Matter- Developers love JSON documents for their simplicity and hierarchy
- DBAs and analysts love relational tables for normalization, consistency, and analytics
- Duality views let both teams work on the **same underlying data** using whichever model fits their needs
A duality view is a declarative mapping between relational tables and JSON documents. The data is stored **relationally** (in tables), but you can read and write it as JSON documents — the database automatically handles the assembly and disassembly.
Changes made through the document view instantly appear in the tables, and vice versa.
Simple Example-- 1. Create the underlying relational table
CREATE TABLE dept_tab (
deptno NUMBER(2,0) PRIMARY KEY,
dname VARCHAR2(14),
code NUMBER(13,0),
state VARCHAR2(15),
country VARCHAR2(15)
);
-- 2. Create the Duality View
CREATE JSON RELATIONAL DUALITY VIEW dept_dv AS
SELECT JSON { '_id' : d.deptno,
'deptName' : d.dname,
'location' : { 'zipcode' : d.code,
'country' : d.country }
FROM dept_tab d
WITH UPDATE INSERT DELETE;This single view now supports a collection of JSON documents like this:
{
"_id" : 200,
"deptName" : "HR",
"location" : {
"zipcode" : 94065,
"country" : "USA"
}
}- Document-centric apps can use MongoDB API, ORDS, or SQL/JSON functions
- Relational apps can query the underlying tables directly with SQL
- No data duplication — everything stays normalized and consistent
- Full updatability (INSERT, UPDATE, DELETE) on the document side
- Multiple duality views can be built on the same tables for different use cases
- Some columns can be left unmapped (not exposed in JSON)
- You can store parts of the document as native JSON columns for maximum flexibility
- Fields can be generated automatically or hidden for internal use
- Views can be fully updatable, partially updatable, or read-only
- Use duality views for applications that need both flexible documents and strong relational integrity
- Start simple — map one or two tables first
- Leverage JSON columns for complex nested structures that don’t need normalization
- Combine with Oracle AI Vector Search, Private Agent Factory, or MCP Server for powerful AI use cases
JSON-Relational Duality Views eliminate the traditional trade-off between document and relational models. You get the best of both worlds in a single, high-performance, secure Oracle Database engine.
Whether you’re building modern microservices, AI-powered applications, or traditional enterprise systems, duality views give you maximum flexibility without compromising on data integrity or performance.
WAIT Clause for DMLs in 26.2
Oracle 26ai 26.2 now introduces the WAIT (and NOWAIT) Clause for INSERT / UPDATE / DELETE / MERGE DMLs. We have had a WAIT Clause for SELECT FOR UPDATE statements but not for these "simple" DML statements.
This is my Video Demo : Wait Clause for DMLs in 26.2
AI Enrichment in Oracle SQL Developer for VS Code: Make Your Database AI-Ready
Want your AI tools and LLMs to generate accurate SQL queries and truly understand your database? AI Enrichment lets you add business context, descriptions, and metadata to your schema — without changing any data or structure.
This powerful feature turns opaque database schemas into clear, AI-friendly assets.
What is AI Enrichment?AI Enrichment is the process of adding human-readable descriptions, synonyms, business context, and logical groupings to your database objects (schemas, tables, and columns).
It helps LLMs and AI agents understand the real meaning and relationships in your data, dramatically improving the quality of generated SQL and natural language responses.
Why AI Enrichment Matters- Raw table/column names (like T1, C123, EMP_ID) are ambiguous to LLMs
- Enrichment provides the missing business context
- Leads to more accurate, efficient, and trustworthy AI-generated queries
- Makes your database truly AI-ready for tools like Select AI, MCP Server, and Agent Factory
When you ask an AI tool a question, it automatically pulls your enrichment metadata and injects it into the prompt sent to the LLM. This gives the model rich context such as:
“The table EMPLOYEE contains current and former staff. EMP_ID is also known as employee number or worker id...” Getting Started Prerequisites- VS Code 1.101.0 or higher
- Oracle SQL Developer for VS Code 25.3.0 or higher
- Active connection to your Oracle Database
- User with
CREATE VIEW,CREATE TABLE,CREATE SEQUENCE,CREATE PROCEDUREprivileges
- Open your database connection in SQL Developer for VS Code
- Expand the connection → Click the AI Enrichment folder
- Click Yes to create the required metadata objects
The dashboard is your central command center. It shows:
- Schema-level description
- Table groups and enrichment percentage
- Intelligent suggestions for missing context
In the dashboard, add a high-level description under “About this schema”, for example:
This schema manages core HR processes including employees, departments, payroll, and benefits.Group related tables by business domain (e.g., “Employee Management”, “Payroll”, “Recruitment”). This helps LLMs understand logical relationships even without foreign keys.
3. Enrich Tables & Columns- Add clear natural language descriptions
- Create key-value annotations (synonyms, business rules, valid values, etc.)
- Mark tables as “Enrichment Complete” when done
- Start with the most important / frequently queried tables
- Use consistent, concise language in descriptions
- Add synonyms and common business terms as annotations
- Keep enrichment up-to-date as your schema evolves
- Use Table Groups to reflect real business domains
AI Enrichment is one of the highest-ROI steps you can take to make your Oracle Database truly intelligent and AI-ready. By investing a little time in adding context today, you unlock much more accurate and useful AI interactions tomorrow.
