

Kevin Closson

PGIO Update
PGIO is the SLOB method for PostreSQL. An old friend of mine, Bart Sjerps, has implemented a modified PGIO in Python and posted it on Github: https://github.com/bsjerps/pypgio
For more on PGIO:
https://dev.to/yugabyte/slob-on-yugabytedb-1a32
https://franckpachot.medium.com/do-you-know-what-you-are-measuring-with-pgbench-d8692a33e3d6
VMware Are Serious About Oracle Database Performance Characterization
This is just a quick blog entry to alert readers to a list of very good performance characterization articles based on SLOB-based testing and published by VMware’s own Sudhir Balasubramanian. In addition to listing these links here I also updated the SLOB Experts Page.
- https://blogs.vmware.com/apps/2022/04/oracle-flashcache-pmem-filestore-intel-dcoptane-pmem-vmware.html
- https://blogs.vmware.com/apps/2022/02/acclerate-oracle-redo-pmem-filestore-intel-dcpmm-vmware.html
- Oracle workloads using Intel Optane DC PMM in Memory Mode on VMware vSphere platform – An Investigation
- To NUMA or not to NUMA – Oracle workloads and NUMA
- PVSCSI Controllers and Queue Depth – Accelerating performance for Oracle Workloads
- PVSCSI Controllers and Queue Depth – ASM SAME and Oracle Workloads
- Reclaiming dead space from Oracle databases on VMware Hybrid Platform
- Accelerating Oracle workloads with vSphere 6.7 Guest 2M & 1GB Huge Pages – An Investigation
- Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log
Little Things Doth Crabby Make – Part XXIII. IEC 60027 Still Makes Me Crabby!
I know the base 10, base 2 IEC 60027-2 thing only makes me crabby. But since it does, I had to make a Little Things post. This sort of stuff, well, makes me crabby:

OK, now that’s off my chest. Have a good day and thanks for stopping by.
Microsoft Shares Oracle Database Direct NFS Capabilities with SLOB Testing Results
This is a quick post to announce that I have added Microsoft Azure to the SLOB industry experts page. I’ve put a link in the SLOB exerts page to direct you to the Microsoft testing results web page. It is about Direct NFS and Netapp storage in cloud (Azure). It is worth a read!

Announcing SLOB 2.5.4
SLOB 2.5.4 has important fixes to support very large session count testing. Testing with a large number of sessions is generally done in conjunction with enabling SLOB think time. Please see the documentation for more information about testing with SLOB think time. SLOB 2.5.4 has been tested with 12,288 sessions on 8-node RAC clusters (1,536 sessions per RAC instance) with varying think time.
When testing with very large session count, please consider taking advantage of the SLOB 2.5.3 feature of improved SLOB sessions placement as explained here.
Announcing SLOB 2.5.3
This is just a quick blog post to inform readers that SLOB 2.5.3 is now available at the following webpage: click here.
SLOB 2.5.3 is a bug fix release. One of the fixed bugs has to do with how SLOB sessions get connected to RAC instances. SLOB users can surely connect to the SCAN service but for more repeatable testing I advise SLOB 2.5.3 and SQL*Net services configured one per RAC node. This manner of connectivity establishes affinity between schemas and RAC nodes. For example, repeatability is improved if sessions performing SLOB Operations against, say, user7’s schema, it is beneficial to do so connected to the same RAC node as you iterate through your testing.
The following is cut and pasted from SLOB/misc/sql_net/README:
The tnsnames.ora in this directory offers an example of
service names that will allow the user to test RAC with
repeatable results. Connecting SLOB sessions to the round
robin SCAN listener will result in SLOB sessions connecting
to random RAC nodes. This is acceptable but not optimal and
can result in varying run results due to slight variations
in sessions per RAC node from one test to another.
As of SLOB 2.5.3, runit.sh uses the SQLNET_SERVICE_BASE and
SQLNET_SERVICE_MAX slob.conf parameters to sequentially
affinity SLOB threads (Oracle sessions) to numbered service
names. For example:
SQLNET_SERVICE_BASE=rac
SQLNET_SERVICE_MAX=8With these assigned values, runit.sh will connect the first
SLOB thread to rac1 then rac2 and so forth until rac8 after
which the connection rotor loops back to rac1. This manner
of RAC affinity testing requires either a single SLOB
schema (see SLOB Single Schema Model in the documentaion)
or 8 SLOB schemas to align properly with the value assigned
to SQLNET_SERVICE_MAX. The following command will connect
32 SLOB threads (Oracle sessions) to each RAC node in an
8-node RAC configuration given the tnsnames.ora example
file in this directory:
$ sh ./runit.sh -s 8 -t 32
This is just a quick blog entry to
This is just a quick blog entry to direct readers to an Amazon Web Services blog post regarding Oracle Licensing options when deploying Oracle Database in AWS.
Licensing Options for Oracle Database Deployments in Amazon Web Services
Following Various Legal Action Regarding “Oracle Cloud Revenue”
As a courtesy, I would like to provide a copy of the latest legal document filed in an action being brought against Oracle leadership resulting from alleged, um, improprieties in revenue reporting over the last few years. There is nothing sacred about this document. Google can find it for you just as easily.
Click on the following link to download the PDF: click here.
From the table of contents:



Announcing SLOB 2.5.2.4
SLOB 2.5.2.4 is a bug-fix release available via the SLOB Resources Page. The bug fixes in this release have to do with refinements to the undocumented Obfuscated Column feature which first appeared in SLOB 2.5.2.
Announcing SLOB 2.5.2.3
SLOB 2.5.2.3 is a bug-fix release available via the SLOB Resources Page. The bug fixes in this release have to do with refinements to the undocumented Obfuscated Column feature which first appeared in SLOB 2.5.2.
I’d like to give special thanks for some very skilled SLOB experts at Netapp for their feedback on the Obfuscated Column feature. Your testing helped find bugs and resulted in improved functionality.
Thank you Rodrigo Nascimento, Joe Carter and Scott Lane!
Announcing SLOB 2.5.2.2
SLOB 2.5.2.2 is available via the SLOB Resources Page.
SLOB 2.5.2.2 is a bug-fix release. After announcing the undocumented Obfuscated Column Data Feature, a few SLOB users reported bugs. The bugs have been fixed in this release.
Announcing Obfuscated Column Data Loading with SLOB
BLOG UPDATE: SLOB 2.5.2.2 is available for download as per this blog post.
I announced availability of SLOB 2.5.2.2. It is primarily a small bug fix release but also has an undocumented new feature. I want to say a few words about the feature in this post and will update SLOB with full support (e.g., documentation and slob.conf parameter support) in SLOB 2.5.3. Some SLOB users might want this new undocumented feature as soon as possible–thus this blog post.
The new feature allows SLOB users to load unique data in SLOB tables (single table in Single Schema Model and multiple tables in the Multiple Schema Model). Default SLOB data consists of simple, repeated character strings because column data is not really that important in the SLOB Method. However, some users find that their storage compression features (e.g., enterprise-class storage arrays such as those by Dell/EMC and Netapp) achieve artificially high compression ratios with default SLOB data. For certain testing purposes, it is less desirable to test with artificially high compression ratios. Starting with SLOB 2.5.2, users can avoid this level of compression by setting OBFUSCATE_COLUMNS to TRUE in the shell environment prior to executing the SLOB data loading script (setup.sh). Again, this feature will be documented in SLOB 2.5.3.
Overview of Loading Obfuscated DataThe following is a set of screen shots that will help me explain the OBFUSCATE_COLUMNS feature. To use the undocumented figure, simply set the shell environment variable OBFUSCATE_COLUMNS to TRUE. Doing so before executing the data loader (setup.sh) will result in all column data being loaded with random data. Similarly, setting the parameter before executing the test driver (runit.sh) will result in all UPDATE statements changing columns to random values.
An ExampleThe best way to describe the feature is to show it in use. Figure 1 shows how one can set the OBFUSCATE_COLUMNS shell environment variable to TRUE and load data as normal with the setup.sh script.

Figure 1
Figure 2 shows how the data loader filled the Single Schema Model table with two distinct strings. As explained in the documentation, the slob.conf->LOAD_PARALLEL_DEGREE parameter controls how many concurrent data loading streams will be used to load the data. In Figure 2 I had the default number of concurrent data loading streams. With the OBFUSCATE_COLUMNS feature, each data loading stream will load uniquely generated obfuscated strings. To show a sample of the data, I randomly chose the 13th ordinal column and queried distinct values. As explained in the documentation, the SLOB Method loads only a single row per block and each row has 19 128-character VARCHAR2 columns. Obfuscated data is loaded into each column. Note: each block loaded by a data loading stream will have the same block row content–so your compression ratio might vary based on the chunk size the compressor operates on.

Figure 2
Figure 3 shows how setting slob.conf->LOAD_PARALLEL_DEGREE to 64 results in 64 distinct obfuscated strings being loaded.

