A Layman's Understanding of Star Schemas.

| Attachment | Size |
|---|---|
| 21.32 KB |
{kind=link}
Star Schemas are proliferating with warehouses these days. Many practitioners I have met in this space are a bit new to the concept of star schemas and as such keep falling back to old habits. But this is only hurting them. So I'll try to give my simplistic view of how it works in the hopes of granting some clarity on the practice of Star Modeling and overcoming our previous training to resist its concepts.
Should you feel my description is lacking or grossly misleading, then by all means, reply in the post, or better yet write your own article and post it on OraFAQ.
Consider a fully normalized data model. Now think of exactly the opposite, where you fully denormalize your relational data model so that you have only one flat record like a big'ol spreadsheet with a very wide row. Now back up from this flat record just a little bit so that you have a data model that is only two levels deep; one big table, and several small tables that the big table points back to. This is a STAR schema. Thus a true star data model has two attributes, it is always two levels deep, and a true star model always contains only one large table that is the focus of the model. There are of course variations of this concept but as laymen we will ignore them for now.
So why would anyone want to do this? Why would anyone want to create such a weird sounding data model whose design principles seem to promote denormalization rather than normalization? FAST INTERACTIVE ANALYZING OF DATA, that is why. Our IT world today is one in which we often deal with special case needs. STAR DESIGN is the out-growth of a special need, the need to analyze large amounts of data in an interactive manner quickly with no opportunity to rely on the existence of canned queries. And for this need, a design theory was eventually constructed. Of course to make a design theory useful is must be implementable in a practical way so from the theory of star design followed practical implementation mechanisms to support it in real life. Consider for example the BITMAP index in Oracle. Why was the bitmap index actually invented in the first place? I mean what was the motivation? The bitmap index is terrible as a general index for accessing data so why offer it as an access path to data? The motivation for bitmap indexes comes from supporting star designs. Bitmap indexes do have one special trait that makes them perfect for dealing with the problem of "NO CANNED QUERIES".
A bitmap index is much like the CRANIUM RAT from PLANESCAPE TORMENT. This role-play game is considered art by true gamers. For those who have played the game we may remember that a Cranium Rat is just a rat and alone is no harder to deal with than any other rat. But when two or three or more Cranium Rats get together in a group, they become powerful due to their ability to combine their intelligence into a single logical brain. The more Cranium Rats working together, the more powerful they are. So it is with bitmap indexes. A single bitmap index alone is no faster at getting data back from a table than any other index type. Indeed bitmap indexes are in fact poor choices for an index structure over other index types once you consider their limitations in update scenarios. However, bitmap indexes do have one special trait; they work better when used in groups. When queries start using two or three or more bitmaps indexes at the same time, bitmap indexes become super powerful. The more bitmap indexes used at the same time in a single query, the more powerful they become as a data access path because their access strategy is based on the idea of summing individual index access results into a collective whole during their use. It is this ADDITIVE CO-OPERATION occurring between bitmap indexes operating on the same query, which makes them so well suited for use in star data models.
There are several tricks to accepting the idea of a star schema. The biggest one though is understanding that databases built using star designs are not AUTHORATATIVE SOURCES OF DATA. Databases using star designs always get their data from somewhere else. They are a form or reporting database. As such, star schemas are not required to follow normalization rules as we are accustomed to. The presumption is that feeding systems have already applied edits and constraints on the data so the star data repository does not need to. This is a big hurdle for some MODELERs and DBAs to get over which is why these people do not build good star designs. They have difficulty accepting star models because these models do not employ the strategies these Modelers and DBAs has been trained to use to protect their data. They keep trying to re-introduce relationalism into the star model rather than accepting that the star model is about supporting the analytical needs of the user, not modeling reality. Those who can listen to a business sponsor and understand the analytical needs to be supported, create the best star designs. To do this you must be willing to temporarily forget the rules of normalization and embrace denormalization to a large degree. A star design does not seek to model the data in the real world; it seeks to form already modeled data into a different design that facilitates the analysis process being automated. Good star data designs model the analytical process being supported, and do not care about the relationships among the data otherwise. Yes, it is in a sense backwards to what we have been taught over the years.