Whether you're using Select AI, MCP Server, Private Agent Factory, or any LLM-powered tool — enriched schemas deliver dramatically better results.
Oracle Database 26ai Client and SQLNET.EXPIRE_TIME
We have been facing one issue at one of our customer where the Oracle Client connections remained opened for days blocking some avaloq JobNetz. We have been doing some tests and we could fortunately find a solution resolving the problem thanks to Oracle Database 26ai supporting now SQLNET.EXPIRE_TIME on the client side. Through this blog, I would like to share with you the problem and then the tests that have been performed helping us to conclude to a solution.
Environment and problem descriptionAt our customer environment, client connection run from the HelperVM does not establish database connections directly to the database listener. The connection goes through the Network Load Balancer, so called NLB, and the Oracle Connection Manager, so called CMAN.
The diagram below describes the database connection establishment process.
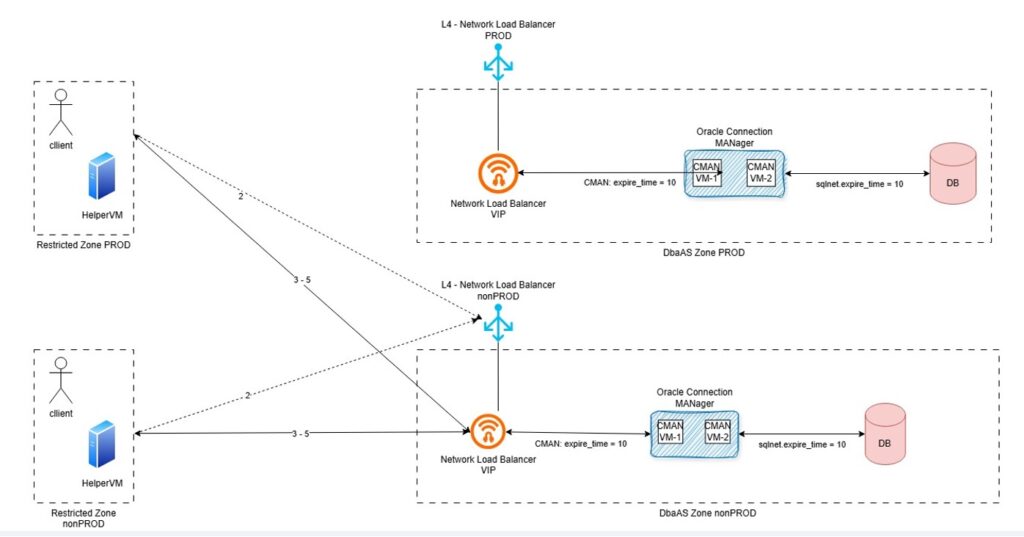
This is how it works.
- 1 – Client seeks for connection details (ideally, get the connection details from Oracle Directory Service)
- 2 – Client connects to Network Load Balancer
- 3 – Network Load Balancer “forwards” the request to Oracle Connection MANager using Virtual IP
- 4 – Oracle Connection MANager acts as a rule-based firewall and ensure the database target service is running on the “white listed targets (next_hop)
- 5 – Oracle Database establish connectivity upon credential validate (Oracle listener acts in between). The listener hands the connection over to the Oracle CMAN gateway process, which passes data back and forth between the client and the db-server and collects statistics.
We could observed per reverse engineering technique that the TCP connection established between the Oracle client and Oracle CMAN works upon Network Load Balancer Virtual IP.
The Network Load Balancer needs for Session persistence “statefullnes” to be enabled. This means that once the connection is established, the NLB “remembers” established connections and fails them over in case of planned downtime.
We have been facing some broken connectivity issue. Checking Linux socket connection with linux ss command (# ss -nop) we could see TCP connection hungs between client and NLB virtual IP (CNAME DNS entry). On CMAN and DB-Server side the connection were already cleaned up as per Dead Connection Detection configuration. We can see in the diagram that EXPIRE_TIME is setup with a value of 10 minutes on the CMAN side and the listener configuration from the VM Cluster database.
The connection was still opened on the client side because:
- The client was still waiting on a result which would never come
- TCP connection to the NLB Virtual IP was still existing albeit closed with the CMAN and database listener
- TCP connection to the NLB would remain alive for days
The problem is that by default Oracle client does not enable TCP Keepalive, which is an expected behavior. Oracle expects the keepalive to be set on the server side. The “Dead Connection Detection” will then be enforced for all clients.
TCP Keepalive should then be managed in our case on the client side. And we are currently running Oracle 19c Client.
EXPIRE_TIME handled on Oracle 19c ClientOracle 19c client does not come with SQLNET.EXPIRE_TIME aka “Oracle dead connection detection”, unless hacked over connection string hidden (unsupported) parameter ENABLE_BROKEN.
See following blog from a one of my former colleagues:
sqlnet-expire_time and enablebroken
And what about Oracle 26ai Client? Let’s do some test…
Installation of Oracle 26ai ClientOn the lab, I will use the VM called bastion to act as the client. The bastion has already an Oracle 19c Client installed. I’m going to installed new Oracle 26ai Client on it.
