

XTended Oracle SQL

Parsing RTSM(Real-Time SQL Monitor) XML Reports
In the previous part, I forgot to mention one important detail: if you want to export or extract RTSM (Real-Time SQL Monitoring) reports directly in XML format for further analysis, you can simply use the following functions:
dbms_sql_monitor.report_sql_monitor_xml()ordbms_sqltune.report_sql_monitor_xml()— for reports still present ingv$sql_monitor.dbms_auto_report.report_repository_detail_xml()— for reports already stored in history (AWR), underdba_hist_reports.
To format these XML reports into TEXT, HTML, or Active HTML, you can use:
dbms_report.format_report(
report IN xmltype,
format_name IN varchar2
)
Setting format_name => 'ACTIVE' produces the Active HTML version.
The Main Topic: How to Parse RTSM XML Reports
Starting with Oracle 19.16, table SQL_MACROs became available, enabling a very elegant way to encapsulate XML parsing logic inside SQL macros.
For convenience, I updated the package PKG_RTSM and added the following SQL macro functions to parse various sections of an RTSM XML report:
- function rtsm_xml_macro_report_info(xmldata xmltype) return varchar2 SQL_MACRO;
- function rtsm_xml_macro_plan_info(xmldata xmltype) return varchar2 SQL_MACRO;
- function rtsm_xml_macro_plan_ops(xmldata xmltype) return varchar2 SQL_MACRO;
- function rtsm_xml_macro_plan_monitor(xmldata xmltype) return varchar2 SQL_MACRO;
(These declarations can be found in the package header in the uploaded source file pkg_rtsm.)
This means you can use them directly in SQL, for example:
select *
from pkg_rtsm.rtsm_xml_macro_plan_ops(:YOUR_XML_REPORT) ops;
rtsm_xml_macro_report_info
Returns the main metadata of the RTSM report, such as:
sql_id,sql_exec_id,sql_exec_startrep_date,inst_count,cpu_corescon_name, platform information, optimizer environment- SQL text, execution statistics, activity samples, and more
In addition, the function exposes two extremely useful columns:
DBMS_REPORT.FORMAT_REPORT(XMLDATA,'TEXT' ) as RTSM_REPORT_TEXT
DBMS_REPORT.FORMAT_REPORT(XMLDATA,'ACTIVE') as RTSM_REPORT_ACTIVE
These allow you to obtain the formatted TEXT or Active HTML version of the report directly from SQL without extra steps.
This logic is fully visible in the macro implementation in the package body.
2.rtsm_xml_macro_plan_info
Returns essential information about the execution plan, including:
has_user_tabdb_versionparse_schema- Full (adaptive) PHV and normal final plan hash value (
plan_hash_full,plan_hash,plan_hash_2) peeked_bindsxplan_statsqb_registryoutline_datahint_usage
This macro extracts the <other_xml> block attached to the root plan operation (id="1").
rtsm_xml_macro_plan_ops
Returns the full list of plan operations, including:
- operation id, name, options, depth, position
- object information
- cardinality, bytes, cost
- I/O and CPU cost
- access and filter predicates
This essentially exposes the plan as a SQL-friendly dataset.
4.rtsm_xml_macro_plan_monitor
This is the most important macro for analyzing performance metrics.
It returns all operations from the plan monitor section, together with all runtime statistics, including:
- starts, cardinality, memory usage, temp usage
- I/O operations and spilled data
- CPU and I/O optimizer estimates
- Monitoring timestamps (
first_active,last_active) - Activity samples by class (CPU, User I/O, Cluster, etc.)
Most importantly, it computes:
ROUND(100 * RATIO_TO_REPORT(NVL(wait_samples_total,0)) OVER (), 3)
AS TIME_SPENT_PERCENTAGE
This is an analogue of “Activity%” in the Active HTML report — showing what percentage of sampled activity belongs to each plan step.
The full implementation, with all xmltable parsing logic, is available in the uploaded code file pkg_rtsm.
You can download the latest version of the package here:
https://github.com/xtender/xt_scripts/blob/master/rtsm/parsing/pkg_rtsm.sql
Parsing Real-Time SQL Monitor (RTSM) ACTIVE Reports Stored as HTML
When you work with a large number of Real-Time SQL Monitor (RTSM) reports in the ACTIVE format (the interactive HTML report with JavaScript), it quickly becomes inconvenient to open them one by one in a browser. Very often you want to load them into the database, store them, index them, and analyze them in bulk.
Some RTSM reports are easy to process — for example, those exported directly from EM often contain a plain XML payload that can be extracted and parsed with XMLTABLE().
But most ACTIVE reports do not store XML directly.
Instead, they embed a base64-encoded and zlib-compressed XML document inside a <report> element.
These reports typically look like this:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<script ...>
var version = "19.0.0.0.0";
...
</script>
</head>
<body onload="sendXML();">
<script id="fxtmodel" type="text/xml">
<!--FXTMODEL-->
<report db_version="19.0.0.0.0" ... encode="base64" compress="zlib">
<report_id><![CDATA[/orarep/sqlmonitor/main?...]]></report_id>
eAHtXXtz2ki2/38+hVZ1a2LvTQwS4pXB1GJDEnYc8ALOJHdrSyVA2GwAYRCOfT/9
...
ffUHVA==
</report>
<!--FXTMODEL-->
</script>
</body>
</html>
At first glance it’s obvious what needs to be done:
- Extract the base64 block
- Decode it
- Decompress it with zlib
- Get the original XML
<sql_monitor_report>...</sql_monitor_report>
And indeed — if the database had a built-in zlib decompressor, this would be trivial.
Unfortunately, Oracle does NOT provide a native zlib inflate function.
UTL_COMPRESScannot be used — it expects Oracle’s proprietary LZ container format, not a standard zlib stream.- There is no PL/SQL API for raw zlib/DEFLATE decompression.
- XMLType, DBMS_CRYPTO, XDB APIs also cannot decompress zlib.
Because the RTSM report contains a real zlib stream (zlib header + DEFLATE + Adler-32), Oracle simply cannot decompress it natively.
Solution: use Java stored procedureThe only reliable way to decompress standard zlib inside the database is to use Java.
A minimal working implementation looks like this:
InflaterInputStream inflaterIn = new InflaterInputStream(in);
InflaterInputStream with default constructor expects exactly the same format that RTSM uses.
I created a tiny Java helper ZlibHelper that inflates the BLOB directly into another BLOB.
It lives in the database, requires no external libraries, and works in all Oracle versions that support Java stored procedures.
Source code: https://github.com/xtender/xt_scripts/blob/master/rtsm/parsing/ZlibHelper.sql
PL/SQL API: PKG_RTSM
On top of the Java inflater I wrote a small PL/SQL package that:
- Extracts and cleans the base64 block
- Decodes it into a BLOB
- Calls Java to decompress it
- Returns the resulting XML as CLOB
- Optionally parses it with
XMLTYPE
Package here:
pkg_rtsm.sql
https://github.com/xtender/xt_scripts/blob/master/rtsm/parsing/pkg_rtsm.sql
This allows you to do things like:
xml:=xmltype(pkg_rtsm.rtsm_html_to_xml(:blob_rtsm));
Or load many reports, store them in a table, and analyze execution statistics across hundreds of SQL executions.
Oracle Telegram Bot
For the Oracle performance tuning and troubleshooting Telegram channel https://t.me/ora_perf, I developed a simple helpful Telegram bot. It simplifies common Oracle database tasks directly within Telegram.
Here’s what the bot can do:
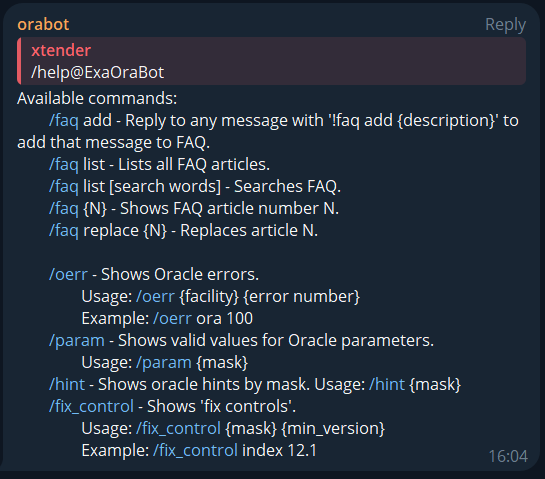 FAQ Management
FAQ Management
- /faq add: Reply with
!faq add {description}to save a message. - /faq list: Lists all FAQ articles.
- /faq list [search words]: Search FAQ by keywords.
- /faq {N}: Shows FAQ article number N.
- /faq replace {N}: Updates FAQ article N.
/oerr: Shows details of Oracle errors
/oerr ora 29024
29024, 00000, "Certificate validation failure"
// *Cause: The certificate sent by the other side could not be validated. This may occur if
// the certificate has expired, has been revoked, or is invalid for another reason.
// *Action: Check the certificate to determine whether it is valid. Obtain a new certificate,
// alert the sender that the certificate has failed, or resend.
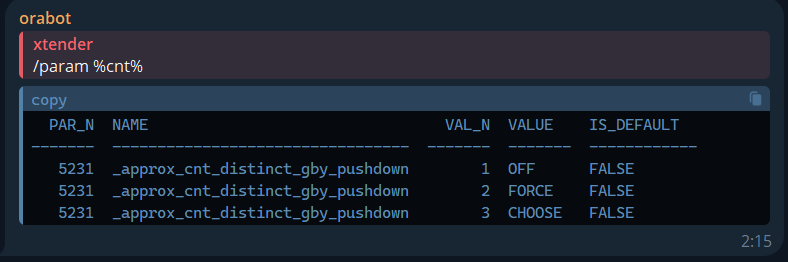
 Oracle Parameter Search
Oracle Parameter Search
/param: Finds Oracle parameters by mask.
/param %cnt%
PAR_N NAME VAL_N VALUE IS_DEFAULT
------- --------------------------------- ------- ------- ------------
5231 _approx_cnt_distinct_gby_pushdown 1 OFF FALSE
5231 _approx_cnt_distinct_gby_pushdown 2 FORCE FALSE
5231 _approx_cnt_distinct_gby_pushdown 3 CHOOSE FALSE
 Oracle Hints
Oracle Hints
/hint: Lists Oracle hints by mask
/hint 19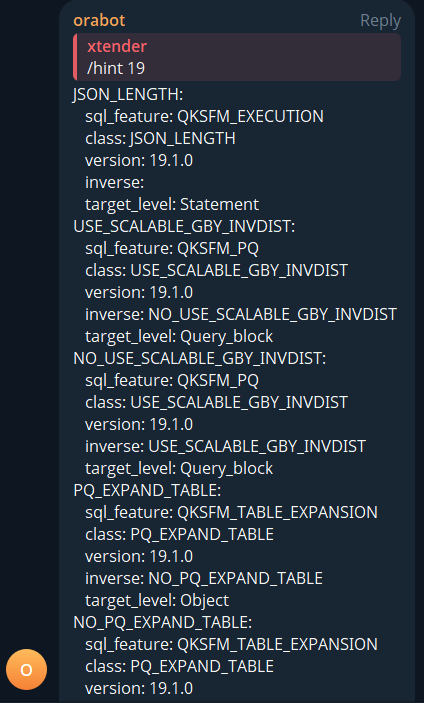
 Oracle Fix Controls
Oracle Fix Controls
/fix_control: Lists fix controls by keyword and version.
/fix_control count 8.1
BUGNO VALUE SQL_FEATURE DESCRIPTION OFE EVENT DEF
-------- ------- ------------------------------- ---------------------------------------------------------------- -------- ------- -----
16954950 1 QKSFM_ACCESS_PATH_16954950 take into account empty partitions when prorating cost 12.1.0.2 0 Y
3120429 1 QKSFM_ACCESS_PATH_3120429 account for join key sparsity in computing NL index access cost 10.1.0.3 0 Y
6897034 1 QKSFM_ACCESS_PATH_6897034 index cardinality estimates not taking into account NULL rows 10.2.0.5 0 Y
9456688 1 QKSFM_ACCESS_PATH_9456688 account for to_number/to_char cost after temp conversion 11.2.0.2 0 Y
14176203 1 QKSFM_CARDINALITY_14176203 Account for filter sel while computing join sel using histograms 11.2.0.4 0 Y
14254052 1 QKSFM_CARDINALITY_14254052 amend accounting for nulls in skip scan selectivity calculation 11.2.0.4 0 Y
16486095 1 QKSFM_CARDINALITY_16486095 Do not count predicate marked for no selectivity 12.2.0.1 0 Y
23102649 1 QKSFM_CARDINALITY_23102649 correction to inlist element counting with constant expressions 12.2.0.1 0 Y
11843512 1 QKSFM_CBO_11843512 null value is not accounted in NVL rewrite 11.2.0.3 0 Y
1403283 1 QKSFM_CBO_1403283 CBO do not count 0 rows partitions 8.1.6 10135 Y
22272439 1 QKSFM_CBO_22272439 correction to inlist element counting with bind variables 12.2.0.1 0 Y
25090203 1 QKSFM_CBO_25090203 account for selectivity of non sub subquery preds 18.1.0 0 Y
5483301 1 QKSFM_CBO_5483301 Use min repeat count in freq histogram to compute the density 10.2.0.4 0 Y
5578791 1 QKSFM_CBO_5578791 do not discount branch io cost if inner table io cost is already 11.1.0.6 0 Y
6694548 1 QKSFM_CBO_6694548 Account for chained rows when computing TA by ROWID from bitmap 10.2.0.4 0 Y
27500916 1 QKSFM_COMPILATION_27500916 only count one with clause reference from connect by 19.1.0 0 Y
10117760 1 QKSFM_CURSOR_SHARING_10117760 cardinality feedback should account for bloom filters 11.2.0.3 0 Y
9841679 1 QKSFM_CVM_9841679 do not set col count for OPNTPLS 11.2.0.3 0 Y
26585420 1 QKSFM_DBMS_STATS_26585420 cap approx_count_distinct with non nulls 18.1.0 0 Y
17760686 1 QKSFM_DYNAMIC_SAMPLING_17760686 Account for BMB blocks when dynamic sampling partitioned ASSM ta 12.1.0.2 0 Y
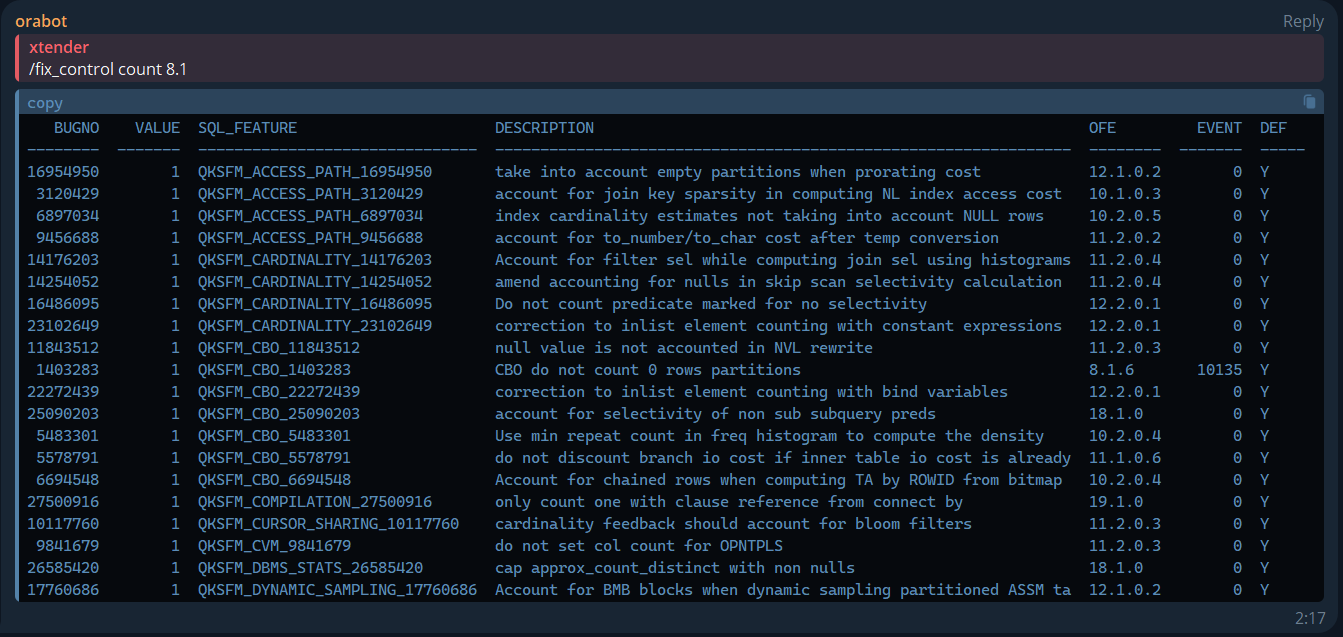
This bot helps streamline database maintenance and troubleshooting tasks. Join ora_perf to try it and share your feedback!
