

Eddie Awad

★ Oracle to Unveil Database Cloud Service 2.0 at OpenWorld

If you are attending Oracle OpenWorld this year and you are interested in the cloud (who isn’t nowadays?!) here are a few sessions focused on Database as a Service. I will be attending a few of them too.
© Eddie Awad's Blog, 2014. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: cloud, oow14
★ How BIG is Oracle OpenWorld?

Here is how big it was in 2013. Compare it to its size in 2012. It is safe to assume that it will be bigger in 2014!
I will attend this year’s event by invitation from the Oracle ACE Program. Prior to the start of the conference, I will be attending a two day product briefing with product teams at Oracle HQ. It’s like a mini OpenWorld but only for Oracle ACE Directors.
During the briefing, Oracle product managers talk about the latest and greatest product news. They also share super secret information that is not yet made public. I will report this information to you here on awads.net and via Twitter, unless of course it is protected by a non-disclosure agreement.
See you there!
© Eddie Awad's Blog, 2014. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: oow
★ Database as a Storage (DBaaS) vs. Thick Database
A recent addition to my Oracle PL/SQL library is the book Oracle PL/SQL Performance Tuning Tips & Techniques by Michael Rosenblum and Dr. Paul Dorsey.
I agree with Steven Feuerstein’s review that “if you write PL/SQL or are responsible for tuning the PL/SQL code written by someone else, this book will give you a broader, deeper set of tools with which to achieve PL/SQL success”.
In the foreword of the book, Bryn Llewellyn writes:
The database module should be exposed by a PL/SQL API. And the details of the names and structures of the tables, and the SQL that manipulates them, should be securely hidden from the application server module. This paradigm is sometimes known as “thick database.” It sets the context for the discussion of when to use SQL and when to use PL/SQL. The only kind of SQL statement that the application server may issue is a PL/SQL anonymous block that invokes one of the API’s subprograms.
I subscribe to the thick database paradigm. The implementation details of how a transaction is processed and where the data is stored in the database should be hidden behind PL/SQL APIs. Java developers do not have to know how the data is manipulated or the tables where the data is persisted, they just have to call the API.
However, like Bryn, I have seen many projects where all calls to the database are implemented as SQL statements that directly manipulate the application’s database tables. The manipulation is usually done via an ORM framework such as Hibernate.
In the book, the authors share a particularly bad example of this design. A single request from a client machine generated 60,000 round-trips from the application server to the database. They explain the reason behind this large number:
Java developers who think of the database as nothing more than a place to store persistent copies of their classes use Getters and Setters to retrieve and/or update individual attributes of objects. This type of development can generate a round-trip for every attribute of every object in the database. This means that inserting a row into a table with 100 columns results in a single INSERT followed by 99 UPDATE statements. Retrieving this record from the database then requires 100 independent queries. In the application server.
Wow! That’s bad. Multiply this by a 100 concurrent requests and users will start complaining about a “slow database”. NoSQL to the rescue!
© Eddie Awad's Blog, 2014. |
Permalink |
2 comments |
Topic: Oracle |
Tags: book, pl/sql, sql
Avoid UTL_FILE_DIR Security Weakness – Use Oracle Directories Instead
Integrigy:
The UTL_FILE database package is used to read from and write to operating system directories and files. By default, PUBLIC is granted execute permission on UTL_FILE. Therefore, any database account may read from and write to files in the directories specified in the UTL_FILE_DIR database initialization parameter […] Security considerations with UTL_FILE can be mitigated by removing all directories from UTL_FILE_DIR and using the Directory functionality instead.© Eddie Awad's Blog, 2014. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: pl/sql, Security
Are You Using BULK COLLECT and FORALL for Bulk Processing Yet?
Steven Feuerstein was dismayed when he found in a PL/SQL procedure a cursor FOR loop that contained an INSERT and an UPDATE statements.
That is a classic anti-pattern, a general pattern of coding that should be avoided. It should be avoided because the inserts and updates are changing the tables on a row-by-row basis, which maximizes the number of context switches (between SQL and PL/SQL) and consequently greatly slows the performance of the code. Fortunately, this classic antipattern has a classic, well-defined solution: use BULK COLLECT and FORALL to switch from row-by-row processing to bulk processing.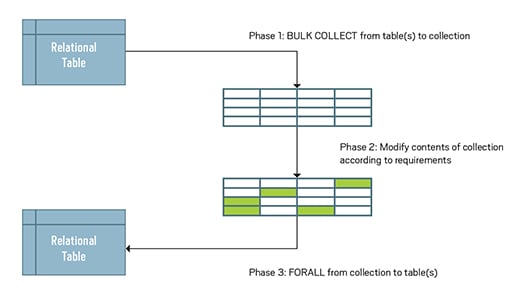
© Eddie Awad's Blog, 2014. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: pl/sql, sql
★ Native JSON Support in Oracle Database 12c

If you want JSON support in your Oracle database today you can use PL/JSON, an open source JSON parser written in PL/SQL.
However, as Marco reported from Oracle OpenWorld, native JSON support may be an upcoming new feature in Oracle Database 12c.
This new feature allows the storage of JSON documents in table columns with existing data types like VARCHAR2, CLOB, RAW, BLOB and BFILE.
A new check constraint makes sure only valid JSON is inserted.
For example: CHECK column IS JSON.
New built-in operators allow you to work with stored JSON documents. For example, JSON_VALUE enables you to query JSON data and return the result as a SQL value. Other operators include JSON_QUERY, JSON_EXISTS and JSON_TABLE.
Cool stuff!
© Eddie Awad's Blog, 2013. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: 12c, json
★ Now Available for Download: Presentations from Oracle OpenWorld 2013
Head to the Content Catalog and start downloading your favorite sessions. No registration needed. Sessions will be available for download until March 2014.
Note that some presenters chose not to make their sessions available.
Via the Oracle OpenWorld Blog.
© Eddie Awad's Blog, 2013. |
Permalink |
2 comments |
Topic: Oracle |
Tags: oow
★ Oracle Database 12c In-Memory Option Explained

Jonathan Lewis explains the recently announced Oracle Database 12c in-memory option:
The in-memory component duplicates data (specified tables – perhaps with a restriction to a subset of columns) in columnar format in a dedicated area of the SGA. The data is kept up to date in real time, but Oracle doesn’t use undo or redo to maintain this copy of the data because it’s never persisted to disc in this form, it’s recreated in-memory (by a background process) if the instance restarts. The optimizer can then decide whether it would be faster to use a columnar or row-based approach to address a query.The intent is to help systems which are mixed OLTP and DSS – which sometimes have many “extra” indexes to optimise DSS queries that affect the performance of the OLTP updates. With the in-memory columnar copy you should be able to drop many “DSS indexes”, thus improving OLTP response times – in effect the in-memory stuff behaves a bit like non-persistent bitmap indexing.
© Eddie Awad's Blog, 2013. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: 12c, in-memory
★ Oracle Database 12c Bookmarklet, Search Plugin and New Features
The blogosphere continues its buzz about Oracle Database 12c and what feels like an unlimited supply of new features in this latest cloud enabled release.
Speaking of new features, here is what’s new in Oracle Database, SQL and PL/SQL from 9iR1 until 12cR1.
With a new release comes new documentation and handy tools to make searching documentation easier. Check out the updated Oracle Bookmarklets and browser search plugins.
© Eddie Awad's Blog, 2013. |
Permalink |
Add a comment |
Topic: Oracle |
Tags: 12c