First we need to download the client version, which can be done from the following website:
https://www.oracle.com/database/technologies/oracle26ai-linux-downloads.html
I will install Oracle 26ai Client version in /opt/oracle.
[root@bastion oracle]# pwd /opt/oracle [root@bastion oracle]# ls -ld client* drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c [root@bastion oracle]#
I will first unzip the downloaded oracle zip file.
[oracle@bastion oracle]$ pwd /opt/oracle [oracle@bastion oracle]$ unzip -q LINUX.X64_2326100_client.zip
I will then rename the client installation directory:
[oracle@bastion oracle]$ ls -ld client* drwxr-xr-x. 5 oracle oinstall 90 Jan 17 13:59 client drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c [oracle@bastion oracle]$ mv client client26ai [oracle@bastion oracle]$ [oracle@bastion oracle]$ ls -ld client* drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c drwxr-xr-x. 5 oracle oinstall 90 Jan 17 13:59 client26ai [oracle@bastion oracle]$
I will prepare the response file for the command line installation.
[oracle@bastion client26ai]$ cp -p response/client_install.rsp response/client_install_custom.rsp [oracle@bastion client26ai]$ vi response/client_install_custom.rsp [oracle@bastion client26ai]$ diff response/client_install.rsp response/client_install_custom.rsp 22c22 UNIX_GROUP_NAME=oinstall 26c26 INVENTORY_LOCATION=/opt/oracle/oraInventory 30c30 ORACLE_HOME=/opt/oracle/client26ai 34c34 ORACLE_BASE=/opt/oracle 48c48 oracle.install.client.installType=Administrator [oracle@bastion client26ai]$
And I will run the Oracle 26ai Client installation.
[oracle@bastion client26ai]$ pwd /opt/oracle/client26ai [oracle@bastion client26ai]$ ls -ltrh total 24K -rwxrwx---. 1 oracle oinstall 500 Feb 6 2013 welcome.html -rwxr-xr-x. 1 oracle oinstall 8.7K Jan 17 12:38 runInstaller drwxr-xr-x. 4 oracle oinstall 4.0K Jan 17 12:38 install drwxr-xr-x. 15 oracle oinstall 4.0K Jan 17 13:37 stage drwxr-xr-x. 2 oracle oinstall 82 May 21 16:13 response [oracle@bastion client26ai]$ ./runInstaller -silent -responseFile /opt/oracle/client26ai/response/client_install_custom.rsp Starting Oracle Universal Installer... Checking Temp space: must be greater than 415 MB. Actual 5025 MB Passed Checking swap space: must be greater than 150 MB. Actual 4095 MB Passed Preparing to launch Oracle Universal Installer from /tmp/OraInstall2026-05-21_04-16-17PM. Please wait ... [WARNING] [INS-32016] The selected Oracle home contains directories or files. ACTION: To start with an empty Oracle home, either remove its contents or specify a different location. ********************************************* Package: compat-openssl10-1.0.2 (x86_64): This is a prerequisite condition to test whether the package "compat-openssl10-1.0.2 (x86_64)" is available on the system. Severity: IGNORABLE Overall status: VERIFICATION_FAILED Error message: PRVF-7532 : Package "compat-openssl10(x86_64)-1.0.2" is missing on node "bastion" Cause: A required package is either not installed or, if the package is a kernel module, is not loaded on the specified node. Action: Ensure that the required package is installed and available. ----------------------------------------------- [WARNING] [INS-13014] Target environment does not meet some optional requirements. CAUSE: Some of the optional prerequisites are not met. See logs for details. /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log. ACTION: Identify the list of failed prerequisite checks from the log: /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log. Then either from the log file or from installation manual find the appropriate configuration to meet the prerequisites and fix it manually. The response file for this session can be found at: /opt/oracle/client26ai/install/response/client_2026-05-21_04-16-17PM.rsp You can find the log of this install session at: /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log The installation of Oracle Client 26ai was successful. Please check '/opt/oraInventory/logs/silentInstall2026-05-21_04-16-17PM.log' for more details. Successfully Setup Software with warning(s). [INS-10115] All configuration tools were previously ran successfully, no further configuration is required. [oracle@bastion client26ai]$
And the Oracle 26ai Client is now installed.
Prepare target databaseI will create a user on the target lab PDB, named TESTZ_TMR_003I, in order to establish sqlplus connection and test the EXPIRE_TIME configuration.
I will create a user test01 and grant the connect permissions.
[oracle@svl-oat ~]$ echo $ORACLE_SID
CDB001I
[oracle@svl-oat ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu May 21 14:30:39 2026
Version 19.23.0.0.0
Copyright (c) 1982, 2023, Oracle. All rights reserved.