Partition Pruning and Global Indexes
There is a common misconception that partition pruning does not help in the case of global indexes and only works with local indexes or full table scans (FTS).
It is understandable how this misconception arose: indeed, when operations like PARTITION RANGE ITERATOR, PARTITION RANGE SINGLE, etc., appear in execution plans, partition pruning becomes strongly associated with local indexes and FTS.
It is also clear why this is the most noticeable case: the exclusion of partitions in PARTITION RANGE ITERATOR operations is hard to miss, especially since there is a dedicated line for it in the execution plan.
However, this is not all that partition pruning can do. In fact, this way of thinking is not entirely valid, and I will demonstrate this with some simple examples.
Table SetupLet’s assume we have a table tpart consisting of 3 partitions with the following columns:
pkey– the partitioning key. For simplicity, we will store only1,2, and3, with each value corresponding to a separate partition.notkey– a column for testing the global index, filled sequentially from 1 to 3000.padding– a long column used to make table block accesses more noticeable.
create table tpart (pkey int, notkey int,padding varchar2(4000))
partition by range(pkey)
(
partition p1 values less than (2)
,partition p2 values less than (3)
,partition p3 values less than (4)
);
We insert 3,000 rows into the table so that:
- Partition
p1contains1,000rows withpkey=1andnotkeyvalues from1to1000. - Partition
p2contains1,000rows withpkey=2andnotkeyvalues from1001to2000. - Partition
p3contains1,000rows withpkey=3andnotkeyvalues from2001to3000.
insert into tpart(pkey,notkey,padding)
select ceil(n/1000) pkey, n, rpad('x',4000,'x') from xmltable('1 to 3000' columns n int path '.');
commit;
SQL> select pkey,min(notkey),max(notkey) from tpart group by pkey order by 1;
PKEY MIN(NOTKEY) MAX(NOTKEY)
---------- ----------- -----------
1 1 1000
2 1001 2000
3 2001 3000
We start with a simple query that applies partition pruning. It should return nothing, since notkey values between 2500-2600 are in the third partition (pkey=3), but we explicitly specify pkey=1:
select count(*) from tpart where notkey between 2500 and 2600 and pkey=1;
SQL> select count(*) from tpart where notkey between 2500 and 2600 and pkey=1;
COUNT(*)
----------
0
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate');
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------
SQL_ID 0qzh3zxgpc65z, child number 0
-------------------------------------
select count(*) from tpart where notkey between 2500 and 2600 and pkey=1
Plan hash value: 3052279832
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 1007 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 1007 |
| 2 | PARTITION RANGE SINGLE| | 1 | 1 | 0 |00:00:00.01 | 1007 |
|* 3 | TABLE ACCESS FULL | TPART | 1 | 1 | 0 |00:00:00.01 | 1007 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(("NOTKEY">=2500 AND "NOTKEY"<=2600 AND "PKEY"=1))
Here, we can clearly see that partition pruning worked due to the PARTITION RANGE SINGLE operation.
Now, let’s create a global index on notkey (without including the partitioning key) and repeat the query:
SQL> create index ix_tpart on tpart(notkey);
Index created.
SQL> select count(*) from tpart where notkey between 2500 and 2600 and pkey=1;
COUNT(*)
----------
0
1 row selected.
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate');
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------------------------------
SQL_ID 0qzh3zxgpc65z, child number 0
-------------------------------------
select count(*) from tpart where notkey between 2500 and 2600 and pkey=1
Plan hash value: 494535298
---------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 2 | 1 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 2 | 1 |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| TPART | 1 | 1 | 0 |00:00:00.01 | 2 | 1 |
|* 3 | INDEX RANGE SCAN | IX_TPART | 1 | 102 | 101 |00:00:00.01 | 2 | 1 |
---------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PKEY"=1)
3 - access("NOTKEY">=2500 AND "NOTKEY"<=2600)
Here’s the key observation: the Buffers column for the second row remains 2, meaning there were no logical reads from the table despite that the execution plan suggests that here we had to access and filter out 101 rows from the partition by the filter predicate “filter(PKEY=1)”.
To verify, let’s run the same query with pkey=3:
select count(*) from tpart where notkey between 2500 and 2600 and pkey=3
Plan hash value: 494535298
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 103 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 103 |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| TPART | 1 | 102 | 101 |00:00:00.01 | 103 |
|* 3 | INDEX RANGE SCAN | IX_TPART | 1 | 102 | 101 |00:00:00.01 | 2 |
------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PKEY"=3)
3 - access("NOTKEY">=2500 AND "NOTKEY"<=2600)
Here, it is clearly visible that accessing 101 rows from the table required 101 logical reads.
Overall, it immediately becomes apparent that in the previous example with pkey=1, partition pruning worked and helped us avoid approximately 100 LIO to partition blocks. However, to make this even more evident, let’s modify the predicate "pkey=1" to a more complex equivalent that disables partition pruning: pkey=pkey/pkey.
SQL> select count(*) from tpart where notkey between 2500 and 2600 and pkey=pkey/pkey;
COUNT(*)
----------
0
1 row selected.
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate');
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------
SQL_ID 0q59p4akv4cm0, child number 0
-------------------------------------
select count(*) from tpart where notkey between 2500 and 2600 and pkey=pkey/pkey
Plan hash value: 4115825992
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 103 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 103 |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| TPART | 1 | 34 | 0 |00:00:00.01 | 103 |
|* 3 | INDEX RANGE SCAN | IX_TPART | 1 | 102 | 101 |00:00:00.01 | 2 |
------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PKEY"="PKEY"/"PKEY")
3 - access("NOTKEY">=2500 AND "NOTKEY"<=2600)
And voilà! Here we see 101 logical reads from the table in exactly the same query but with partition pruning disabled.
For clarity, let’s compare:
select count(*) from tpart where notkey between 2500 and 2600 and pkey=1; = 2 LIO
select count(*) from tpart where notkey between 2500 and 2600 and pkey=pkey/pkey; = 103 LIO
In fact, this could have been easily noticed if I had used format=ALL or ADVANCED, or at least included +predicate (that’s why I always suggest to use format=>’advanced -qbregistry’):
SQL> select count(*) from tpart where notkey between 2500 and 2600 and pkey=2;
COUNT(*)
----------
0
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate +partition');
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------
SQL_ID fw7yx554pvv4n, child number 0
-------------------------------------
select count(*) from tpart where notkey between 2500 and 2600 and pkey=2
Plan hash value: 494535298
----------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Pstart| Pstop | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 1 |00:00:00.01 | 2 |
| 1 | SORT AGGREGATE | | 1 | 1 | | | 1 |00:00:00.01 | 2 |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| TPART | 1 | 1 | 2 | 2 | 0 |00:00:00.01 | 2 |
|* 3 | INDEX RANGE SCAN | IX_TPART | 1 | 102 | | | 101 |00:00:00.01 | 2 |
----------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PKEY"=2)
3 - access("NOTKEY">=2500 AND "NOTKEY"<=2600)
As you can now easily see, the Pstart/Pstop columns appear in the plan. This indicates that partition pruning works in the TABLE ACCESS BY ROWID operation, as Oracle determines which partition a row belongs to based on its ROWID and automatically filters out those that do not satisfy our partition key condition.
At this point, it becomes clear why the title of this blog post is somewhat misleading—the key issue is not the global index but rather the TABLE ACCESS BY ROWID operation. This can be demonstrated in an even simpler way:
Let’s obtain the ROWID and object number for a row where notkey=2300:
SQL> select rowid,dbms_rowid.rowid_object(rowid) obj# from tpart where notkey=2300;
ROWID OBJ#
------------------ ----------
AAAU42AAMAAB9eNAAA 85558
Now, let’s query using this ROWID:
SQL> select pkey,notkey from tpart where rowid='AAAU42AAMAAB9eNAAA';
PKEY NOTKEY
---------- ----------
3 2300
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate +partition');
-------------------------------------
select pkey,notkey from tpart where rowid='AAAU42AAMAAB9eNAAA'
Plan hash value: 2140892464
-----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Pstart| Pstop | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 1 |00:00:00.01 | 1 | 1 |
| 1 | TABLE ACCESS BY USER ROWID| TPART | 1 | 1 | ROWID | ROWID | 1 |00:00:00.01 | 1 | 1 |
-----------------------------------------------------------------------------------------------------------------------
We see that Oracle determines from the ROWID which specific partition needs to be accessed, confirming that our row is in the partition where pkey=3.
Now, let’s add the predicate "pkey=1", which will make the row not satisfy the partition key condition:
SQL> select * from tpart where rowid='AAAU42AAMAAB9eNAAA' and pkey=1;
no rows selected
SQL> select * from dbms_xplan.display_cursor('','','allstats last +predicate +partition');
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 1br7yh35w3sdv, child number 0
-------------------------------------
select * from tpart where rowid='AAAU42AAMAAB9eNAAA' and pkey=1
Plan hash value: 3283591838
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Pstart| Pstop | A-Rows | A-Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 0 |00:00:00.01 |
|* 1 | TABLE ACCESS BY USER ROWID| TPART | 1 | 1 | 1 | 1 | 0 |00:00:00.01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PKEY"=1)
Here, it becomes absolutely clear that no logical reads occurred because partition pruning worked, and Oracle did not access the third partition. Instead, it checked the partition key condition and immediately rejected the rowid without accessing any blocks.
ConclusionThus, the key takeaway is not about indexes at all, but rather about TABLE ACCESS operations. Partition pruning can still be effective within TABLE ACCESS operations—even without any indexes or explicit PARTITION operations (PARTITION [RANGE|HASH|LIST] [ITERATOR|ALL|SINGLE], etc.).
This works because Oracle only needs to check which partition a given ROWID belongs to in order to filter out unnecessary partitions efficiently.
PS. Read more about non-partioned indexes and partition pruning in details in this great series from Richard Foote: https://richardfoote.wordpress.com/2018/10/09/hidden-efficiencies-of-non-partitioned-indexes-on-partitioned-tables-part-ii-aladdin-sane/
Interval Search: Part 4. Dynamic Range Segmentation – interval quantization
Forums, mailing lists, and StackOverflow are all great resources for Oracle performance discussions, but I’ve long thought it would be useful to have a dedicated online chat/group specifically for Oracle performance specialists. A place to share news, articles, and discuss performance issues. To test the waters, I’ve created a group: https://t.me/ora_perf. If you’re interested, feel free to join! Let’s build a central hub for Oracle performance discussions.
Before diving into the main topic, let me address a frequent question I’ve received regarding the earlier parts of this series:
“You’re focusing on the rare case of date-only indexes (begin_date, end_date), but most real-world scenarios involve composite indexes with an ID field, like (id, begin_date, end_date).“
Yes, it’s true that in practice, composite indexes with an ID field are more common. And exactly such scenarios was the reason of this series. However, I intentionally started with a simplified case to focus on the date filtering mechanics. All the issues, observations, conclusions, and solutions discussed so far are equally applicable to composite indexes.
For example, many production databases have identifiers that reference tens or even hundreds of thousands of intervals. The addition of an ID-based access predicate may reduce the scanned volume for a single query, but the underlying date range filtering issues remain. These inefficiencies often go unnoticed because people don’t realize their simple queries are doing tens of LIOs when they could be doing just 3-5, with response times reduced from 100 microseconds to 2 microseconds.
Even if your queries always use an equality predicate on the ID field, you’ll still encounter challenges with huge queries with joins, such as:
select *
from IDs
join tab_with_history h
on IDs.id = h.id
and :dt between h.beg_date and h.end_date
Here, lookups for each ID against the composite index can become inefficient at scale compared to retrieving a pre-filtered slice for the target date.