The second trick to building good star schemas is remembering that the purpose of a star design are about one fact table that is the focus of the model. When you see your star design trying to accommodate other ideas and other purposes that focus on something other than the fact table, you should reevaluate the direction you are heading in. Star designs are for analyzing the one fact table central to the design of the model, and doing anything else with your star data model reduces its effectiveness as an analytic data store. Deviations from true star models usually manifest in two ways: 1) the desire to retain the relationships between dimensions in the star model which often take the form of SNOWFLAKING, and 2) the existence of two or more fact tables in the design. The issue with snowflaking and multi-fact models is not that the models are wrong, but that these two design alternatives cause performance problems. Snowflaking can destroy the effectiveness of bitmap indexes by limiting their ability to be used in groups and by causing query plans to be broken into several steps; and multiple fact tables usually means passing over data more than once in a single query. To address snowflaking, keep in mind that star models are about ease of use and performance of analyzing the fact data. To that end a good star modeler must be ready to toss out relationships in the data when they get in the way. The feeding systems should have already assured that the relationships in the data are correct. To address multiple fact tables in a single model, the usual solution is to create two separate star models and bridge between them using their common dimensions. Indeed the real test of a good star designer is in their ability deal with these two problems effectively and still produce an easy to use and fast analytical system.
A great way to appreciate the difference between RELATIONAL DESIGN THEORY and STAR DESIGN THEORY is to see an example of how the data models for the same data will differ for the two design strategies. Remember, both design are valid, each however is attempting to address a different need. The relational data model seeks to model data as it exists in the real world, with important relationships in the data accounted for. The star data model seeks to reincarnate the relational model into a design that makes slicing and dicing one specific subject area easy and fast.
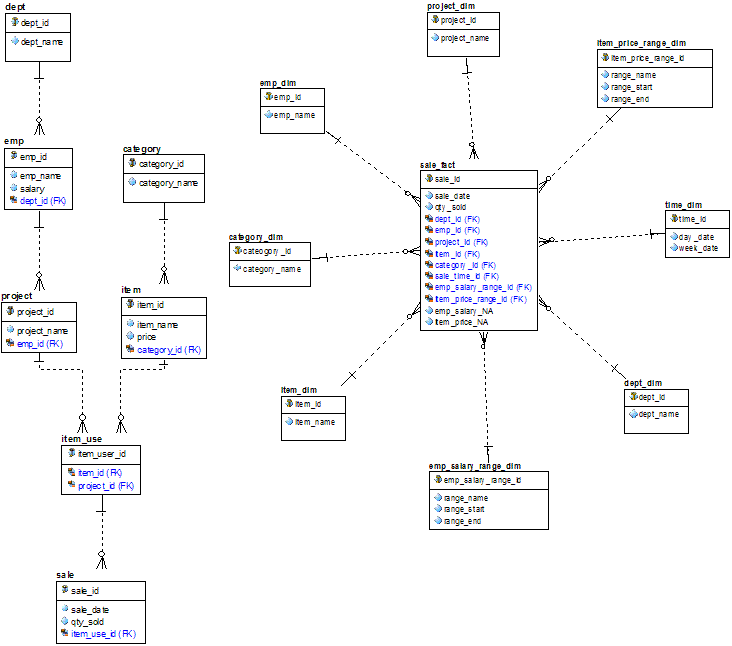
On the left below is a Relational data model, somewhat contrived, but good for our purposes. The diagram on the right below is the same data translated into one possible Star data model and yes, they call it a star model because someone along the way thought it looked kind of like a star. A simplistic way of looking at it is that we go from R --> S by fully denormalizating R into a FLAT RECORD layout, and then normalizing the flat recrod just a little bit to pull out those concepts by which we want to analyze the fact data. One of the keys to understanding star models is to look at the practicality of querying the data. In a star model getting the total quantity sold by project is the same as getting the total qty sold by department is the same as getting the total quantity sold by category is the same as ... whereas doing this in the relational model is more complex with each query being potentially very different.