Connected to:
Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production
Version 19.23.0.0.0
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 TESTZ_APP_006I READ WRITE NO
4 RCLON_TMR_003I MOUNTED
5 RCLON_TMR_002I MOUNTED
6 RCLON_TMR_001I MOUNTED
7 CLONZ_TMR_002I MOUNTED
8 TESTZ_TMR_003I READ WRITE NO
10 TESTZ_APP_004I READ WRITE NO
11 CLONZ_APP_001I READ WRITE NO
12 RCLON_APP_003I READ WRITE NO
SQL> alter session set container=TESTZ_TMR_003I;
Session altered.
SQL> create user test01 identified by "test_expire";
User created.
SQL> grant connect to test01;
Grant succeeded.
SQL>
Test connection with Oracle 26ai Client
I will first set the ORACLE_HOME variable on the appropriate client directory.
[oracle@bastion client26ai]$ echo $ORACLE_HOME /opt/oracle/client19c [oracle@bastion client26ai]$ export ORACLE_HOME=/opt/oracle/client26ai [oracle@bastion client26ai]$ echo $ORACLE_HOME /opt/oracle/client26ai [oracle@bastion client26ai]$
I will update the PATH variable to get tnsping and sqlplus binary from the appropriate Oracle 26ai Client.
[oracle@bastion client26ai]$ echo $PATH /usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/oracle/client19c/bin:/opt/oracle/sqlcl-24.1.0.087.0929//bin [oracle@bastion client26ai]$ export PATH=/opt/oracle/client26ai/bin [oracle@bastion client26ai]$ echo $PATH /opt/oracle/client26ai/bin [oracle@bastion client26ai]$
I will check that the appropriate tnsping and sqlplus is taken.
[oracle@bastion client26ai]$ which sqlplus /opt/oracle/client26ai/bin/sqlplus [oracle@bastion client26ai]$ which tnsping /opt/oracle/client26ai/bin/tnsping
I checked that the connection to target PDB is working.
[oracle@bastion ~]$ tnsping svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com TNS Ping Utility for Linux: Version 23.26.1.0.0 - Production on 21-MAY-2026 16:28:56 Copyright (c) 1997, 2026, Oracle. All rights reserved. Used parameter files: /opt/oracle/client19c/network/admin/sqlnet.ora Used EZCONNECT adapter to resolve the alias Attempting to contact (DESCRIPTION=(CONNECT_DATA=(SERVICE_NAME=testz_tmr_003i.db.jewlab.oraclevcn.com))(ADDRESS=(PROTOCOL=tcp)(HOST=X.X.1.135)(PORT=1521))) OK (0 msec) [oracle@bastion ~]$
The TNS_ADMIN used is from the 19c Oracle client directory, which is absolutely not a problem.
[oracle@bastion ~]$ echo $TNS_ADMIN /opt/oracle/client19c/network/admin [oracle@bastion ~]$Test sqlplus connection with Oracle 26ai Client
As I can see on my client side, I do not have any sqlplus connection running right now.
[opc@bastion ~]$ ss -nop | grep 1521 [opc@bastion ~]$
I will generate a sqlplus connection.
[oracle@bastion client26ai]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:34:23 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And I can see that I have got a sqlplus connection with no timer/keepalive.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:51404 X.X.1.135:1521 [opc@bastion ~]$
I will now configure Oracle Dead Connection Detection with SQLNET.EXPIRE_TIME parameter set in the client sqlnet.ora with a value of 1 minute.
[oracle@bastion ~]$ cd $TNS_ADMIN [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora [oracle@bastion admin]$ [oracle@bastion admin]$ /usr/bin/vi sqlnet.ora [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora SQLNET.EXPIRE_TIME=1 [oracle@bastion admin]$
I will run a new sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:41:06 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:34:23 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
I can now see that I have got a connection configured with a timer and keep alive remaining of 38s.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:62868 X.X.1.135:1521 timer:(keepalive,38sec,0) [opc@bastion ~]$
Let’s configure the EXPIRE_TIME with a value of 15 minutes.
[oracle@bastion admin]$ /usr/bin/vi sqlnet.ora [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora SQLNET.EXPIRE_TIME=15
I run a new sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:43:25 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:42:29 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And I now have got a connection configured with a timer and keep alive remaining of 14min.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:60630 X.X.1.135:1521 timer:(keepalive,14min,0) [opc@bastion ~]$
So, all good Oracle 26ai Client is supporting Dead Connection Detection with SQLNET.EXPIRE_TIME parameter.
Let’s test it with Oracle 19c ClientWe can easily confirm again that Oracle 19c Client does not support Dead Connection Detection on the client side.
Let’s move back to Oracle 19c Client home.
[oracle@bastion admin]$ export PATH=/opt/oracle/client19c/bin [oracle@bastion admin]$ which sqlplus /opt/oracle/client19c/bin/sqlplus
Run a sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 19.0.0.0.0 - Production on Thu May 21 16:48:09 2026 Version 19.3.0.0.0 Copyright (c) 1982, 2019, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:46:07 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And check connection configuration.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:64078 X.X.1.135:1521 [opc@bastion ~]$
There is no timer/keepalive handled with Oracle 19c Client.
To wrap up…Oracle Database 26ai Client is now supporting Dead Connection Detection on the client side. For our customer configuration this will help the client to check every X minutes (EXPIRE_TIME configured value) for Dead Connection. So if the CMAN and listener connections have already died and if for any reason the Network Load Balancer is still keeping the connection with the client, the client will close the connection after X minutes.