To clarify, everything discussed in this series applies to composite indexes as well. The solutions can easily be extended to include ID fields by modifying just a few lines of code. Let’s now move to the main topic.
Dynamic Range Segmentation – Interval QuantizationIn the earlier parts, you may have noticed a skew in my test data, with many intervals of 30 days generated for every hour. This naturally leads to the idea of reducing scan volume by splitting long intervals into smaller sub-intervals.
What is Interval Quantization?Interval quantization is a known solution for this problem, but it often comes with drawbacks. Traditional quantization requires selecting a single fixed unit (e.g., 1 minute), which may not suit all scenarios. Using a small unit to cover all cases can lead to an explosion in the number of rows.
However, since Dynamic Range Segmentation (DRS) already handles short intervals efficiently, we can focus on quantizing only long intervals. For this example, we’ll:
- Leave intervals of up to 1 hour as-is, partitioning them into two categories: up to 15 minutes and up to 1 hour.
- Split longer intervals into sub-intervals of 1 day.
To simplify the splitting of long intervals, we’ll write a SQL Macro:
create or replace function split_interval_by_days(beg_date date, end_date date)
return varchar2 sql_macro
is
begin
return q'{
select/*+ no_decorrelate */
case
when n = 1
then beg_date
else trunc(beg_date)+n-1
end as sub_beg_date
,case
when n<=trunc(end_date)-trunc(beg_date)
then trunc(beg_date)+n -1/24/60/60
else end_date
end as sub_end_date
from (select/*+ no_merge */ level n
from dual
connect by level<=trunc(end_date)-trunc(beg_date)+1
)
}';
end;
/
Source on github: https://github.com/xtender/xt_scripts/blob/master/blog/1.interval_search/drs.v2/split_interval_by_days.sql
This macro returns sub-intervals for any given range:
SQL> select * from split_interval_by_days(sysdate-3, sysdate);
SUB_BEG_DATE SUB_END_DATE
------------------- -------------------
2024-12-17 02:30:34 2024-12-17 23:59:59
2024-12-18 00:00:00 2024-12-18 23:59:59
2024-12-19 00:00:00 2024-12-19 23:59:59
2024-12-20 00:00:00 2024-12-20 02:30:34
ODCIIndexCreate_pr
We’ll modify the partitioning structure:
partition by range(DURATION_MINUTES)
(
partition part_15_min values less than (15)
,partition part_1_hour values less than (60)
,partition part_1_day values less than (1440) --40*24*60
)
We’ll use the SQL Macro to populate the index table with split intervals:
-- Now populate the table.
stmt2 := q'[INSERT INTO {index_tab_name} ( beg_date, end_date, rid )
SELECT SUB_BEG_DATE as beg_date
,SUB_END_DATE as end_date
,P.rowid
FROM "{owner}"."{tab_name}" P
, split_interval_by_days(
to_date(substr(P.{col_name}, 1,19),'YYYY-MM-DD HH24:MI:SS')
,to_date(substr(P.{col_name},21,19),'YYYY-MM-DD HH24:MI:SS')
)
]';
ODCIIndexInsert_pr
procedure ODCIIndexInsert_pr(
ia sys.ODCIIndexInfo,
rid VARCHAR2,
newval VARCHAR2,
env sys.ODCIEnv
)
IS
BEGIN
-- Insert into auxiliary table
execute immediate
'INSERT INTO '|| get_index_tab_name(ia)||' (rid, beg_date, end_date)'
||'select
:rid, sub_beg_date, sub_end_date
from split_interval_by_days(:beg_date, :end_date)'
using rid,get_beg_date(newval),get_end_date(newval);
END;
ODCIIndexStart_Pr
Update the SQL statement to account for the new partitions:
stmt := q'{
select rid from {tab_name} partition (part_15_min) p1
where :cmpval between beg_date and end_date
and end_date < :cmpval+interval'15'minute
union all
select rid from {tab_name} partition (part_1_hour) p2
where :cmpval between beg_date and end_date
and end_date < :cmpval+1/24
union all
select rid from {tab_name} partition (part_1_day ) p3
where :cmpval between beg_date and end_date
and end_date < :cmpval+1
}';
SQL> select count(*) from test_table where DATE_IN_RANGE(virt_date_range,date'2012-02-01')=1;
COUNT(*)
----------
943
SQL> @last
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID 17wncu9ftfzf6, child number 0
-------------------------------------
select count(*) from test_table where
DATE_IN_RANGE(virt_date_range,date'2012-02-01')=1
Plan hash value: 2131856123
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 9218 | 1 |00:00:00.01 | 15 |
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 15 |
|* 2 | DOMAIN INDEX | TEST_RANGE_INDEX | 1 | | | 943 |00:00:00.01 | 15 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("XTENDER"."DATE_IN_RANGE"("VIRT_DATE_RANGE",TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd
hh24:mi:ss'))=1)
So, by applying quantization with Dynamic Range Segmentation, we reduced the number of logical reads from 30 (in the simpler version) to 15—a 2x improvement.
ConclusionIn this example, we used partitions for 15 minutes, 1 hour, and 1 day for simplicity. In practice, optimal values will depend on the actual data. While the number of rows in the index increases, the fixed maximum interval length ensures consistently efficient results.
All series:
Interval Search: Part 3. Dynamic Range Segmentation – Custom Domain Index
In this part, I’ll show how to implement Dynamic Range Segmentation (DRS) explained in the previous part using a custom Domain Index, allowing you to apply this optimization with minimal changes to your existing tables.
1. Creating the Function and OperatorFirst, we create a function that will be used to define the operator for the domain index:
CREATE OR REPLACE FUNCTION F_DATE_IN_RANGE(date_range varchar2, cmpval date)
RETURN NUMBER deterministic
AS
BEGIN
-- simple concatenation: beg_date;end_date
-- in format YYYY-MM-DD HH24:MI:SS
if cmpval between to_date(substr(date_range, 1,19),'YYYY-MM-DD HH24:MI:SS')
and to_date(substr(date_range,21,19),'YYYY-MM-DD HH24:MI:SS')
then
return 1;
else
return 0;
end if;
END;
/
Next, we create the operator to use this function:
CREATE OPERATOR DATE_IN_RANGE BINDING(VARCHAR2, DATE)
RETURN NUMBER USING F_DATE_IN_RANGE;
/
idx_range_date_pkg Package
We define a package (idx_range_date_pkg) that contains the necessary procedures to manage the domain index. The full implementation is too lengthy to include here but is available on GitHub.
idx_range_date_type
The type idx_range_date_type implements the ODCI extensible indexing interface, which handles operations for the domain index.
The code is available on GitHub.
idx_range_date_type
Internal Data Segmentation:
The type and package create and maintain an internal table of segmented data. For example, the procedure ODCIIndexCreate_pr creates a partitioned table:
stmt1 := 'CREATE TABLE ' || get_index_tab_name(ia)
||q'[
(
beg_date date
,end_date date
,rid rowid
,DURATION_MINUTES number as ((end_date-beg_date)*24*60)
)
partition by range(DURATION_MINUTES)
(
partition part_15_min values less than (15)
,partition part_2_days values less than (2880) --2*24*60
,partition part_40_days values less than (57600) --40*24*60
,partition part_400_days values less than (576000) --400*24*60
,partition p_max values less than (maxvalue)
)
]';
Efficient Query Execution:
The procedure ODCIIndexStart_pr executes range queries against this internal table:
-- This statement returns the qualifying rows for the TRUE case.
stmt := q'{
select rid from {tab_name} partition (part_15_min) p1
where :cmpval between beg_date and end_date
and end_date<=:cmpval+interval'15'minute
union all
select rid from {tab_name} partition (part_2_days) p1
where :cmpval between beg_date and end_date
and end_date<=:cmpval+2
union all
select rid from {tab_name} partition (part_40_days) p1
where :cmpval between beg_date and end_date
and end_date<=:cmpval+40
union all
select rid from {tab_name} partition (part_400_days) p1
where :cmpval between beg_date and end_date
and end_date<=:cmpval+400
union all
select rid from {tab_name} partition (p_max) p1
where :cmpval between beg_date and end_date
}';
Returning Results:
The ODCIIndexFetch_pr procedure retrieves the list of qualifying ROWID values:
FETCH cur BULK COLLECT INTO rowids limit nrows;
Here is the corresponding function implementation:
MEMBER FUNCTION ODCIIndexFetch(
self in out idx_range_date_type,
nrows NUMBER,
rids OUT sys.ODCIRidList,
env sys.ODCIEnv
) RETURN NUMBER
IS
cnum number;
cur sys_refcursor;
BEGIN
idx_range_date_pkg.p_debug('Fetch: nrows='||nrows);
cnum:=self.curnum;
cur:=dbms_sql.to_refcursor(cnum);
idx_range_date_pkg.p_debug('Fetch: converted to refcursor');
idx_range_date_pkg.ODCIIndexFetch_pr(nrows,rids,env,cur);
self.curnum:=dbms_sql.to_cursor_number(cur);
RETURN ODCICONST.SUCCESS;
END;
INDEXTYPE
CREATE OR REPLACE INDEXTYPE idx_range_date_idxtype
FOR
DATE_IN_RANGE(VARCHAR2,DATE)
USING idx_range_date_type;
/
Now we created all the required objects, so it’s time to create the index.
5. Adding a Virtual Generated ColumnSince the ODCI interface only supports indexing a single column, we combine beg_date and end_date into a virtual generated column:
alter table test_table
add virt_date_range varchar2(39)
generated always as
(to_char(beg_date,'YYYY-MM-DD HH24:MI:SS')||';'||to_char(end_date,'YYYY-MM-DD HH24:MI:SS'))
/
We create the domain index on the virtual column:
CREATE INDEX test_range_index ON test_table (virt_date_range)
INDEXTYPE IS idx_range_date_idxtype
/
Let’s test the index with a query:
SQL> select count(*) from test_table where DATE_IN_RANGE(virt_date_range,date'2012-02-01')=1;
COUNT(*)
----------
943
Execution Plan:
SQL> @last
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------------------
SQL_ID 17wncu9ftfzf6, child number 0
-------------------------------------
select count(*) from test_table where
DATE_IN_RANGE(virt_date_range,date'2012-02-01')=1
Plan hash value: 2131856123
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 9218 | 1 |00:00:00.01 | 30 |
| 1 | SORT AGGREGATE | | 1 | 1 | 40 | | 1 |00:00:00.01 | 30 |
|* 2 | DOMAIN INDEX | TEST_RANGE_INDEX | 1 | | | | 943 |00:00:00.01 | 30 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("XTENDER"."DATE_IN_RANGE"("VIRT_DATE_RANGE",TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd
hh24:mi:ss'))=1)
Results: Only 30 logical reads were needed for the same date 2012-02-01!
Using a custom domain index allows us to implement this method with minimal changes to existing tables. This method efficiently handles interval queries while requiring significantly fewer logical reads.
In the next part, I will demonstrate how to enhance the Dynamic Range Segmentation method by introducing interval quantization—splitting longer intervals into smaller sub-intervals represented as separate rows.
Interval Search: Part 2. Dynamic Range Segmentation – Simplified
In the previous part, I discussed the most efficient known methods for optimizing range queries. In this part, I’ll introduce a simple version of my custom approach, which I call Dynamic Range Segmentation (DRS).
As explained earlier, a significant issue with conventional approaches is the lack of both boundaries in the ACCESS predicates. This forces the database to scan all index entries either above or below the target value, depending on the order of the indexed columns.
Dynamic Range Segmentation solves this problem by segmenting data based on the interval length.
Let’s create a table partitioned by interval lengths with the following partitions:
- part_15_min: Intervals shorter than 15 minutes.
- part_2_days: Intervals between 15 minutes and 2 days.
- part_40_days: Intervals between 2 days and 40 days.
- part_400_days: Intervals between 40 days and 400 days.
- p_max: All remaining intervals
Here’s the DDL for the partitioned table:
create table Dynamic_Range_Segmentation(
beg_date date
,end_date date
,rid rowid
,DURATION_MINUTES number as ((end_date-beg_date)*24*60)
)
partition by range(DURATION_MINUTES)
(
partition part_15_min values less than (15)
,partition part_2_days values less than (2880) --2*24*60
,partition part_40_days values less than (57600) --40*24*60
,partition part_400_days values less than (576000) --400*24*60
,partition p_max values less than (maxvalue)
);
The DURATION_MINUTES column is a virtual generated column that computes the interval length in minutes as the difference between beg_date and end_date.
We will explore the nuances of selecting specific partition boundaries in future parts. For now, let’s focus on the approach itself.
We populate the partitioned table with the same test data and create a local index on (end_date, beg_date):
insert/*+append parallel(4) */ into Dynamic_Range_Segmentation(beg_date,end_date,rid)
select beg_date,end_date,rowid from test_table;
create index ix_drs on Dynamic_Range_Segmentation(end_date,beg_date) local;
call dbms_stats.gather_table_stats('','Dynamic_Range_Segmentation');
By segmenting the data, we can assert with certainty that if we are searching for records in the part_15_min partition, the qualifying records must satisfy the conditionend_date <= :dt + INTERVAL '15' MINUTE
because no intervals in this partition exceed 15 minutes in length. This additional boundary provides the much-needed second predicate.