There are some interesting differences between our relational model and our star model:
1) the relational model shown here is five levels deep whereas the star model shown here is only two.
2) the relational model does not suggest by its design that any of the data it models is special whereas to the star model, the fact table is the center of the universe.
3) the relational model carefully maps the relationships between tables treating relationships between so-called reference tables as just as important as all other relationships whereas the star model relies on its load processes to load data correctly based on the relationships in the data, but then can (and in this case did) toss all these relationships out of its design because it cares not about them since dealing with them after the data is loaded takes our focus away from the fact data and a star design wants all eyes on the fact data.
4) the relational model is equally adept at answering questions about any of the tables in its model whereas the star model is about slicking and dicing the fact table and little else matters. Indeed, the star model does very poorly in answering questions about its dimensions because its focus is on the fact table.
There are also some interesting transformations that happened to our relational model when we converted it to a star model. These become easier to see if we look at the table create statements of our fact table and its original relational table.
create table sale
(
sale_id number not null primary key
, sale_date date not null
, qty_sold number not null
, item_use_id number not null
--
, foreign key (item_use_id) references item_use
)
/create table sale_fact
(
sale_id number not null primary key
, sale_date date not null
, qty_sold number not null
--
, dept_id number not null
, emp_id number not null
, project_id number not null
, item_id number not null
, category_id number not null
--
, sale_time_id number not null
, emp_salary_range_id number not null
, item_price_range_id number not null
--
, emp_salary_NA number not null
, item_price_NA number not null
--
, foreign key (dept_id) references dept_dim
, foreign key (emp_id) references emp_dim
, foreign key (project_id) references project_dim
, foreign key (item_id) references item_dim
, foreign key (category_id) references category_dim
, foreign key (sale_time_id) references time_dim
, foreign key (emp_salary_range_id) references emp_salary_range_dim
, foreign key (item_price_range_id) references item_price_range_dim
)
/1) at the begining of our fact table, we have the same basic table as we saw in our relational model. SALE_FACT is one-to-one with SALE. One row in SALE_FACT is one row in SALE.
2) we have tossed out SALE.ITEM_USE_ID because the information given by this table has no value in our star design. Instead we flattened the relationships all the way up the relational foreign key chain in our relational model with the ultimate result being that keys in all our reference tables become foreign keys in our fact table. Subsequently we created dimensions in our star model for the data pointed to by each of these foreign keys. The result is that the relationships between dimension tables which roughly speaking are our orignal relational model reference tables is lost in favor of directly representing these relationships on our fact table.
3) we have added new data in our star design that did not exist in our relational design. More specifically we created a TIME DIMENSION which represents time in our system. Think of it as all the different interesting ways to represent a date. We also took the salary on the emp table and created a bucketing scheme which we then refered to in our fact table. We did the same for item price as well. The result is our EMP_SALARY_RANGE_DIM and ITEM_PRICE_RANGE_DIM. This new data would be accounted for in our load process when our fact table is loaded.
4) we also placed salary from our original emp table and item price from our original item table as NOT AGGREGATABLE (or not summable) metrics on our fact table. Consider for example that if you sum qty_sold from sale_fact for a specific employee, you get the total quantity of items sold for that employee. This is because qty_sold is summable for our fact table. But if you take the sum of emp_salary from sale_fact for a specific employee you do not get the total salary of the employee; you get the employee's salary times how ever many rows were selected (well more or less assuming the employee's salary does not change over time), a rather meaningless number. You cannot sum emp_salary off the fact table, nor can you sum item_price. This is why they have the _NA suffixes on them. One could take an average of these I suppose which might support their existence on the fact table, but such attributes should be rare.