L’article Oracle Database 26ai Client and SQLNET.EXPIRE_TIME est apparu en premier sur dbi Blog.
Azure Bootcamp Switzerland 2026 edition
Today I attended the Azure Bootcamp Switzerland event in Bern. Here is a summary of what I saw and what I learned in the sessions.

The opening keynote was about Azure Sovereign Architecture where the presenter gave us an update on the current Azure/Microsoft projects. We also had an explanation on how sovereignty works.
Then I joined a session titled “Time Bombs In Entra ID – How Well Are Your Entra ID Apps Managed?”. The speaker explained to us how Azure App registration and service principal really work. He also gave us some advice on best practices when using this kind of Azure/Entra resource.
Before the lunch break I joined a session on how some architects resolved the “multiple teams needed to deploy something” problem. They automated the deployment with CI/CD and Terragrunt. They did a demo on how they use their code and how they make infrastructure changes with it.
After the lunch, I chose to go in a more network oriented presentation. The topic was how to get rid of VPN by using an Azure service called Global Secure Access. Even though I’m not convinced that we can get rid of VPNs, this option could be something for highly Microsoft infrastructure as it uses the Microsoft backbone for all the network routing.

The last two sessions I attended sessions on Azure Policy. The topics were first using code to deploy Azure policies, as it’s a better way to have them identical in multiple environments and as it as also faster than using the Azure interface, which is slow. The second one was about using conditional access as safer alternative for securing Azure tenants with policies. This method is quite interesting but requires a paid version of Entra to be activated.

Finally, for the closing keynote, we had a presentation about an application developed by a Swiss company that helps emergency services coordinate. It’s allowing call centers to locate and contact closest to scene savers and organize their deployment.

Once again, I’m glad that could attend this event. I learned quite a bunch of things and could also refresh my memory on some other topics. The sessions are long enough to detail a topic and the speakers are always performing well.
L’article Azure Bootcamp Switzerland 2026 edition est apparu en premier sur dbi Blog.
Reduce downtime when refreshing your non-production databases using Multitenant
You probably refresh your non-production Oracle databases with production data from time to time or on a regular basis. Without Multitenant, the most common procedure to do this refresh is a DUPLICATE FROM BACKUP with RMAN. The drawback is the unavailability of the database being refreshed during the DUPLICATE. You first need to remove the old version of the database, then start the DUPLICATE and wait until it’s finished. If you have Enterprise Edition and enough CPU, you can lower the time needed for the refresh by allocating a sufficient number of channels. But with a small number of CPU (which is normal for a non-production server), or eventually with Standard Edition (single channel RMAN operations only), a multi-TB database refresh can take several hours to complete. And if it fails for some reasons, you need to retry the refresh, extending even more the downtime.
Multitenant brought new possibilities for refreshing a database, and my favorite one is a CREATE PLUGGABLE DATABASE from a database link (DB link). It’s dead easy compared to a DUPLICATE FROM BACKUP on a non-CDB database. And you can lower the downtime to the very minimum. Here is how I did this for several projects.
How to lower the downtime to the minimum when refreshing a non-production PDB?You probably know that one of the advantage of a pluggable database is the easiness of changing its name. You just need to stop the PDB, rename it, and restart it. You can then use this technique to refresh a PDB under a temporary name and let the actual PDB available during the refresh. Once the refresh is finished, drop or rename the actual PDB, and rename the newest one to its target name. Even if your refresh takes hours, your downtime is limited to a couple of seconds/minutes.
Step 1: add an additional grant for source PDB’s administratorThe PDB administrator on the source database must have the CREATE PLUGGABLE DATABASE privilege:
ssh oracle@p01-srv-ora
. oraenv <<< P19PMT
sqlplus / as sysdba
Alter session set container=P19_ERP;
grant create pluggable database to SYSERP;
exitThe target server must have a TNS entry to the source PDB (production). If your source PDB and its container are protected by a Data Guard configuration, dont’t forget to add both addresses:
ssh root@t01-srv-ora
su – oracle
. oraenv <<< D19PMT
vi $ORACLE_HOME/network/admin/tnsnames.ora
…
P19_ERP =
(DESCRIPTION =
(LOAD_BALANCE = OFF)
(FAILOVER = ON)
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = p01-srv-ora)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = p02-srv-ora)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = P19_ERP)
)
)
tnsping P19_ERP
…
A DB link is required on the target container:
ssh root@t01-srv-ora
su – oracle
. oraenv <<< D19PMT
sqlplus / as sysdba
CREATE DATABASE LINK P19_ERP CONNECT TO SYSERP IDENTIFIED BY "*************" USING 'P19_ERP';
select count(*) from dual@P19_ERP;
COUNT(*)
----------
1
exitBasically, refresh will have 5 main tasks:
- create a new PDB with a temporary name _NEW on the target container from the source PDB
- start the new PDB for its correct registration in the container
- run an optional script for modifying production data (masking, disabling tasks, …)
- stop and rename the current PDB to _OLD, then start it again
- stop and rename the new PDB to its target name and start it again
Task 2 is needed because you cannot rename a PDB immediately after creation. You first need to open it, then close it for being able to change its name.