Thus, we can optimize our query by addressing each partition individually, adding upper boundaries for all partitions except the last one (p_max):
select count(*),min(beg_date),max(end_date) from (
select * from Dynamic_Range_Segmentation partition (part_15_min) p1
where date'2012-02-01' between beg_date and end_date
and end_date<=date'2012-02-01'+interval'15'minute
union all
select * from Dynamic_Range_Segmentation partition (part_2_days) p1
where date'2012-02-01' between beg_date and end_date
and end_date<=date'2012-02-01'+2
union all
select * from Dynamic_Range_Segmentation partition (part_40_days) p1
where date'2012-02-01' between beg_date and end_date
and end_date<=date'2012-02-01'+40 union all
select * from Dynamic_Range_Segmentation partition (part_400_days) p1
where date'2012-02-01' between beg_date and end_date
and end_date<=date'2012-02-01'+400
union all
select * from Dynamic_Range_Segmentation partition (p_max) p1
where date'2012-02-01' between beg_date and end_date
);
Results:
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
943 2011-01-03 00:00:00 2013-03-03 00:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last -alias -projection'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 204zu1xhdqcq3, child number 0
-------------------------------------
select count(*),min(beg_date),max(end_date) from ( select * from
Dynamic_Range_Segmentation partition (part_15_min) p1 where
date'2012-02-01' between beg_date and end_date and
end_date<=date'2012-02-01'+interval'15'minute union all select *
from Dynamic_Range_Segmentation partition (part_2_days) p1 where
date'2012-02-01' between beg_date and end_date and
end_date<=date'2012-02-01'+2 union all select * from
Dynamic_Range_Segmentation partition (part_40_days) p1 where
date'2012-02-01' between beg_date and end_date and
end_date<=date'2012-02-01'+40 union all select * from
Dynamic_Range_Segmentation partition (part_400_days) p1 where
date'2012-02-01' between beg_date and end_date and
end_date<=date'2012-02-01'+400 union all select * from
Dynamic_Range_Segmentation partition (p_max) p1 where
date'2012-02-01' between beg_date and end_date )
Plan hash value: 1181465968
----------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | Pstart| Pstop | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 24 (100)| | | | 1 |00:00:00.01 | 28 |
| 1 | SORT AGGREGATE | | 1 | 1 | 18 | | | | | 1 |00:00:00.01 | 28 |
| 2 | VIEW | | 1 | 1582 | 28476 | 24 (0)| 00:00:01 | | | 943 |00:00:00.01 | 28 |
| 3 | UNION-ALL | | 1 | | | | | | | 943 |00:00:00.01 | 28 |
| 4 | PARTITION RANGE SINGLE| | 1 | 4 | 64 | 3 (0)| 00:00:01 | 1 | 1 | 3 |00:00:00.01 | 3 |
|* 5 | INDEX RANGE SCAN | IX_DRS | 1 | 4 | 64 | 3 (0)| 00:00:01 | 1 | 1 | 3 |00:00:00.01 | 3 |
| 6 | PARTITION RANGE SINGLE| | 1 | 536 | 8576 | 7 (0)| 00:00:01 | 2 | 2 | 19 |00:00:00.01 | 7 |
|* 7 | INDEX RANGE SCAN | IX_DRS | 1 | 536 | 8576 | 7 (0)| 00:00:01 | 2 | 2 | 19 |00:00:00.01 | 7 |
| 8 | PARTITION RANGE SINGLE| | 1 | 929 | 14864 | 10 (0)| 00:00:01 | 3 | 3 | 890 |00:00:00.01 | 10 |
|* 9 | INDEX RANGE SCAN | IX_DRS | 1 | 929 | 14864 | 10 (0)| 00:00:01 | 3 | 3 | 890 |00:00:00.01 | 10 |
| 10 | PARTITION RANGE SINGLE| | 1 | 29 | 464 | 2 (0)| 00:00:01 | 4 | 4 | 17 |00:00:00.01 | 2 |
|* 11 | INDEX RANGE SCAN | IX_DRS | 1 | 29 | 464 | 2 (0)| 00:00:01 | 4 | 4 | 17 |00:00:00.01 | 2 |
| 12 | PARTITION RANGE SINGLE| | 1 | 84 | 1344 | 2 (0)| 00:00:01 | 5 | 5 | 14 |00:00:00.01 | 6 |
|* 13 | INDEX FAST FULL SCAN | IX_DRS | 1 | 84 | 1344 | 2 (0)| 00:00:01 | 5 | 5 | 14 |00:00:00.01 | 6 |
----------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-02-01 00:15:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
7 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-02-03 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
9 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-03-12 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
11 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2013-03-07 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
13 - filter(("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE">=TO_DATE(' 2012-02-01 00:00:00',
'syyyy-mm-dd hh24:mi:ss')))
This approach reduces logical reads (LIOs) to 28, compared to the 183 in the best case from the previous parts.
Simplifying with a SQL MacroTo avoid writing such large queries repeatedly, we can create a SQL Macro:
create or replace function DRS_by_date_macro(dt date)
return varchar2 sql_macro
is
begin
return q'{
select * from Dynamic_Range_Segmentation partition (part_15_min) p1
where dt between beg_date and end_date
and end_date<=dt+interval'15'minute
union all
select * from Dynamic_Range_Segmentation partition (part_2_days) p1
where dt between beg_date and end_date
and end_date<=dt+2
union all
select * from Dynamic_Range_Segmentation partition (part_40_days) p1
where dt between beg_date and end_date
and end_date<=dt+40
union all
select * from Dynamic_Range_Segmentation partition (part_400_days) p1
where dt between beg_date and end_date
and end_date<=dt+400
union all
select * from Dynamic_Range_Segmentation partition (p_max) p1
where dt between beg_date and end_date
}';
end;
/
With this macro, queries become concise:
SQL> select count(*),min(beg_date),max(end_date) from DRS_by_date_macro(date'2012-02-01');
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
943 2011-01-03 00:00:00 2013-03-03 00:00:00
Execution plan:
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last -alias -projection'));
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 7nmx3cnwrmd0c, child number 0
-------------------------------------
select count(*),min(beg_date),max(end_date) from
DRS_by_date_macro(date'2012-02-01')
Plan hash value: 1181465968
---------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows s| Cost (%CPU)| E-Time | Pstart| Pstop | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 24 (100)| | | | 1 |00:00:00.01 | 28 |
| 1 | SORT AGGREGATE | | 1 | 1 | | | | | 1 |00:00:00.01 | 28 |
| 2 | VIEW | | 1 | 1582 | 24 (0)| 00:00:01 | | | 943 |00:00:00.01 | 28 |
| 3 | UNION-ALL | | 1 | | | | | | 943 |00:00:00.01 | 28 |
| 4 | PARTITION RANGE SINGLE| | 1 | 4 | 3 (0)| 00:00:01 | 1 | 1 | 3 |00:00:00.01 | 3 |
|* 5 | INDEX RANGE SCAN | IX_DRS | 1 | 4 | 3 (0)| 00:00:01 | 1 | 1 | 3 |00:00:00.01 | 3 |
| 6 | PARTITION RANGE SINGLE| | 1 | 536 | 7 (0)| 00:00:01 | 2 | 2 | 19 |00:00:00.01 | 7 |
|* 7 | INDEX RANGE SCAN | IX_DRS | 1 | 536 | 7 (0)| 00:00:01 | 2 | 2 | 19 |00:00:00.01 | 7 |
| 8 | PARTITION RANGE SINGLE| | 1 | 929 | 10 (0)| 00:00:01 | 3 | 3 | 890 |00:00:00.01 | 10 |
|* 9 | INDEX RANGE SCAN | IX_DRS | 1 | 929 | 10 (0)| 00:00:01 | 3 | 3 | 890 |00:00:00.01 | 10 |
| 10 | PARTITION RANGE SINGLE| | 1 | 29 | 2 (0)| 00:00:01 | 4 | 4 | 17 |00:00:00.01 | 2 |
|* 11 | INDEX RANGE SCAN | IX_DRS | 1 | 29 | 2 (0)| 00:00:01 | 4 | 4 | 17 |00:00:00.01 | 2 |
| 12 | PARTITION RANGE SINGLE| | 1 | 84 | 2 (0)| 00:00:01 | 5 | 5 | 14 |00:00:00.01 | 6 |
|* 13 | INDEX FAST FULL SCAN | IX_DRS | 1 | 84 | 2 (0)| 00:00:01 | 5 | 5 | 14 |00:00:00.01 | 6 |
---------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-02-01 00:15:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
7 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-02-03 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
9 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2012-03-12 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
11 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE"<=TO_DATE(' 2013-03-07 00:00:00',
'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
13 - filter(("BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "END_DATE">=TO_DATE(' 2012-02-01 00:00:00',
'syyyy-mm-dd hh24:mi:ss')))
This approach can also be implemented in various ways, such as using materialized views, globally partitioned indexes, or other methods.
In the next part, I will demonstrate how to create a custom domain index to further optimize this method.
Interval Search: Optimizing Date Range Queries – Part 1
One of the most common and enduring challenges in database management is performing efficient interval searches, particularly for date intervals such as: WHERE :dt BETWEEN beg_date AND end_date.
In this series of articles, I will explore various strategies for optimizing such searches. We’ll delve into well-known standard approaches, analyze their limitations, and introduce my custom method—a method I promised to share several years ago, but I had postponed writing about it because the topic’s complexity seemed daunting, requiring a deep dive into the nuances of the data itself (e.g., open intervals, extreme values, data distribution, and skew). However, after receiving yet another question about it recently, I realized that I could no longer delay. Even if it means addressing some of the finer details in later parts, it’s time to start sharing this method in manageable steps.
Defining the ProblemIn many applications involving historical data, a common modeling approach is SCD (Slowly Changing Dimension) Type 2 (reference). This method often uses columns such as begin_date and end_date to represent the validity period of each record.
To find records that are valid at a specific point in time, queries often use predicates like:WHERE :dt BETWEEN beg_date AND end_date
The challenge lies in finding a universal and efficient method to execute such queries.
Solution ApproachesLet’s begin by creating a test table and generating sample data for evaluation:
create table test_table(
beg_date date
,end_date date
,padding varchar2(10)
);
declare
procedure p_insert(
start_date date
,end_date date
,step_minutes number
,duration_minutes number
) is
begin
insert/*+ append */ into test_table(beg_date,end_date,padding)
select
start_date + n * numtodsinterval(step_minutes,'minute')
,start_date + n * numtodsinterval(step_minutes,'minute') + numtodsinterval(duration_minutes,'minute')
,'0123456789'
from xmltable('0 to xs:integer(.)'
passing ceil( (end_date - start_date)*24*60/step_minutes)
columns n int path '.'
);
commit;
end;
begin
-- 5 min intervals every 5 minutes: 00:00-00:15, 00:05-00:20,etc:
--p_insert(date'2000-01-01',sysdate, 5, 5);
-- 5 min intervals every 5 minutes starting from 00:02 : 00:02-00:07, 00:07-00:12,etc
p_insert(date'2000-01-01'+interval'2'minute,sysdate, 5, 5);
-- 15 min intervals every 5 minutes: 00:00-00:15, 00:05-00:20,etc:
p_insert(date'2000-01-01',sysdate, 5, 15);
-- 30 min intervals every 15 minutes: 00:00-00:30, 00:15-00:45,etc:
p_insert(date'2000-01-01',sysdate, 15, 30);
-- 1 hour intervals every 15 minutes: 00:00-01:00, 00:15-01:15,etc:
p_insert(date'2000-01-01',sysdate, 15, 60);
-- 2 hour intervals every 20 minutes: 00:00-02:00, 00:20-02:00,etc:
p_insert(date'2000-01-01',sysdate, 20, 120);
-- 7 days intervals every 60 minutes:
p_insert(date'2000-01-01',sysdate, 60, 7*24*60);
-- 30 days intervals every 1 hour:
p_insert(date'2000-01-01',sysdate, 60, 30*24*60);
-- 120 days intervals every 7 days:
p_insert(date'2000-01-01',sysdate, 7*24*60, 120*24*60);
-- 400 days intervals every 30 days:
p_insert(date'2000-01-01',sysdate, 30*24*60, 400*24*60);
end;
/
We’ve got a table with 10mln rows with different date intervals:
SQL> select count(*),min(beg_date),max(end_date) from test_table;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
10723261 2000-01-01 00:00:00 2026-01-24 00:00:00
(beg_date, end_date)
The most straightforward approach is to create a composite index on (beg_date, end_date). However, even at first glance, it’s clear that this method has significant inefficiencies.
When we use a predicate like :dt BETWEEN beg_date AND end_date, it breaks down into two sub-predicates:
Access Predicate: beg_date <= :dt
This is used for index access since beg_date is the leading column in the index. However, the query will need to scan and evaluate all index entries that satisfy this condition.
Filter Predicate: :dt <= end_date
This acts as a filter on the results from the access predicate.
As the dataset grows, both beg_date and end_date values increase over time. Consequently, because the access predicate (beg_date <= :dt) is used to locate potential matches, the query will scan an ever-growing portion of the index.
(end_date, beg_date)
This is one of the most widely adopted approaches. By simply rearranging the order of columns in the index, placing end_date first, we can achieve significantly better performance in most cases.
Why? Queries tend to target data closer to the current time, and much less frequently target records from far in the past. By indexing on end_date first, the query engine can more effectively narrow down the relevant portion of the index.
Let’s create the indexes and assess their performance:
create index ix_beg_end on test_table(beg_date,end_date);
create index ix_end_beg on test_table(end_date,beg_date);
select segment_name,blocks,bytes/1024/1024 as mbytes
from user_segments
where segment_name in ('IX_BEG_END','IX_END_BEG','TEST_TABLE');
SEGMENT_NAME BLOCKS MBYTES
-------------------- ---------- ----------
IX_BEG_END 40960 320
IX_END_BEG 40832 319
TEST_TABLE 48128 376
Let’s query the records valid 100 days ago using the (beg_date, end_date) index:
SQL> select/*+ index(test_table (beg_date,end_date)) */ count(*),min(beg_date),max(end_date) from test_table where sysdate-100 between beg_date and end_date;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
935 2023-08-28 00:00:00 2025-09-26 00:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last'));
Plan hash value: 1056805589
--------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 40375 (100)| | 1 |00:00:00.79 | 40200 |
| 1 | SORT AGGREGATE | | 1 | 1 | 16 | | | 1 |00:00:00.79 | 40200 |
|* 2 | INDEX RANGE SCAN| IX_BEG_END | 1 | 28472 | 444K| 40375 (1)| 00:00:02 | 935 |00:00:00.79 | 40200 |
--------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("END_DATE">=SYSDATE@!-100 AND "BEG_DATE"<=SYSDATE@!-100)
filter("END_DATE">=SYSDATE@!-100)
As seen, the query required 40,200 logical reads, almost the entire index, which contains 40,960 blocks.
Now, let’s query the same data using the (end_date, beg_date) index:
SQL> select count(*),min(beg_date),max(end_date) from test_table where sysdate-100 between beg_date and end_date;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
935 2023-08-28 00:00:00 2025-09-26 00:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last'));
Plan hash value: 416972780
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 450 (100)| 1 |00:00:00.01 | 453 |
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 453 |
|* 2 | INDEX RANGE SCAN| IX_END_BEG | 1 | 28472 | 450 (1)| 935 |00:00:00.01 | 453 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("END_DATE">=SYSDATE@!-100 AND "END_DATE" IS NOT NULL)
filter("BEG_DATE"<=SYSDATE@!-100)
Using this index required only 453 logical reads, a dramatic improvement compared to the 40,200 reads with the first index.