So we see, if we look at star design as a kind of transformation of relational design then it is not so difficult to grasp the layman's perspective. And where do the bitmap indexes figure into this? Why they are created on all the foreign keys in our fact table of course. In our case there are eight ( 8 ) such keys in our fact table which means that if we wanted to slice and dice our fact table by these dimensions and provide the best performance possible, there are 8 factorial different ways to do it and thus 8 factorial indexes most concatenated indexes, if we could only rely on btree indexes. We cannot possibly create that many btree indexes to cover all possible queries that might be asked of us. But with bitmap indexes we do not have to. We need create only the eight indexes and during query execution these indexes will work together when used to effectively simulate the existence of 8! indexes for us. Read up on bitmap indexes if you want more detail to see how this is done.
As you see, the distiction between dimension and fact is highly important in a star schema and what a dimension is, is very clear and well defined as compared to the rather flexible definition of a reference table from our relational design. Dimensions represent the different ways we can slice and dice our fact data. If an idea has no dimension in a star model, then you cannot slice and dice the fact data by the idea. Keep this in mind in your star design travels. You can only analyze your facts by the dimensions you provide.
Below are the SQL scripts which you can use to build these two different models should you want to play with them.
Good luck, Kevin Meade
Relational Model
create table dept
(
dept_id number not null primary key
, dept_name varchar2(30) not null unique
)
/
create table emp
(
emp_id number not null primary key
, emp_name varchar2(30) not null unique
, salary number not null
, dept_id number not null
, foreign key (dept_id) references dept
)
/
create table project
(
project_id number not null primary key
, project_name varchar2(30) not null unique
, emp_id number not null
, foreign key (emp_id) references emp
)
/
create table category
(
category_id number not null primary key
, category_name varchar2(30) not null unique
)
/
create table item
(
item_id number not null primary key
, item_name varchar2(30) not null unique
, price number not null
, category_id number not null
, foreign key (category_id) references category
)
/
create table item_use
(
item_user_id number not null primary key
, item_id number not null
, project_id number not null
, unique (item_id,project_id)
, foreign key (item_id) references item
, foreign key (project_id) references project
)
/
create table sale
(
sale_id number not null primary key
, sale_date date not null
, qty_sold number not null
, item_use_id number not null
, foreign key (item_use_id) references item_use
)
/Star Model
create table dept_dim
(
dept_id number not null primary key
, dept_name varchar2(30) not null unique
)
/
create table emp_dim
(
emp_id number not null primary key
, emp_name varchar2(30) not null unique
)
/
create table emp_salary_range_dim
(
emp_salary_range_id number not null primary key
, range_name varchar2(30) not null unique
, range_start number not null
, range_end number not null
)
/
create table item_dim
(
item_id number not null primary key
, item_name varchar2(30) not null unique
)
/
create table item_price_range_dim
(
item_price_range_id number not null primary key
, range_name varchar2(30) not null unique
, range_start number not null
, range_end number not null
)
/
create table project_dim
(
project_id number not null primary key
, project_name varchar2(30) not null unique
)
/
create table category_dim
(
cateogory_id number not null primary key
, category_name varchar2(30) not null unique
)
/
create table time_dim
(
time_id number not null primary key
, day_date date not null unique
, week_date date not null
)
/
create table sale_fact
(
sale_id number not null primary key
, sale_date date not null
, qty_sold number not null
--
, dept_id number not null
, emp_id number not null
, project_id number not null
, item_id number not null
, category_id number not null
--
, sale_time_id number not null
, emp_salary_range_id number not null
, item_price_range_id number not null
--
, emp_salary_NA number not null
, item_price_NA number not null
--
, foreign key (dept_id) references dept_dim
, foreign key (emp_id) references emp_dim
, foreign key (project_id) references project_dim
, foreign key (item_id) references item_dim
, foreign key (category_id) references category_dim
, foreign key (sale_time_id) references time_dim
, foreign key (emp_salary_range_id) references emp_salary_range_dim
, foreign key (item_price_range_id) references item_price_range_dim
)
/- Kevin Meade's blog
- Log in to post comments
Comments
Star Schema
Dear Kevin,
I found your article quite interesting, though I still ended up with some doubts when trying to put it on practice. As part of an actual project I'm in, after founding your blog and looking at some other examples in the Internet, I grabbed some relational models and tried to transform them into star schemas. The problem is that I have a quite simple RM that I can't figure out how to create the facts table and what dimensions should exist! I'm writing to you in the hope you can help me (truly speaking, you're really my last hope)! The RM is the following:
http://picasaweb.google.pt/r.gorrao/RelationalModels#5387451558529274434
I think that the dimensions are: Studio, Country, Director, Movie, Epoch, Actor, Award and Roles.