Let’s create 2 scripts on the target server, one shell script and one SQL script:
vi /home/oracle/scripts/refresh_D19_ERP.sh
#!/bin/bash
export ORACLE_SID=D19PMT
export REFRESH_LOG=/home/oracle/scripts/log/refresh_D19_ERP_`date +%d_%m_%Y-%H_%M_%S`.log
export ORACLE_HOME=`cat /etc/oratab | grep $ORACLE_SID | awk -F ':' '{print $2;}'`
date >> $REFRESH_LOG
$ORACLE_HOME/bin/sqlplus / as sysdba @/home/oracle/scripts/refresh_D19_ERP.sql >> $REFRESH_LOG
date >> $REFRESH_LOG
exit 0
vi /home/oracle/scripts/refresh_D19_ERP.sql
set timing on
show pdbs
alter pluggable database D19_ERP_OLD close immediate;
Drop pluggable database D19_ERP_OLD including datafiles;
show pdbs
create pluggable database D19_ERP_NEW from P19_ERP@P19_ERP ;
show pdbs
alter pluggable database D19_ERP_NEW open;
show pdbs
alter session set container=D19_ERP_NEW;
@/home/oracle/scripts/post_refresh_D19_ERP.sql
alter session set container=CDB$ROOT;
alter pluggable database D19_ERP close immediate;
alter pluggable database D19_ERP rename global_name to D19_ERP_OLD;
alter pluggable database D19_ERP_OLD open;
show pdbs
alter pluggable database D19_ERP_NEW close immediate;
alter pluggable database D19_ERP_NEW rename global_name to D19_ERP;
Alter pluggable database D19_ERP open;
Alter pluggable database D19_ERP save state;
show pdbs
exitIt does the job, although these are very basic scripts: further controls could be added to trap errors, manage services, and so on.
Step 5 : schedule the refreshScheduling can be done through the crontab, for example every evening at 11.30PM:
crontab -l | grep D19_ERP | grep refresh
30 23 * * * sh /home/oracle/scripts/refresh_D19_ERP.sh
This is definitely a smart solution as soon as you have enough space on disk to have 2 copies of the PDB. It’s quite reliable and ticks all the boxes where I deployed these scripts.
L’article Reduce downtime when refreshing your non-production databases using Multitenant est apparu en premier sur dbi Blog.
OGG-08502 Path not found error from OGG Receiver Service
Recently, after a successful migration to GoldenGate 26ai, a customer complained that he was seeing a lot of the following error in the ggserr.log file of a GoldenGate deployment (I replaced the names for the purpose of this blog).
2026-05-18T14:32:35.948+0200 ERROR OGG-08502. Oracle GoldenGate Receiver Service for Oracle: Path path21 not found.More precisely, in that case, path21 is a distribution path sending trail files from deployment ogg_test_02 to ogg_test_01. And the error shown above appeared in the log file of the ogg_test_01 deployment.
While this error did not seem to indicate any operational issue in the replication, after checking on multiple environments, I confirmed that it appears everywhere. So what is happening exactly ?
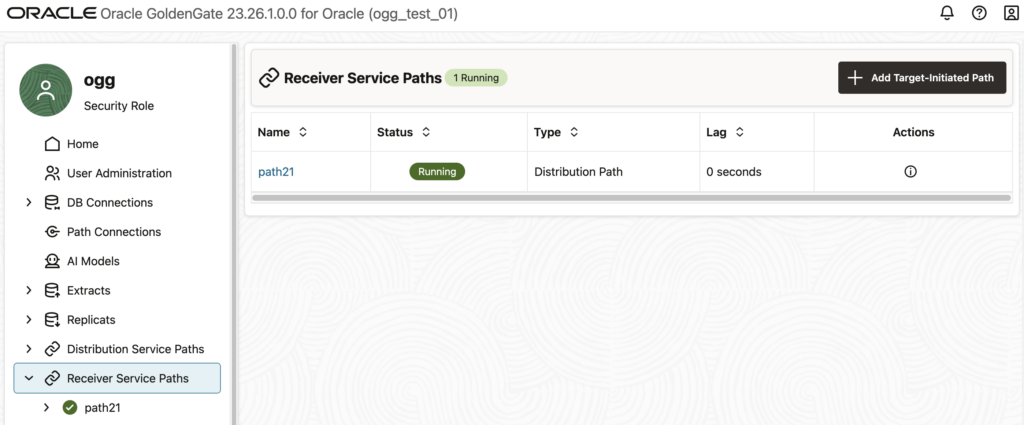
If you get this error and do not know where it comes from, log in to the web UI of the affected deployment, and go to the Receiver Service Paths tab. You should see a list of the distribution paths that are connecting to your deployments. The example below shows the path21 that is mentioned in the error.