Adding an Upper Bound forend_date
To illustrate the importance of having both upper and lower bounds for effective range queries, let’s further restrict the query with end_date < SYSDATE - 70:
SQL> select count(*),min(beg_date),max(end_date) from test_table where sysdate-100 between beg_date and end_date and end_date<sysdate-70;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
910 2023-08-28 00:00:00 2024-10-08 02:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last'));
Plan hash value: 3937277202
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Cost (%CPU)| A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 136 (100)| 1 |00:00:00.01 | 137 |
| 1 | SORT AGGREGATE | | 1 | | 1 |00:00:00.01 | 137 |
|* 2 | FILTER | | 1 | | 910 |00:00:00.01 | 137 |
|* 3 | INDEX RANGE SCAN| IX_END_BEG | 1 | 136 (0)| 910 |00:00:00.01 | 137 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(SYSDATE@!-70>SYSDATE@!-100)
3 - access("END_DATE">=SYSDATE@!-100 AND "END_DATE"<SYSDATE@!-70 AND "BEG_DATE"<=SYSDATE@!-100)
filter("BEG_DATE"<=SYSDATE@!-100)
We retrieved nearly all required records (910 out of 935), but the number of logical I/O operations (LIO) dropped by more than threefold.
To illustrate the inherent limitations of our current indexing strategies, let’s simplify the scenario. Suppose we have a table of integer intervals (START, END) containing 10 million records: (0,1), (1,2), (2,3), …, (9999999, 10000000). When searching for a record where 5000000 BETWEEN START AND END, regardless of whether we use an index on (START, END) or (END, START), we would have to scan approximately half of the index. This clearly demonstrates that neither of these indexes can serve as a universal solution; under certain conditions, both indexes become inefficient.
Let’s illustrate this issue using our test table. We’ll select a date roughly in the middle of our dataset – date’2012-02-01′ – and examine the performance of both indexes.
First, we’ll test the query using the (beg_date, end_date) index:
SQL> select/*+ index(test_table (beg_date,end_date)) */ count(*),min(beg_date),max(end_date) from test_table where date'2012-02-01' between beg_date and end_date;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
943 2011-01-03 00:00:00 2013-03-03 00:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last -alias -projection'));
Plan hash value: 1056805589
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)|| A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 19355 (100)|| 1 |00:00:00.45 | 19680 |
| 1 | SORT AGGREGATE | | 1 | 1 | || 1 |00:00:00.45 | 19680 |
|* 2 | INDEX RANGE SCAN| IX_BEG_END | 1 | 2783K| 19355 (1)|| 943 |00:00:00.45 | 19680 |
--------------------------------------------------------------------------------------------------------
The query required almost 20,000 LIO operations, a significant portion of the total index size. Next, we’ll perform the same query using the (end_date, beg_date) index:
select/*+ index(test_table (end_date,beg_date)) */ count(*),min(beg_date),max(end_date) from test_table where date'2012-02-01' between beg_date and end_date;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
943 2011-01-03 00:00:00 2013-03-03 00:00:00
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 20929 (100)| 1 |00:00:00.38 | 20973 |
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.38 | 20973 |
|* 2 | INDEX RANGE SCAN| IX_END_BEG | 1 | 655K| 20929 (1)| 943 |00:00:00.38 | 20973 |
-------------------------------------------------------------------------------------------------------
Similarly, this query also required approximately 20,000 LIO operations, illustrating that both indices suffer from similar inefficiencies for this type of query.
The high number of logical reads in both cases highlights that neither index provides an efficient solution for queries with dates in the middle of the data range. The database engine must scan a large portion of the index to find the matching records, resulting in increased I/O and slower query performance, especially when the search value lies in the middle of the data range.
2. Partitioning + Composite IndexesThis approach is far less common but offers significant advantages. In the previous examples with composite indexes, the predicate on the second column of the index did not help reduce the number of scanned index entries. However, by partitioning the table on this second column, we can leverage partition pruning to exclude irrelevant partitions, significantly reducing the scan scope.
Example: Partitioned Table byEND_DATE
To demonstrate, let’s create a partitioned table using the same data as in the previous example, partitioned by END_DATE on a yearly interval:
create table test_table_part_1(
beg_date date
,end_date date
,rid rowid
)
partition by range(end_date) interval (numtoyminterval(1,'year'))
(
partition part_01 values less than (date'2000-01-01')
);
insert/*+append parallel(4) */ into test_table_part_1
select beg_date,end_date,rowid from test_table;
create index ix_tt_part_local on test_table_part_1(beg_date,end_date) local;
call dbms_stats.gather_table_stats('','test_table_part_1');
This results in 28 partitions:
SQL> select partition_name,partition_position,blevel,leaf_blocks,num_rows from user_ind_partitions where index_name='IX_TT_PART_LOCAL';
PARTITION_NAME PARTITION_POSITION BLEVEL LEAF_BLOCKS NUM_ROWS
-------------- ------------------ ---------- ----------- ----------
PART_01 1 0 0 0
SYS_P8333 2 2 1621 429547
SYS_P8341 3 2 1621 429304
SYS_P8348 4 2 1621 429304
SYS_P8353 5 2 1621 429304
SYS_P8355 6 2 1625 430480
SYS_P8332 7 2 1621 429304
SYS_P8335 8 2 1621 429305
SYS_P8331 9 2 1621 429305
SYS_P8336 10 2 1625 430480
SYS_P8338 11 2 1621 429304
SYS_P8340 12 2 1621 429304
SYS_P8343 13 2 1621 429304
SYS_P8345 14 2 1625 430481
SYS_P8347 15 2 1621 429305
SYS_P8352 16 2 1621 429304
SYS_P8350 17 2 1621 429304
SYS_P8351 18 2 1625 430480
SYS_P8334 19 2 1621 429305
SYS_P8337 20 2 1621 429304
SYS_P8339 21 2 1621 429305
SYS_P8342 22 2 1625 430480
SYS_P8344 23 2 1621 429304
SYS_P8346 24 2 1621 429304
SYS_P8349 25 2 1621 429305
SYS_P8354 26 2 1561 413443
SYS_P8356 27 1 2 391
SYS_P8357 28 0 1 1
Let’s test the same query for the same DATE '2012-02-01' using the partitioned table:
SQL> select/*+ index(t (beg_date,end_date)) */ count(*),min(beg_date),max(end_date) from test_table_part_1 t where date'2012-02-01' between beg_date and end_date;
COUNT(*) MIN(BEG_DATE) MAX(END_DATE)
---------- ------------------- -------------------
943 2011-01-03 00:00:00 2013-03-03 00:00:00
SQL> select * from table(dbms_xplan.display_cursor('','','all allstats last -alias -projection'));
Plan hash value: 1651658810
-------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| Pstart| Pstop | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 10259 (100)| | | 1 |00:00:00.01 | 183 |
| 1 | SORT AGGREGATE | | 1 | 1 | | | | 1 |00:00:00.01 | 183 |
| 2 | PARTITION RANGE ITERATOR| | 1 | 2783K| 10259 (1)| 14 |1048575| 943 |00:00:00.01 | 183 |
|* 3 | INDEX RANGE SCAN | IX_TT_PART_LOCAL | 15 | 2783K| 10259 (1)| 14 |1048575| 943 |00:00:00.01 | 183 |
-------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "BEG_DATE"<=TO_DATE(' 2012-02-01 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))
filter("END_DATE">=TO_DATE(' 2012-02-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
As shown, this approach reduced the number of logical reads (LIO) to just 183, compared to 20,000 in the earlier examples. Partitioning the table on END_DATE combined with a composite local index dramatically improves query performance by limiting the scan scope through partition pruning. Even in the worst-case scenario, the number of logical reads is orders of magnitude lower than with global composite indexes. This makes it a highly effective strategy for interval searches.
Next part: Interval Search: Part 2. Dynamic Range Segmentation – Simplified
Partitioning by node (instance_number)
Years ago, I had to solve the problem of cluster-wide contention for log table blocks during a massive number of inserts from numerous sessions.
Since the table was essentially insert-only and reads were extremely rare (only during investigations of issues), the obvious solution was for sessions from each cluster node to write to their own segments.
To implement this, we introduced an INSTANCE_ID column to the table and partitioned the data based on this column:
create table t_part(ID int, instance int default sys_context('userenv','instance'))
partition by list(instance) (
partition p1 values(1),
partition p2 values(2),
partition p3 values(3),
partition p4 values(4),
partition pX values(default)
);
Essentially, we created four partitions for instance numbers 1 to 4, along with a default partition (pX) to accommodate any unexpected increase in the number of nodes.
Since then, I have successfully applied this approach in numerous, more complex scenarios involving frequent read operations. As a result, I decided to document this technique to facilitate sharing and future reference.
While the provided example is simplified, real-world implementations often necessitate additional considerations. For instance, the table might be range-partitioned, enabling the use of composite partitioning:
create table t_log(ID int, tmstmp timestamp, instance int default sys_context('userenv','instance'))
partition by range(tmstmp) interval(interval'1'day)
subpartition by list(instance)
subpartition TEMPLATE (
subpartition sub_p1 values(1),
subpartition sub_p2 values(2),
subpartition sub_p3 values(3),
subpartition sub_p4 values(4),
subpartition sub_pX values(default)
)
(
partition p1 values less than(timestamp'2024-12-01 00:00:00')
);
CBO and Partial indexing
Oracle 12c introduced Partial indexing, which works well for simple partitioned tables with literals. However, it has several significant issues:
For instance, consider the following simple partitioned table:
create table t2 (
pkey int not null,
val int,
padding varchar2(100)
)
partition by range(pkey) (
partition p1_on values less than (2),
partition p2_on values less than (3),
partition p3_off values less than (4) indexing off,
partition p4_off values less than (5) indexing off,
partition p5_on values less than (6),
partition p6_off values less than (7) indexing off
);
insert into t2
with pkeys as (select level pkey from dual connect by level<=6)
,gen as (select level n from dual connect by level<=1000)
select pkey,n,rpad('x',100,'x')
from pkeys,gen;
create index ix_t2 on t2(pkey,val) local indexing partial;
select partition_name as pname,indexing
from user_tab_partitions p
where table_name='T2';
PNAME INDEXING
---------- --------
P1_ON ON
P2_ON ON
P3_OFF OFF
P4_OFF OFF
P5_ON ON
P6_OFF OFF
6 rows selected.
This table has 6 partitions (pkey from 1 to 6), each containing 1000 rows with different val (1…1000). And CBO works fine with this simple query:
SQL> select count(*) from t2 where pkey in (1,2,6) and val=5;
COUNT(*)
----------
3
SQL> @last ""
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID awkucugb6kwdy, child number 0
-------------------------------------
select count(*) from t2 where pkey in (1,2,6) and val=5
Plan hash value: 3293077569
--------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | Pstart| Pstop | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 276 (100)| | | | 1 |00:00:00.01 | 88 |
| 1 | SORT AGGREGATE | | 1 | 1 | 7 | | | | | 1 |00:00:00.01 | 88 |
| 2 | VIEW | VW_TE_2 | 1 | 3 | | 276 (0)| 00:00:01 | | | 3 |00:00:00.01 | 88 |
| 3 | UNION-ALL | | 1 | | | | | | | 3 |00:00:00.01 | 88 |
| 4 | INLIST ITERATOR | | 1 | | | | | | | 2 |00:00:00.01 | 4 |
| 5 | PARTITION RANGE ITERATOR| | 2 | 2 | 14 | 2 (0)| 00:00:01 |KEY(I) |KEY(I) | 2 |00:00:00.01 | 4 |
|* 6 | INDEX RANGE SCAN | IX_T2 | 2 | 2 | 14 | 2 (0)| 00:00:01 |KEY(I) |KEY(I) | 2 |00:00:00.01 | 4 |
| 7 | PARTITION RANGE SINGLE | | 1 | 1 | 7 | 274 (0)| 00:00:01 | 6 | 6 | 1 |00:00:00.01 | 84 |
|* 8 | TABLE ACCESS FULL | T2 | 1 | 1 | 7 | 274 (0)| 00:00:01 | 6 | 6 | 1 |00:00:00.01 | 84 |
--------------------------------------------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$AE9E49E8
2 - SET$A73639E0 / VW_TE_2@SEL$AE9E49E8
3 - SET$A73639E0
4 - SET$A73639E0_1
6 - SET$A73639E0_1 / T2@SEL$1
7 - SET$A73639E0_2
8 - SET$A73639E0_2 / T2@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access((("PKEY"=1 OR "PKEY"=2)) AND "VAL"=5)
8 - filter(("VAL"=5 AND "PKEY"=6))
As seen above, the CBO opts for the “TABLE EXPANSION” transformation and selects IRS (Index Range Scan) for partitions P1 and P2, and FTS for partition P6. However, when we modify pkey in (1,2,6) to pkey in (1,2), the result is:
select count(*) from t2 where pkey in (1,2) and val=5
Plan hash value: 37798356
------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | Pstart| Pstop | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 547 (100)| | | | 1 |00:00:00.01 | 168 |
| 1 | SORT AGGREGATE | | 1 | 1 | 7 | | | | | 1 |00:00:00.01 | 168 |
| 2 | PARTITION RANGE INLIST| | 1 | 2 | 14 | 547 (0)| 00:00:01 |KEY(I) |KEY(I) | 2 |00:00:00.01 | 168 |
|* 3 | TABLE ACCESS FULL | T2 | 2 | 2 | 14 | 547 (0)| 00:00:01 |KEY(I) |KEY(I) | 2 |00:00:00.01 | 168 |
------------------------------------------------------------------------------------------------------------------------------------------
This query produces a less efficient plan with 2 FTS, even though it’s simpler and scans one fewer partition than the initial query. Comparing the CBO traces reveals that it skips TABLE EXPANSION transformation in such straightforward cases:

Full test case if you want to play with this example: https://gist.github.com/xtender/5992a9fbf7c088c3bfd68735f75ffdb1
Partial indexing and Composite partitioningAnother issue arises when dealing with partial indexing in conjunction with composite partitioning. The CBO is not yet fully equipped to handle these scenarios.