I would put the Ratings in the fact table, but what should I do with the Casts table?
Could you please, please reply me with some star schema that actually makes sense?! This is driving me nuts, and I'm totally running out of time :S
Truly sorry for bothering you, but I'm kind of desperate and you sound like the guy I should cry for help =)
Best regards,
Bob
what do you want to count?
Part of your confusion stems from not knowing what your fact table or tables are (you may have more than one here depending upon what you want to do). The model presented at your link does not have crow's feet so I am guessing about the direction of relationships between the tables. I notice there are no DOLLAR attributes anywhere in you model. That is OK, it may be the nature of your data which is fine. It in fact may help us a little because it gives us a simple question we can ask.
What do you want to count?
What kinds of summarizations do you want to do with this data? Once you know the answer to this question, you will known what fact tables(s) you need. From that your dimensions will fall out. For example, do you want to know:
The average number of actors in a Comedy movie? If so then the table with the key of movie/actor is your fact table (I think in your model that is CAST? because its key is movie/actor/award).
Or do you want to know:
The distribution of award types across movie categories. If so then the table with the key Movie/Award would be your fact table (again I think in your model that is CAST?).
Or do you want to know:
The distibution of awards by roletype. If so then you are missing a table (your CAST table is actually denormalized with respect to roletype because of the rows-to-column pivot. The fact table for this question would be the table with the key movie/actor/role but you have none because CAST denormalized this set of keys, in which case you would need to undo the data pivot and create a table with that key (maybe called PLAYED_ROLE or something like that).
So you need to figure out what kinds of questions need to be answered. From that build either one or more fact tables to support these questions. Off hand I would suggest a table called PLAYED_ROLE with movie/actor/award/roletype (this assumes an actor can play multiple roletypes in a single movie which your pivot suggests) as the most granular fact table available to you from which you can work your way up to whatever you want.
You dimensions sounded to me like a good starting set of dimenstions. You might add more once you look at the rest of the data (gender / nationality / award organization / prize (though this might be the DOLLAR attribute I thought was missing?)).
Bottom line, find out what questions need answering, then figure out what tables will let you sum,avg,min,max your way to those answer without using DISTINCT. That will give you a set of PURE fact tables from which you can throw some away if your are OK with doing DISTINCT in our aggregates.
Once again, what are the questions you are trying to answer?
Good luck, Kevin
Excellent article
Hi Kevin,
Being intrested in datawarehousing, though I work in OLTP system, read your article.Its excellent.
Thank you very much for providing good insight of star schema, Please keep posting.
Really Good one.
Wow. that was a cool article on Star Schema! Thanks Kevin.
Any way to see that star schema diagram little more bigger?
Thanks
sippsin
Star Schema + 3NF
Hi Kevin,
An uneducated question but very important to a very large customer:
Customer is implementing Teradata and IBM BSDM for an EDW. They are also implementing BI Application which has a data model based on Star Schemas. The question is how do they integrate the two - Star Schema being populated from Oracle sources (Siebel) and EDW will be a group source of truth.
Sorry for general nature of question but your above blog is very instructive.
Thanks
Kevin