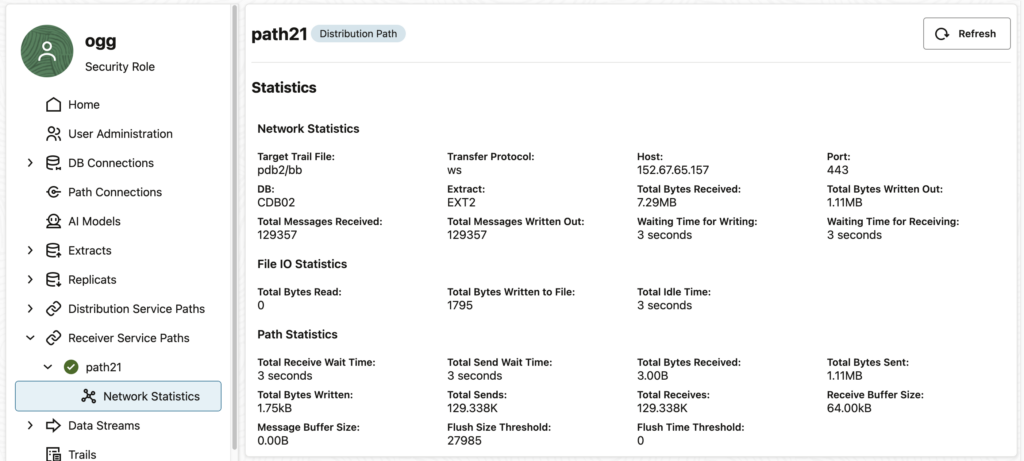
If you click on this path… Nothing happens ! And by “nothing”, I mean “nothing abnormal”. In fact, the statistics are properly displayed (see below), and there is no error shown to the user. However, if you look at your ggserr.log file you will see that the error given above appears.
At first glance, this might not seem like a huge issue, because if you don’t click on the receiver path, you will not get the error. However, in the log file of the customer, the error appeared regularly. Every minute, to be precise.
Why do I get this error even when I’m not accessing the web UI ?Luckily, when debugging this issue, I started by putting the target in a blackout in the Oracle Enterprise Manager. To my surprise, the error was gone during the blackout and reappeared right after.
In this case, the Enterprise Manager Plug-in for Oracle GoldenGate is monitoring the status of the deployment every minute and generates the error in the process.
When looking at the targets in the OEM, there is no error. Again, no operational impact.
Does it depend on the way you create the distribution path ?GoldenGate offers multiple ways of managing deployments : REST API, adminclient, or the web UI. Unfortunately, some bugs (and some features…) mean that you should avoid managing some objects with some of these tools (read why you shouldn’t create profiles through the adminclient, for instance).
In this specific case, all distribution path creation methods lead to the same error in the log file. It doesn’t matter whether you create the distribution path with the adminclient, the REST API or the web UI. They will all lead to this error.
Let’s dig a bit to see what is happening behind the scenes. By looking at the restapi.log file (read my blog on how to analyze REST API logs efficiently), we can see the full error:
2026-05-18 09:08:58.402+0000 ERROR|RestAPI.recvsrvr | Request #9: {
"context": {
"httpContextKey": 140097141801744,
"verbId": 2,
"verb": "GET",
"originalVerb": "GET",
"uri": "/services/v2/targets/path21",
"protocol": "http",
"headers": {
...
},
"host": "vmogg",
"securityEnabled": false,
"authorization": {
"authUserName": "ogg",
"authUserRole": "Security",
"authMode": "Cookie"
},
"requestId": 8,
"uriTemplate": "/services/{version}/targets/{path}",
"catalogUriTemplate": "/services/{version}/metadata-catalog/path"
},
"isScaRequest": true,
"content": null,
"parameters": {
"uri": {
"path": "path21",
"version": "v2"
},
"query": {
"WindowRef": "%2Fservices%2Fv2%2Fcontent%2F%23%2FrecvsrvrPaths%2Fpath21%2FpathNetworkStats"
}
}
}
Response: {
"context": {
...
},
"isScaResponse": true,
"content": {
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21",
"mediaType": "application/json"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21",
"mediaType": "application/json"
}
],
"messages": [
{
"$schema": "ogg:message",
"title": "Path path21 not found",
"code": "OGG-08502",
"severity": "ERROR",
"issued": "2026-05-18T09:08:58Z",
"type": "https://www.rfc-editor.org/rfc/rfc9110.html#name-status-codes"
}
]
}
}The issue comes from the following endpoint : /services/v2/targets/path21. It is described in the documentation under Retrieve an existing Oracle GoldenGate Collector Path. But looking at another endpoint described in Get a list of distribution paths, we get the following response:
{
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "text/html"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "text/html"
},
{
"rel": "describedby",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/metadata-catalog/targets",
"mediaType": "application/schema+json"
}
],
"messages": [],
"response": {
"$schema": "ogg:collection",
"items": [
{
"links": [
{
"rel": "parent",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "application/json"
},
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "application/json"
}
],
"$schema": "ogg:collectionItem",
"name": "path21",
"status": "running",
"targetInitiated": false
}
]
}
}Here, we see that the endpoint associated with the path21 object is not recvsrvr/v2/targets/path21 but recvsrvr/v2/targets/path21_ogg26dist2_7811. And looking at this second endpoint, we do not get an error.