Consider the following table:
create table t_partial (
dt date,
spkey varchar2(1),
val int,
padding varchar2(100)
)
partition by range (dt)
subpartition by list (spkey)
subpartition template (
subpartition p_a values ('A')
, subpartition p_b values ('B')
, subpartition p_c values ('C')
)
(
partition p_1_on values less than (date'2022-11-02')
,partition p_2_on values less than (date'2022-11-03')
,partition p_3_off values less than (date'2022-11-04')
,partition p_4_off values less than (date'2022-11-05')
,partition p_5_on values less than (date'2022-11-06')
)
/
insert into t_partial(dt,spkey,val,padding)
with dates(dt) as (select date'2022-11-01'+level-1 from dual connect by level<6)
,gen as (select n from xmltable('0 to 10000' columns n int path '.'))
select
dt,
case when n<5000 then 'A'
when n<10000 then 'C'
else 'B'
end as spkey,
n,
rpad('x',100,'x') as padding
from dates,gen
/
The data distribution is as follows:
select dt,spkey,count(*) from t_partial group by dt,spkey order by 1,2
/
DT S COUNT(*)
------------------- - ----------
2022-11-01 00:00:00 A 10000
2022-11-01 00:00:00 B 10000
2022-11-01 00:00:00 C 10000
2022-11-02 00:00:00 A 10000
2022-11-02 00:00:00 B 10000
2022-11-02 00:00:00 C 10000
2022-11-03 00:00:00 A 10000
2022-11-03 00:00:00 B 10000
2022-11-03 00:00:00 C 10000
2022-11-04 00:00:00 A 10000
2022-11-04 00:00:00 B 10000
2022-11-04 00:00:00 C 10000
2022-11-05 00:00:00 A 10000
2022-11-05 00:00:00 B 10000
2022-11-05 00:00:00 C 10000
All subpartitions contain 10000 rows (val from 1 to 10000), and they are currently set to indexing=on:
SQL> col p_name for a10;
SQL> col subp_name for a12;
SQL> col indexing for a8;
SQL> select
2 partition_position as p_n
3 ,partition_name as p_name
4 ,subpartition_position as subp_n
5 ,subpartition_name as subp_name
6 ,indexing
7 from user_tab_subpartitions
8 where table_name='T_PARTIAL'
9 /
P_N P_NAME SUBP_N SUBP_NAME INDEXING
---------- ---------- ---------- ------------ --------
1 P_1_ON 1 P_1_ON_P_A ON
1 P_1_ON 2 P_1_ON_P_B ON
1 P_1_ON 3 P_1_ON_P_C ON
2 P_2_ON 1 P_2_ON_P_A ON
2 P_2_ON 2 P_2_ON_P_B ON
2 P_2_ON 3 P_2_ON_P_C ON
3 P_3_OFF 1 P_3_OFF_P_A ON
3 P_3_OFF 2 P_3_OFF_P_B ON
3 P_3_OFF 3 P_3_OFF_P_C ON
4 P_4_OFF 1 P_4_OFF_P_A ON
4 P_4_OFF 2 P_4_OFF_P_B ON
4 P_4_OFF 3 P_4_OFF_P_C ON
5 P_5_ON 1 P_5_ON_P_A ON
5 P_5_ON 2 P_5_ON_P_B ON
5 P_5_ON 3 P_5_ON_P_C ON
Disabling indexing on the partition level is not possible:
SQL> alter table t_partial modify partition P_1_ON indexing on
2 /
alter table t_partial modify partition P_1_ON indexing on
*
ERROR at line 1:
ORA-14229: cannot modify the indexing attribute of a composite partition
So let’s disable indexing for subpartitions ‘A’ and ‘C’ in partitions P3 and P4 and create a partial index:
SQL> begin
2 for r in (
3 select subpartition_name sname
4 from user_tab_subpartitions
5 where table_name='T_PARTIAL'
6 and partition_name like '%OFF'
7 and subpartition_name not like '%B'
8 ) loop
9 execute immediate
10 'alter table t_partial modify subpartition '||r.sname||' indexing off';
11 end loop;
12 end;
13 /
PL/SQL procedure successfully completed.
SQL> select
2 partition_position as p_n
3 ,partition_name as p_name
4 ,subpartition_position as subp_n
5 ,subpartition_name as subp_name
6 ,indexing
7 from user_tab_subpartitions
8 where table_name='T_PARTIAL'
9 /
P_N P_NAME SUBP_N SUBP_NAME INDEXING
---------- ---------- ---------- ------------ --------
1 P_1_ON 1 P_1_ON_P_A ON
1 P_1_ON 2 P_1_ON_P_B ON
1 P_1_ON 3 P_1_ON_P_C ON
2 P_2_ON 1 P_2_ON_P_A ON
2 P_2_ON 2 P_2_ON_P_B ON
2 P_2_ON 3 P_2_ON_P_C ON
3 P_3_OFF 1 P_3_OFF_P_A OFF
3 P_3_OFF 2 P_3_OFF_P_B ON
3 P_3_OFF 3 P_3_OFF_P_C OFF
4 P_4_OFF 1 P_4_OFF_P_A OFF
4 P_4_OFF 2 P_4_OFF_P_B ON
4 P_4_OFF 3 P_4_OFF_P_C OFF
5 P_5_ON 1 P_5_ON_P_A ON
5 P_5_ON 2 P_5_ON_P_B ON
5 P_5_ON 3 P_5_ON_P_C ON
SQL> create index ix_partial on t_partial(spkey,val,dt) local indexing partial
2 /
Index created.
SQL> exec dbms_stats.gather_table_stats(ownname => user,tabname => 'T_PARTIAL', cascade=>true);
PL/SQL procedure successfully completed.
Now, examine these 2 simple queries, each requesting just 1 day – 2022-11-03 and 2022-11-04:
select count(val)
from t_partial t
where spkey='B' and val=3
and t.dt >= date'2022-11-03' and t.dt < date'2022-11-04';
select count(val)
from t_partial t
where spkey='B' and val=3
and t.dt >= date'2022-11-04' and t.dt < date'2022-11-05';
Both of them produce the same efficient execution plan with IRS:
---------------------------------------------+-----------------------------------+---------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time | Pstart| Pstop |
---------------------------------------------+-----------------------------------+---------------+
| 0 | SELECT STATEMENT | | | | 2 | | | |
| 1 | SORT AGGREGATE | | 1 | 14 | | | | |
| 2 | PARTITION RANGE SINGLE | | 1 | 14 | 2 | 00:00:01 | 3 | 3 |
| 3 | PARTITION LIST SINGLE | | 1 | 14 | 2 | 00:00:01 | 2 | 2 |
| 4 | INDEX RANGE SCAN | IX_PARTIAL| 1 | 14 | 2 | 00:00:01 | 8 | 8 |
---------------------------------------------+-----------------------------------+---------------+
Query Block Name / Object Alias (identified by operation id):
------------------------------------------------------------
1 - SEL$1
4 - SEL$1 / "T"@"SEL$1"
------------------------------------------------------------
Predicate Information:
----------------------
4 - access("SPKEY"='B' AND "VAL"=3 AND "T"."DT">=TO_DATE(' 2022-11-03 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "T"."DT"<TO_DATE(' 2022-11-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
---------------------------------------------+-----------------------------------+---------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time | Pstart| Pstop |
---------------------------------------------+-----------------------------------+---------------+
| 0 | SELECT STATEMENT | | | | 2 | | | |
| 1 | SORT AGGREGATE | | 1 | 14 | | | | |
| 2 | PARTITION RANGE SINGLE | | 1 | 14 | 2 | 00:00:01 | 4 | 4 |
| 3 | PARTITION LIST SINGLE | | 1 | 14 | 2 | 00:00:01 | 2 | 2 |
| 4 | INDEX RANGE SCAN | IX_PARTIAL| 1 | 14 | 2 | 00:00:01 | 11 | 11 |
---------------------------------------------+-----------------------------------+---------------+
Query Block Name / Object Alias (identified by operation id):
------------------------------------------------------------
1 - SEL$1
4 - SEL$1 / "T"@"SEL$1"
------------------------------------------------------------
Predicate Information:
----------------------
4 - access("SPKEY"='B' AND "VAL"=3 AND "T"."DT">=TO_DATE(' 2022-11-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "T"."DT"<TO_DATE(' 2022-11-05 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
However, attempting to select both days in a single query results in FTS:
select count(val)
from t_partial t
where spkey='B' and val=3
and t.dt >= date'2022-11-03' and t.dt < date'2022-11-05';
----------------------------------------------+-----------------------------------+---------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time | Pstart| Pstop |
----------------------------------------------+-----------------------------------+---------------+
| 0 | SELECT STATEMENT | | | | 548 | | | |
| 1 | SORT AGGREGATE | | 1 | 14 | | | | |
| 2 | PARTITION RANGE ITERATOR | | 2 | 28 | 548 | 00:00:07 | 3 | 4 |
| 3 | PARTITION LIST SINGLE | | 2 | 28 | 548 | 00:00:07 | 2 | 2 |
| 4 | TABLE ACCESS FULL | T_PARTIAL| 2 | 28 | 548 | 00:00:07 | KEY | KEY |
----------------------------------------------+-----------------------------------+---------------+
Query Block Name / Object Alias (identified by operation id):
------------------------------------------------------------
1 - SEL$1
4 - SEL$1 / "T"@"SEL$1"
------------------------------------------------------------
Predicate Information:
----------------------
4 - filter("VAL"=3)
Comparing their optimizer traces reveals that that CBO disregards the partial index in case of partition range iterator, if at least 1 subpartition in that range is “unusable”:
Additionally, the same issue occurs with composite partitioning when using bind variables: CBO ignores partial indexes when bind variables are used, even if there is only 1 partition, as in the first example with literals:
declare
dt_1 date:=date'2022-11-03';
dt_2 date:=date'2022-11-04';
cnt int;
begin
select count(val)
into cnt
from t_partial t
where spkey='B' and val=3 and t.dt >= dt_1 and t.dt < dt_2;
end;
/
Index Stats::
Index: IX_PARTIAL Col#: 2 3 1 PARTITION [2]
LVLS: 1 #LB: 35 #DK: 10000 LB/K: 1.00 DB/K: 1.00 CLUF: 170.00 NRW: 10000.00 SSZ: 10000.00 LGR: 0.00 CBK: 0.00 GQL: 100.00 CHR: 0.00 KQDFLG: 0 BSZ: 1
KKEISFLG: 1
LVLS: 1 #LB: 35 #DK: 10000 LB/K: 1.00 DB/K: 1.00 CLUF: 170.00 NRW: 10000.00 SSZ: 10000.00 LGR: 0.00 CBK: 0.00 GQL: 100.00 CHR: 0.00 KQDFLG: 0 BSZ: 1
KKEISFLG: 1
UNUSABLE
----- Current SQL Statement for this session (sql_id=3xj8t99km1zkz) -----
SELECT COUNT(VAL) FROM T_PARTIAL T WHERE SPKEY='B' AND VAL=3 AND T.DT >= :B2 AND T.DT < :B1
----- PL/SQL Stack -----
----- PL/SQL Call Stack -----
object line object
handle number name
0x75dd2cc0 6 anonymous block
sql_text_length=93
sql=SELECT COUNT(VAL) FROM T_PARTIAL T WHERE SPKEY='B' AND VAL=3 AND T.DT >= :B2 AND T.DT < :B1
----- Explain Plan Dump -----
----- Plan Table -----
============
Plan Table
============
-----------------------------------------------+-----------------------------------+---------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time | Pstart| Pstop |
-----------------------------------------------+-----------------------------------+---------------+
| 0 | SELECT STATEMENT | | | | 1365 | | | |
| 1 | SORT AGGREGATE | | 1 | 14 | | | | |
| 2 | FILTER | | | | | | | |
| 3 | PARTITION RANGE ITERATOR | | 1 | 14 | 1365 | 00:00:17 | KEY | KEY |
| 4 | PARTITION LIST SINGLE | | 1 | 14 | 1365 | 00:00:17 | 2 | 2 |
| 5 | TABLE ACCESS FULL | T_PARTIAL| 1 | 14 | 1365 | 00:00:17 | KEY | KEY |
-----------------------------------------------+-----------------------------------+---------------+
Query Block Name / Object Alias (identified by operation id):
------------------------------------------------------------
1 - SEL$1
5 - SEL$1 / "T"@"SEL$1"
------------------------------------------------------------
Predicate Information:
----------------------
2 - filter(:B1>:B2)
5 - filter(("VAL"=3 AND "T"."DT">=:B2 AND "T"."DT"<:B1))
Full test case with traces: https://gist.github.com/xtender/e453510c1a23ef6e5ca3beb7af4d30d7
To address these problems, there are two workarounds:
- Use the parameter
skip_unusable_indexes - Use the hint
index
However, both workarounds come with their drawbacks:
- it’s not possible to use a hint
opt_param('skip_unusable_indexes' 'false'), so you will need to change it on the session level. - In the case of
indexhint, you may encounter “ORA-01502: index '...' or partition of such index is in unusable state“, if your bind variables switch to partitions with “indexing off“.
So before implementing partial indexing, make sure to test it thoroughly to avoid potential issues with composite partitioning and certain queries, ensuring your database runs smoothly.
Slow index access “COL=:N” where :N is NULL
All Oracle specialists know that a predicate X=NULL can never be true and we should use “X is NULL” in such cases. The Oracle optimizer knows about that, so if we create a table like this:
create table tnulls
as
select
level as N
,case when mod(level,10)=1 then level
else null
end as A
from dual
connect by level<=1000000;
create index ix_a on tnulls(a desc);
create index ix_an on tnulls(A, N);
In case of simple A=NULL:
select 1 from tnulls where A=null
Plan hash value: 3333700597
--------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)|
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 (100)|
|* 1 | FILTER | | 1 | | |
| 2 | TABLE ACCESS FULL| TNULLS | 0 | 1000K| 444 (2)|
--------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(NULL IS NOT NULL)
CBO adds filter(NULL IS NOT NULL), so it doesn’t even start the child operation TABLE ACCESS FULL. And even in the case of using a NULL bind variable – “A=:varnull” with FTS or IRS, we can see that Oracle doesn’t read data blocks:
create index ix_an on tnulls(A, N);
alter session set statistics_level=all;
SQL> select/*+ no_index(tnulls) */ 2 from tnulls where A=:varnull;
no rows selected
SQL> select * from table(dbms_xplan.display_cursor('','','typical allstats last'));
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------
SQL_ID 4xf5hr7mm4zvz, child number 0
-------------------------------------
select/*+ no_index(tnulls) */ 2 from tnulls where A=:varnull
Plan hash value: 3133871912
------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time |
------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 446 (100)| | 0 |00:00:00.01 |
|* 1 | TABLE ACCESS FULL| TNULLS | 1 | 1 | 2 | 446 (2)| 00:00:01 | 0 |00:00:00.01 |
------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("A"=:VARNULL)
SQL> select/*+ index(tnulls ix_an) */ 3 from tnulls where A=:varnull;
no rows selected
SQL> select * from table(dbms_xplan.display_cursor('','','typical allstats last'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------
SQL_ID b5qz9yv13tyr8, child number 0
-------------------------------------
select/*+ index(tnulls ix_an) */ 3 from tnulls where A=:varnull
Plan hash value: 404583077
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 2 (100)| | 0 |00:00:00.01 |
|* 1 | INDEX RANGE SCAN| IX_AN | 1 | 1 | 2 | 2 (0)| 00:00:01 | 0 |00:00:00.01 |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"=:VARNULL)
But take a look what happens if we create a descending index: index ix_a_desc on tnulls(a desc):
SQL> create index ix_a_desc on tnulls(a desc);
SQL> select/*+ index(tnulls ix_a_desc) */ 4 from tnulls where A=:varnull;
no rows selected
SQL> select * from table(dbms_xplan.display_cursor('','','typical allstats last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------
SQL_ID 8n09rudu2pr4j, child number 0
-------------------------------------
select/*+ index(tnulls ix_a_desc) */ 4 from tnulls where A=:varnull
Plan hash value: 3186386750
----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Reads |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 0 |00:00:00.06 | 1633 | 1632 |
|* 1 | INDEX RANGE SCAN| IX_A_DESC | 1 | 0 |00:00:00.06 | 1633 | 1632 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("TNULLS"."SYS_NC00003$"=SYS_OP_DESCEND(:VARNULL))
filter(SYS_OP_UNDESCEND("TNULLS"."SYS_NC00003$")=:VARNULL)
Many of us know that descending indexes are FBIs (function-based index), but it appears not everyone knows that SYS_OP_DESCEND(NULL) returns 0x00 (RAW data type), so such indexes contain NULLs. This is why IRS scans all those index blocks by access predicates and filters out all satisfied rows by FILTER predicate (SYS_OP_UNDESCEND(VirtCol) = :VARNULL).
Originally, I got a question with a plan and statistics from tkprof output:
SELECT/*+ index(T IDX_AB) */ * FROM T where A=:B1 and B=:B2;

We have an index on T(A,B), where each pair of (A,B) is nearly unique, so why is index access using that index so slow?
Upon examining this, I immediately noticed SYS_OP_DESCEND/SYS_OP_UNDESCEND in the predicate section and requested a raw trace to verify the bind variables. Once I received it, I discovered that over 90% of them were, in fact, NULLs. Since they don’t really need to return any rows in case of NULLs, the issue was solved with a simple rewrite:
SELECT/*+ index(T IDX_AB) */ * FROM T where A=:B1 and B=:B2;
to
SELECT/*+ index(T IDX_AB) */ * FROM T where A=:B1 and B=:B2
and :B1 is not null and :B2 is not null;
In conclusion, even seemingly simple aspects like predicates with NULLs can have significant nuances when dealing with unusual scenarios, such as descending indexes. Being aware of these subtleties can help you better understand the inner workings of Oracle indexes and optimize query performance in more complex situations.
More tricks with OPT_PARAM
Did you know you can set most parameters for the execution of a single statement without using an Alter Session by using an OPT_PARAM hint? For example, regular parameters (here forcing the storage clause in the query plan):
SQL> select /*+ OPT_PARAM('cell_offload_plan_display' 'always') */ col1 From table1;
and underscore parameters:
SQL> select /*+ OPT_PARAM('_arch_comp_dbg_scan',2048) */ n_name from nation;
However if you try conflicting settings that set a different value in an inner query block, the value you set in the outermost query block will prevail. In this trvial example _arch_comp_dbg_scan=2048 will prevail:
SQL> select /*+ OPT_PARAM('_arch_comp_dbg_scan',2048) */ n_name from nation
where n_nationkey = (
select /*+ OPT_PARAM('_arch_comp_dbg_scan',0) */ min(r_regionkey)
from region where n_name < r_name);
Another point to remember is that not all parameters get their value from the cursor environment. For example the buffer cache gets the raw value of _serial_direct_read so it cannot be overruled in this way:
SQL> select /*+ OPT_PARAM('_serial_direct_read', always) */ n_name from nation;
will not force a DR scan of the table but an alter session will.
Just one more tool to keep in your toolkit for when you need it.
—
Roger
Improvements to HCC with wide tables in 12.2
Since the beginning Oracle has provided four compression levels to offer a trade-off between the compression ratio and various other factors including table scans and the performance of single-row retrieval. I can not emphasize enough that the various trade offs mean that YMMV with the different levels and you should always test what works best with your application and hardware when choosing the level. Historically people have rarely used Query Low since the fast compression with reduced compression ratio means that the extra disk I/O is slower than the cost of decompression with Query High. The one time that Query Low makes sense on spinning disks is if you still have a significant number of row retrieval operations (including from index access joins).
NMVe FlashX5 introduced NVMe technology which means that the extra I/O from Query Low is faster than ZLIB decompression which makes Query Low beneficial. So we needed to reassess the sizing of Compression Units. from 11.2.0.1 to 12.1.2.4 the sizing guidelines are as follows:
Name TargetRows Target
Minimum Size Target
Maximum Size CompressionQuery Low 1000 to 8000 32 kb 32 kb LZOQuery High 1000 to 8000 32 kb 64 kb ZLIBArchive Low 8000 64 kb 256 kb ZLIBArchive High 8000 256 kb 256 kb BZ2
So, for example, Compress for Query High aims to pivot around at least 1000 rows and create a minimum compression unit size of 32 kb and a maximum of 64 kb. Using 12.1.2.3 I ran these against a TPC-H Lineitem table than contained between 1 and 6 copies of each column.
For Query Low fixed 32 kb CUs this gave us the following:
Additional copies of lineitem Rows per 32 kb CU 0 2797 1 580 2 318 3 216 4 162 5 129and for Query High 32 to 64 kb CUs this gave us:
Additional copies of lineitem Rows per 32 kb CU CU ave size 0 5031 32 1 1010 32 2 936 51 3 794 63 4 595 67 5 476 63so we see that the CU size remains as 32 kb as long as we are getting a 1000 rows or more then increases in size to 64 kb to try and fit in at least 1000 rows.
It became clear that this size range was inadequate for wide tables so to get more efficient compression and longer column runs for faster predicate performance (and also better CELLMEMORY rewrites) we removed the fixed size for Query Low and increased the max:
Query Low: 32 kb to 64 kb
Query High: 32 kb to 80 kb
This will not affect narrow tables at all but wider tables should see better table compression and faster scans at the cost of slightly slower single row retrieval for data loaded by 12.2 RDBMS. If you have HCC wide tables and typically cache them on flash cache you should consider re-evaluating Query Low for data loaded in 12.2 (or use Alter Table Move Compress to recompress existing data).
Roger
How to tell if the Exadata column cache is fully loaded
When a background activity is happening on the cell you typically can’t use RDBMS v$ views to monitor it in the same way. One such question is how to tell if a segment is fully loaded in the Exadata column cache since this does not appear in the equivalent In-Memory v$ views.
When a segment is scanned by Smart Scan sufficiently often to be eligible the AUTOKEEP pool (typically that means at least twice an hour), the eligible 1MB chunks are written to flash in 12.1.0.2 style format, and put on a background queue. Lower priority tasks pick up the queued 1MB 12.1.0.2 format chunks from the flash cache, run them though the In-Memory loader, and rewrite the pure columnar representation in place of the old 12.1.0.2 style column cache chunks.
The easiest way that I know of to tell when this completes is to monitor that background activity is to use the following query until it shows zero:
select name, sum(value) value from (
select extractvalue(value(t),'/stat/@name') name,
extractvalue(value(t),'/stat') value
from v$cell_state cs,
table(xmlsequence(extract(xmltype(cs.statistics_value),
'//stats[@type="columnarcache"]/stat'))) t
where statistics_type='CELL')
where name in ('outstanding_imcpop_requests')
group by name;
External Tables Part 1 – Project Columns All vs Referenced
I normally blog about table scans on Oracle native data but Oracle also supports a wide variety of features for scanning external tables and I need to cover these too. One of the ways I learn new things is being sent a bug report and saying to myself “Oh! I didn’t know you could do that”. So today I’m going to start with the grammar:
Alter Table <xt> Project Columns [ All | Referenced ]
This DDL changes the value in the Property column displayed in user_external_tables:
SQL> select property
2 from user_external_tables
3 where table_name='C_ET';
PROPERTY
----------
ALL
Here we have an external table defined using the legacy driver ORACLE_LOADER. This driver defaults to projecting all the columns in the base table rather than just those needed to satisfy the query (i.e. the referenced columns) and discarding rows that have data conversion issues up to the reject limit.
So for example we have a DATE column in our external table that contains dirty data that won’t convert cleanly to Oracle internal dates using the supplied mask we can either import it as a VARCHAR2 to not lose values or import it as a date but lose rows even on queries that don’t need that date column. We can change the behaviour to only project the referenced columns by
SQL> alter table c_et project column referenced;
Table altered.
SQL>
SQL> select property
2 from user_external_tables
3 where table_name='C_ET';
PROPERTY
----------
REFERENCED
The driver will now ignore unreferenced columns and if the date column is not used we will get all the rows in the external data and the query will run faster since datatype conversion is expensive but we may get an inconsistent number of rows depending on which columns are used in any given query. This is OK if the DBA knows a priori that there are no conversion errors or if they are willing to live with inconsistency in the number of rows returned.
The big data drivers such as ORACLE_HIVE have a different default behaviour which is to only project referenced columns and to replace data with conversion errors with NULL values and i.e. they default to returning a consistent number of rows with best performance.
Take away: In order to get consistency and fast table scan performance with ORACLE_LOADER, the trick is to define the external table with the ‘convert_error store_null’ option and switch to ‘Project Column Referenced’. For example:
CREATE TABLE "T_XT"
(
c0 varchar(10),
c1 varchar(10)
)
ORGANIZATION external
(
TYPE oracle_loader
DEFAULT DIRECTORY DMPDIR
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE
CHARACTERSET al32utf8
ESCAPE
FIELDS CSV WITH EMBEDDED terminated by ',' enclosed by '|'
REJECT ROWS WITH ALL NULL FIELDS
nullif equal blanks
truncate_columns
convert_error store_null
(
"C0" CHAR(10),
"C1" CHAR(10)
)
)
location
(
'simple.dat'
)
) REJECT LIMIT UNLIMITED
parallel 4;
If you want more information on handling conversion errors when scanning an external table please check the Utilities Guide section on each driver type
Examining the new Columnar Cache with v$cell_state
12.1.0.2 introduced the new Columnar Flash Cache where 1MB of blocks that are all in HCC format are rewritten so as to make each column from each CU contiguous. This works by first writing all the block headers to an array, then writing all the CU headers to an array, finally writing all the Column 1 column-level-CUs, then writing all the Column2 column-level-CUs etc.
The flash cache hash table maintains a simple mapping of column numbers to 64KB flash pages so, for any given query, we can simply do asynchronous disk I/O of the minimum set of 64KB pages required to cover the referenced columns.
Within the “flashcache” cell stats there is a new nested cell stat called “columnarcache” that enables you to track how it is working.
> set long 50000000
> set pagesize 10000
> select xmltype(STATISTICS_VALUE).getclobval(2,2) from v$cell_state;
XMLTYPE(STATISTICS_VALUE).GETCLOBVAL(2,2)
--------------------------------------------------------------------------------
....
<stats type="flashcache">
<stats type="columnarcache">
<stat name="columnar_cache_size">0</stat>
<stat name="columnar_cache_keep_size">0</stat>
<stat name="columnar_cache_keep_read">0</stat>
<stat name="columnar_cache_keep_read_bytes">0</stat>
<stat name="columnar_attempted_read">0</stat>
<stat name="columnar_attempted_read_bytes">0</stat>
<stat name="columnar_cache_hits">0</stat>
<stat name="columnar_cache_hits_read_bytes">0</stat>
<stat name="columnar_cache_hits_saved_bytes">0</stat>
<stat name="columnar_cache_pop">0</stat>
<stat name="columnar_cache_pop_bytes">0</stat>
<stat name="columnar_cache_pop_throttled">0</stat>
<stat name="columnar_cache_pop_invalid_buf">0</stat>
<stat name="columnar_cache_pop_size_align">0</stat>
<stat name="columnar_cache_pop_findchdrfailure_mainchdr">0</stat>
<stat name="columnar_cache_pop_findchdrfailure_childchdr">0</stat>
</stats>
</stats>
I typically spool the output of this to wade through it an editor but if we want to monitor how it is working with some workload, we need to extract individual stats, for example I bounced the cells and verified the cache was empty:
> select xmlcast(xmlquery('/cell_stats/stats/stats/stat[@name="columnar_cache_size"]' passing xmltype(STATISTICS_VALUE) returning content) as varchar2(200) ) "COLUMNAR CACHE SIZE"
from v$cell_state
where xmlexists('/cell_stats/stats/stats[@type="columnarcache"]' passing xmltype(STATISTICS_VALUE));
COLUMNAR CACHE SIZE
--------------------------------------------------------------------------------
0
I am using the 1GB TPC-H schema which takes a little more 400MB on disk when compressed with Query Low:
SQL> select sum(bytes) from user_segments where SEGMENT_NAME in ('SUPPLIER','PARTSUPP','LINEITEM','ORDERS','PART','CUSTOMER');
SUM(BYTES)
----------
420675584
and checking the columnar cache again shows about half of the data has been rewritten into columnar cache format instead of caching raw blocks:
SQL> select xmlcast(xmlquery('/cell_stats/stats/stats/stat[@name="columnar_cache_size"]' passing xmltype(STATISTICS_VALUE) returning content) as varchar2(200) ) "COLUMNAR CACHE SIZE"
from v$cell_state
where xmlexists('/cell_stats/stats/stats[@type="columnarcache"]' passing xmltype(STATISTICS_VALUE));
COLUMNAR CACHE SIZE
--------------------------------------------------------------------------------
179306496
So let’s look at how the cache helped:
select
xmlcast(
xmlquery(
'/cell_stats/stats/stats/stat[@name="columnar_cache_hits_read_bytes"]'
passing xmltype(STATISTICS_VALUE)
returning content
) as varchar2(200)
) "HIT READ BYTES"
from v$cell_state
where xmlexists('/cell_stats/stats/stats[@type="columnarcache"]' passing xmltype(STATISTICS_VALUE));
HIT READ BYTES
--------------------------------------------------------------------------------
1909456896
select
xmlcast(
xmlquery(
'/cell_stats/stats/stats/stat[@name="columnar_cache_hits_saved_bytes"]'
passing xmltype(STATISTICS_VALUE)
returning content
) as varchar2(200)
) "HIT SAVED BYTES"
from v$cell_state
where xmlexists('/cell_stats/stats/stats[@type="columnarcache"]' passing xmltype(STATISTICS_VALUE));
HIT SAVED BYTES
--------------------------------------------------------------------------------
1128267776
which shows we were able to eliminate about 35% of the disk I/O for this query run!