{
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "text/html"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "text/html"
},
{
"rel": "describedby",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/metadata-catalog/path",
"mediaType": "application/schema+json"
}
],
"messages": [],
"response": {
"name": "path21",
"status": "running",
"$schema": "ogg:distPath",
"source": {
"uri": "trail://localhost:7811/services/v2/sources?trail=pdb2/bb"
},
"target": {
"$schema": "ogg:distPathEndpoint",
"uri": "ws://vmogg/services/v2/targets?trail=pdb2/bb"
},
"options": {
"network": {
"appOptions": {
"appFlushBytes": 27985,
"appFlushSecs": 1
},
"socketOptions": {
"tcpOptions": {
"ipDscp": "DEFAULT",
"ipTos": "DEFAULT",
"tcpNoDelay": false,
"tcpQuickAck": true,
"tcpCork": false,
"tcpSndBuf": 16384,
"tcpRcvBuf": 131072
}
}
}
}
}
}The problem is that it was never decided for path21 to be referred to as path21_ogg26dist2_7811 internally. And it looks like GoldenGate does not know about it either… So until the bug is corrected, you will have to filter this OGG-08502 Path not found error out of the ggserr.log file if you use it for monitoring.
L’article OGG-08502 Path not found error from OGG Receiver Service est apparu en premier sur dbi Blog.
What being an external consultant really changes
When people think about consultants, they usually focus on expertise. “They bring experience, frameworks, and best practices.”
That’s true, of course. However, that is not the most impactful aspect of the role.
The real shift happens somewhere less visible: positioning. As an outsider, you don’t just join a team.
You become something different. Over time, I’ve come to think of it as operating within a “shadow team.”

This invisible layer changes how you navigate politics, truth, and influence.
Let’s unpack that.
As an employee, you’re clearly part of the organization.
However, when you’re an external consultant, it’s a different story.
You sit inside delivery teams while remaining outside the organization’s long-term structure. This dual positioning creates what I call a shadow team.
You collaborate closely with internal stakeholders, influence decisions without owning them, and observe dynamics that others are too immersed in to see.
You’re close enough to matter, yet distant enough to stay objective.
This reshapes everything.
Every organization has internal politics, including priorities, power structures, historical tensions, and unwritten rules. The larger the organization, the more politics there are.
Employees must live within that system.
Consultants, on the other hand, can often see the system more clearly because they aren’t fully bound by it.
This doesn’t mean you’re outside of politics, though.
It means:
You can identify misalignments more quickly, notice when decisions are driven by structure, not logic and spot friction between teams that others consider “normal.”
But here’s the key difference:
- You are less constrained by long-term consequences.
- An employee may avoid challenging a decision due to its potential impact on their career.
- However, a consultant can raise the concern because their role is to add clarity, not preserve equilibrium.
- Still, this doesn’t mean ignoring politics. It means navigating them consciously without being controlled by them.
One of the most powerful—and most fragile—assets of being an external consultant lies in the neutrality that people attribute to you.
You are not:
- Competing for a promotion
- Defending a department
- Protecting past decisions
This creates a rare opportunity. You can become a trusted bridge between stakeholders
When done right, people will:
- Share concerns they wouldn’t voice internally
- Ask for your opinion as a “safe” perspective
- Use you to validate or challenge ideas
However, neutrality is not automatic, it must be earned and can easily be lost.
You lose it when:
- You align too strongly with one stakeholder
- You start defending internal logic instead of questioning it
- You behave like an insider too quickly
The best consultants maintain a delicate balance:
They are close enough to build trust and distant enough to stay credible.
Truth vs. Diplomacy: walking the tightropeThis is where the role becomes truly challenging.
As a consultant, you are often expected to:
- Tell the truth
- Challenge assumptions
- Highlight risks
However, you are also expected to:
- Maintain relationships
- Respect stakeholders
- Keep the project moving forward
These two expectations often conflict with each other.
The naive approach: “Just be brutally honest.”
This approach quickly fails. Brutality destroys trust.
The safe approach: “Say what people want to hear.”
This makes you irrelevant.
The real skill is delivering truth in a way that can be heard.
That means:
- Frame issues in terms of impact, not fault.
- Ask questions instead of making accusations.
- Adapt your message to your audience.
For example, rather than saying, “This process isn’t working at all”
A more measured approach might be: “I see a few risks associated with this process. Could we go over them together?”
The observation is the same.
However, the outcome is different.
Being a consultant isn’t just about knowledge. It’s also about positioning. You have a clearer view, speak more freely, and connect across sides.
However, our profession is based on a paradox. We must be objective enough to provide sound advice, yet also be fully committed to the task at hand. Additionally, we must offer honest feedback without hurting the client’s feelings or losing their trust.
At dbi services, we’re passionate about striking that delicate balance, whether the subject is ECM or any other area of our expertise. Learn more about us here.
L’article What being an external consultant really changes est apparu en premier sur dbi Blog.
Instruction-Based Data Analysis with Sparrow and Local LLM
- Risk classification — categorize each position into low, medium, or high risk based on loss percentage
- Concentration risk — flag overweight positions above 20% portfolio weighting
- Portfolio aggregation — total valuation, weighted average P&L, best and worst performer