We could, of course, have gotten that information more simply with the regular stat “cell physical IO bytes saved by columnar cache” but I wanted to show how to pull values from v$cell_state for use in scripts.
Many people only use Query High compression as they find the increased disk I/O from Query Low more than offsets the savings from cheaper decompression costs. However, with the columnar cache in place, those trade-offs have changed. It may be worth re-evaluating the decision as to when user Query Low vs. Query High particularly on CPU-bound cells.
Addendum: performance bug 20525311 affecting the columnar cache with selective predicates is fixed in the next rpm.
Roger MacNicolOracle Data Storage Technology
Create External Table as Select
I was looking through a test script and saw something I didn’t know you could do in Oracle. I mentioned it to an Oracle ACE and he didn’t know it either. I then said to the External Table engineers “Oh I see you’ve added this cool new feature” and he replied dryly – “Yes, we added it in Oracle 10.1”. Ouch! So just in case you also didn’t know, you can create an External Table using a CTAS and the ORACLE_DATAPUMP driver.
This feature only work with the ORACLE_DATAPUMP access driver (it does NOT work with with the LOADER, HIVE, or HDFS drivers) and we can use it like this:
SQL> create table cet_test organization external
2 (
3 type ORACLE_DATAPUMP
4 default directory T_WORK
5 location ('xt_test01.dmp','xt_test02.dmp')
6 ) parallel 2
7 as select * from lineitem
Table created.
Checking the results shows us
-rw-rw---- ... 786554880 Mar 9 10:48 xt_test01.dmp
-rw-rw---- ... 760041472 Mar 9 10:48 xt_test02.dmp
This can be a great way of creating a (redacted) sample of data to give to a developer to test or for a bug repro to give to support or to move between systems.
Correct syntax for the table_stats hint
A friend contacted me to ask why they were having problems using the table_stats hint to influence optimizer decision making and also to influence the decision to use direct read or buffer cache scan so this is just a quick blog post to clarify the syntax as it is not well documented.
table_stats(<table_name> <method> {<keyword>=<value>} )
Method is one of: DEFAULT, SET, SCALE, SAMPLE
Keyword is one of: BLOCKS, ROWS, ROW_LENGTH
The most useful methods are SET which does for statement duration what dbms_stats.set_table_stats does globally; and SCALE which acts to scale up the current size of the segment and can therefore be used to try what if scenarios on the segment growing on performance
For example:
select /*+ table_stats(scott.emp set rows=14 blocks=1 row_length=10) */ * from scott.emp;
Since this is a table scan blog, let’s look at the impact on table scans. Using the Scale 1 customers table with 150,000 rows
SQL> exec dbms_stats.gather_table_stats(USER,'RDM');
SQL> select sum(BLOCKS) from user_segments where segment_name='RDM';
SUM(BLOCKS)
-----------
1792
and use trace events
event="trace[NSMTIO] disk medium" # Direct I/O decision making
event="10358 trace name context forever, level 2" # Buffer cache decision making
We see this segment is smaller than the small table threshold for this buffer cache (kcbstt=9458) and so decision making is short-circuited and will use the buffer cache :
kcbism: islarge 0 next 0 nblks 1689 type 2, bpid 3, kcbisdbfc 0 kcbnhl 8192 kcbstt 9458 keep_nb 0 kcbnbh 461198 kcbnwp 1 kcbpstt 0, BCRM_ON 0
NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect's size: 1689 (blocks), Threshold: MTT(46119 blocks),
Now let’s try the same query with the hint shown in the example above:
kcbism: islarge 1 next 0 nblks 66666666 type 2, bpid 3, kcbisdbfc 0 kcbnhl 8192 kcbstt 9458 keep_nb 0 kcbnbh 461198 kcbnwp 1 kcbpstt 0, BCRM_ON 0
kcbimd: nblks 66666666 kcbstt 9458 kcbnbh 46119 bpid 3 kcbisdbfc 0 is_medium 0
kcbivlo: nblks 66666666 vlot 500 pnb 461198 kcbisdbfc 0 is_large 1
NSMTIO: qertbFetch:DirectRead:[OBJECT_SIZE>VLOT]
NSMTIO: Additional Info: VLOT=2305990
Object# = 75638, Object_Size = 66666666 blocks
Now the size of the table in blocks is far larger than our small table threshold so we go on to evaluate whether it is a medium table and it is too large to be considered medium (cutoff is 10% cache i.e. kcbnbh=46119 blocks) so then it is evaluated as a very large table and that is true so direct read will be used.
Making the new value permanentIf for some reason we wanted to make some value permanent (caveat emptor) after doing experiments with the hint, we can set the table stats like this:
BEGIN
DBMS_STATS.SET_TABLE_STATS(
ownname => 'TPCH'
, tabname => 'RDM'
, numrows => 2000000
, numblks => 10000 );
END;
SQL> select NUM_ROWS,BLOCKS,EMPTY_BLOCKS from DBA_TAB_STATISTICS where TABLE_NAME='RDM';
NUM_ROWS BLOCKS EMPTY_BLOCKS
---------- ---------- ------------
2000000 10000 0
and now we see the size we decided upon after the needed experiments being used without a hint:
kcbism: islarge 1 next 0 nblks 10000 type 2, bpid 3, kcbisdbfc 0 kcbnhl 8192 kcbstt 9458 keep_nb 0 kcbnbh 461198 kcbnwp 1 kcbpstt 0, BCRM_ON 0
kcbimd: nblks 10000 kcbstt 9458 kcbnbh 46119 bpid 3 kcbisdbfc 0 is_medium 1
kcbcmt1: hit age_diff adjts last_ts nbuf nblk has_val kcbisdbfc cache_it 191 23693 23502 461198 10000 1 0 1
NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect's size: 10000 (blocks), Threshold: MTT(46119 blocks),
Our table is no longer small as 10,000 blocks is larger than STT=9458 blocks so it is a medium table but as it is smaller than the medium table threshold it will still use the buffer cache.
I hope you found this useful.
Roger
Controlling the offload of specific operators
One of the joys of regexp is that you can write a pattern that is painfully expensive to match and offloading these to the cell can cause significant impact on other users and overall throughput (including heartbeat issues). If you have a user who is prone to writing bad regexp expressions you as DBA can prevent regexp (or any other operator) from being offloaded to the cells.
Let’s take a very simple example using a cut down version of TPC-H Query 16 and a NOT LIKE predicate:
SQL> explain plan for select p_brand, p_type, p_size
from part
where p_brand <> 'Brand#45'
and p_type not like 'MEDIUM POLISHED%'
and p_size in (49, 14, 23, 45, 19, 3, 36, 9)
group by p_brand, p_type, p_size;
SQL> select * FROM TABLE(DBMS_XPLAN.DISPLAY);
|* 3 | TABLE ACCESS STORAGE FULL| PART | 29833 | 1048K| | 217 (2)| 00:00:01 | 1 | 8
------------------------------------------------------------------------------------------------------------
3 - storage(("P_SIZE"=3 OR "P_SIZE"=9 OR "P_SIZE"=14 OR "P_SIZE"=19
OR "P_SIZE"=23 OR "P_SIZE"=36 OR "P_SIZE"=45 OR "P_SIZE"=49)
AND "P_BRAND"<>'Brand#45' AND "P_TYPE" NOT LIKE 'MEDIUM POLISHED%')
Here we see all the predicates get offloaded as expected. So, for example, to stop NOT LIKE being offloaded we would need to find the operator in v$sqlfn_metadata
SQL> column descr format a18
SQL> select func_id, descr, offloadable from v$sqlfn_metadata where descr like '%LIKE%';
FUNC_ID DESCR OFF
---------- ------------------ ---
26 LIKE YES
27 NOT LIKE YES
99 LIKE NO
120 LIKE YES
121 NOT LIKE YES
...
524 REGEXP_LIKE YES
525 NOT REGEXP_LIKE YES
537 REGEXP_LIKE YES
538 NOT REGEXP_LIKE YES
we can ignore all but the two basic LIKE operators in this case, so to disable the offload of our LIKE predicates we use:
FUNC_ID DESCR OFF
---------- ------------------ ---
26 LIKE YES
27 NOT LIKE YES
99 LIKE NO
120 LIKE YES
121 NOT LIKE YES
...
524 REGEXP_LIKE YES
525 NOT REGEXP_LIKE YES
537 REGEXP_LIKE YES
538 NOT REGEXP_LIKE YES
we can ignore all but the two basic LIKE operators in this case, so to disable the offload of our LIKE predicates we use:
SQL> alter session set cell_offload_parameters="OPT_DISABLED={26,27};";
and we see this reflected in the offloadable column in v$sqlfn_metadata.
SQL> select func_id, descr, offloadable from v$sqlfn_metadata where descr like '%LIKE%';
FUNC_ID DESCR OFF
---------- ------------------ ---
26 LIKE NO
27 NOT LIKE NO
99 LIKE NO
120 LIKE YES
121 NOT LIKE YES
To re-enable them you would use:
SQL> alter session set cell_offload_parameters="OPT_DISABLED={};";
One thing to note about this param is that it doesn’t work like events (whose settings are additive), here it replaces the previous value and so every operator you want disabled has to be included in the same alter session (and the param is limited to 255 maximum characters limiting the number of operators that can be disabled). With the offload of LIKE and NOT LIKE disabled we can see the impact on the plan:
SQL> explain plan for select p_brand, p_type, p_size
from part
where p_brand <> 'Brand#45'
and p_type not like 'MEDIUM POLISHED%'
and p_size in (49, 14, 23, 45, 19, 3, 36, 9)
group by p_brand, p_type, p_size;
SQL> select * FROM TABLE(DBMS_XPLAN.DISPLAY);
|* 3 | TABLE ACCESS STORAGE FULL| PART | 29833 | 1048K| | 217 (2)| 00:00:01 | 1 | 8
------------------------------------------------------------------------------------------------------------
3 - storage(("P_SIZE"=3 OR "P_SIZE"=9 OR "P_SIZE"=14 OR "P_SIZE"=19 OR "P_SIZE"=23
OR "P_SIZE"=36 OR "P_SIZE"=45 OR "P_SIZE"=49) AND "P_BRAND"<>'Brand#45')
and the NOT LIKE is no longer in the storage filter. Now lets say that you as DBA are faced with a more complex problem and want to halt all complex processing on the cells temporarily. There is a parameter that will disable everything except the simple comparison operators and NULL checks:
SQL> alter session set "_cell_offload_complex_processing"=FALSE;
Now lets see what happens:
SQL> explain plan for select p_brand, p_type, p_size
from part
where p_brand <> 'Brand#45'
and p_type not like 'MEDIUM POLISHED%'
and p_size in (49, 14, 23, 45, 19, 3, 36, 9)
group by p_brand, p_type, p_size;
SQL> select * FROM TABLE(DBMS_XPLAN.DISPLAY);
|* 3 | TABLE ACCESS STORAGE FULL| PART | 29833 | 1048K| | 217 (2)| 00:00:01 | 1 | 8
------------------------------------------------------------------------------------------------------------
3 - filter(("P_SIZE"=3 OR "P_SIZE"=9 OR "P_SIZE"=14 OR "P_SIZE"=19 OR "P_SIZE"=23
OR "P_SIZE"=36 OR "P_SIZE"=45 OR "P_SIZE"=49) AND "P_BRAND"<>'Brand#45'
AND "P_TYPE" NOT LIKE 'MEDIUM POLISHED%')
Well we got no storage predicates at all and we didn’t expect that because we had one simple predicate namely p_brand != 'Brand#45' and the IN predicate had been rewritten to a series of OR’ed comparisons so what happened? This parameter only permits simple predicates that are linked by AND’s and can be attached directly to one column. Disjuncts are not pushable so they are normally evaluated by an eva tree or by pcode neither of which are sent to the cell with this parameter set to FALSE. So why wasn’t our one simple predicate offloaded. Well, note where it is in the explain plan. It comes after the rewritten the IN and since the predicates are sorted by the optimizer on effectiveness we stop looking as soon as we see one that can’t be offloaded. Let’s remove the IN and see what happens:
SQL> explain plan for select p_brand, p_type, p_size
from part
where p_brand <> 'Brand#45'
and p_type not like 'MEDIUM POLISHED%';
|* 2 | TABLE ACCESS STORAGE FULL| PART | 190K| 6686K| 217 (2)| 00:00:01 | 1 | 8 |
---------------------------------------------------------------------------------------------------
2 - storage("P_BRAND"<>'Brand#45')
filter("P_BRAND"<>'Brand#45' AND "P_TYPE" NOT LIKE 'MEDIUM POLISHED%')
as expected the simple predicate is now offloaded. If you look at v$sqlfn_metadata you’ll see this param is reflected in the offloadable column:
SQL> select func_id, descr, offloadable from v$sqlfn_metadata where descr like '%LIKE%';
FUNC_ID DESCR OFF
---------- ------------------ ---
26 LIKE NO
27 NOT LIKE NO
99 LIKE NO
120 LIKE NO
...
121 NOT LIKE NO
524 REGEXP_LIKE NO
525 NOT REGEXP_LIKE NO
537 REGEXP_LIKE NO
538 NOT REGEXP_LIKE NO
I hope you never need any of this in real life but it’s good to have it in the toolbag.