Figure 3
This post offers a preview of an undocumented SLOB feature. Maybe some users will post their experiences with before and after compression levels and how that changes their testing.
Announcing SLOB 2.5.2
SLOB 2.5.2 is available for download from Github. Please visit the SLOB Resources Page for the download URLs.
SLOB 2.5.2 is a bug fix release.
So pgio Does Not Accurately Report Physical I/O In Test Results? Buffering Buffers, and Baffles.
A new user to pgio (The SLOB Method for PostgreSQL) reached out to me with the following comment:
I’ve been testing with pgio but when I compare I/O monitored in iostat output it does not match the pgio output for physical reads.
The user is correct–but that’s not the fault of pgio. Please allow me to explain.
Buffering Buffers, and Baffles
PostgreSQL does not open files with the O_DIRECT flag which means I/O performed by PostgreSQL is buffered I/O. The buffering uses physical memory in the Linux page cache. For this reason, the pgio runit.sh script produces output that accounts for read IOPS (RIOPS) as opposed to RPIOPS (Read Physical IOPS). The following is an example of what the user reported and how to change the behavior.
The output in Figure 1 shows how I set up a 48-schema (32GB each) test with a single pgio thread accessing each schema. The output of runit.sh shows that the PostgreSQL primary cache (shared memory) is 4GB and that at the end of the 120 second test the internal PostgreSQL counters tallied up 436,964 reads from storage per second (RIOPS).

Figure 1
The test configuration for this has NVMe drives assembled into a single logical volume with mdadm(4) called /dev/md0. The pgio runit.sh driver script saves iostat(1) output. Figure 2 shows the iostat report for physical read requests issued to the device. A simple glance reveals the values cannot average up to 436,964 as reported by runit.sh. That’s because runit.sh isn’t reporting physical reads from storage.

Figure 2
As shown in Figure 3, pgio saves the output of /proc/diskstats. The most accurate way to calculate physical accesses to storage by pgio is to calculate the delta between the before and after data in the pgio_diskstats.out file. The diskstats data shows that the true physical read IOPS rate was 301,599 not the 436,964 figure reported by runit.sh. Again, this is because runit.sh reports reads, not physical reads and that is because PostgreSQL doesn’t really know whether a read operation is satisfied with a page cache buffer hit or a physical access to the storage device. Also shown in Figure 3 is how the data in iostat.out and diskstats output are within .1%.

Figure 3
So, let’s see how we can change this behavior.
Figure 4 shows that the 436,964 read results were achieved on a system that can buffer 526GB of the pgio active data set.

Figure 4
If You Don’t Want To Test Buffered I/O, Don’t
Figure 5 shows an example of using the pgio_reduce_free_memory.sh script to limit the amount of memory available to page cache. For no particular reason, I chose to limit page cache to less than 16GB and then executed the pgio test again. As Figure 5 shows, the effect of neutering page cache buffering brought the RIOPS figure and both the iostat and diskstat data to within 1% variation.

Figure 5
Summary
This post shows that that PostgreSQL performs buffered I/O and that the pgio runit.sh driver script reports read iops (RIOPS) as per PostgreSQL internal statistics. Since pgio includes a helper script to eliminate page cache buffering from your testing, you too can test physical I/O with pgio and have accurate accounting of that physical I/O by analyzing the /proc/diskstats and iostat(1) data saved by the runit.sh script.
Announcing pgio (The SLOB Method for PostgreSQL) Is Released Under Apache 2.0 and Available at GitHub
This is just a quick post to advise readers that I have released pgio (The SLOB Method for PostgreSQL) under Apache 2.0. The bits are available at the following link: https://github.com/therealkevinc/pgio/releases/tag/1.0. The README is quite informative.
My last testing before the release showed “out of the box” data loading into Amazon Aurora with PostgreSQL compatibility at a rate of 1.69 TB/h. I only modified the pgio.conf file to specify the connection string and to set scale to 128 GB per schema:

After loading data I edited pgio.conf to increase the number of threads per schema to 16 and then easily drove IOPS to the current, advertised IOPS limit of 120,000 for Amazon Aurora with PostgreSQL compatibility.
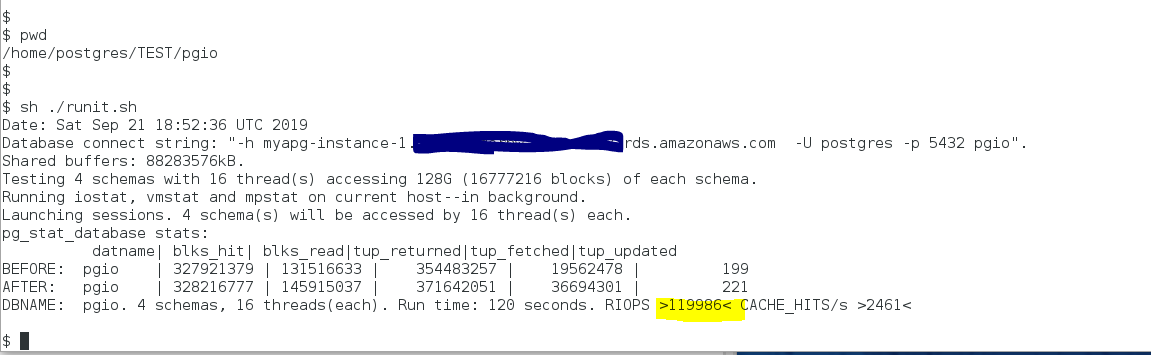
Testing PostgreSQL physical I/O on any platform could not be any easier, repeatable, nor understandable.
Enjoy pgio!
Announcing SLOB 2.5 for Download at Github.
This is just a quick blog post to announce that SLOB 2.5 is now available for downloading at: https://github.com/therealkevinc/SLOB_distribution/tree/SLOB_2.5.0.
There is an important bug fix in this release that corrects redo logging payload generation when testing with non-zero slob.conf->UPDATE_PCT. I recommend downloading and using this release accordingly. The bug is described in the release notes.
A special thanks to Maris Elsins for finding, blogging and reporting the bug.
If you adopt this release there is no need to reload SLOB (via setup.sh). Data loaded with SLOB 2.4 is compatible with SLOB 2.5. Simply deploy the tar archive and bring over your slob.conf and you’re ready to test with SLOB 2.5.
Accurately Interpreting Real Application Clusters IOPS with Automatic Workload Repository. So Easy to Get So Wrong.
This blog post has been necessary for quite some time but I just now finally got around to posting it. What I’m going to blog about is a common problem I run into in my dealings with Oracle Database Administrators (DBAs). It’s about IOPS data in Automatic Workload Repository (AWR) reports. Please don’t roll your eyes. Not everyone gets this right. I’ll explain…
I cannot count how many times I’ve had DBAs cite some IOPS number from their workload only to later receive an AWR report from them that shows a mere fraction of what they think their IOPS load is. This happens very frequently!
I’m going to explain why this happens and then show how to stop getting confused about the data.
At issue is the AWR report generated by awrgrpt.sql which is a RAC AWR report. DBAs will run this script, generate a report, open it and scroll down to the System Statistics – Per Second section so they can see “Physical Reads/s”. That’s where the problem starts. That doesn’t mean it’s the DBAs fault, per se. Instead, I blame Oracle for using the column heading “Physical Reads/s” because, well, that’s 100% erroneous.
A Case StudyTo make this topic easier to understand, I set up a small SLOB test. The SLOB driver script (runit.sh) produces both the RAC (awrgrpt.sql) and non-RAC (awrrpti) AWR reports. First, I’ll describe why SLOB can make this so easy to understand.
The following screenshot shows the slob.conf I used. You’ll notice that I loaded a “scan table” of 1GB for each schema. Not shown is the fact that I loaded 64 schemas.
For this type of testing I used the SLOB “batch” approach as opposed to a fixed-time test. As Figure 1 shows, I set the WORK_LOOP parameter to 10, which establishes that each of the sessions will perform 10 iterations of the “work loop”–a “batch” of work as it were. To make the SLOB test perform nothing but table scans, I set SCAN_PCT to 100 and UPDATE_PCT to 0.

Figure 1: SLOB Configuration File.
The runit.sh script produces both the RAC and non-RAC flavor of AWR report in compressed HTML format. The files are called awr.html.gz awr_rac.html.gz.
The RAC report differs from the non-RAC AWR report in both obvious and nonobvious ways. Obviously, a RAC report includes per-instance statistics for multiple instances, however, the RAC report also includes categories of statistics not seen in the non-RAC report. It is, in fact, one of the classes of statistics–only present in the RAC AWR report–that causes the confusion for so many DBAs.
Understandable Confusion – Words Matter!Figure 2 shows a snippet of the RAC AWR report generated during the SLOB test. The screenshot shows the crux of the matter. To check on IOPS, many DBAs open the RAC AWR report and scroll to the Global Activity Load Profile where the per-second system statistics section supposedly reports physical reads per second. I’m not even going to spend a moment of your time to split the hairs that need splitting in this situation because the rest of the RAC report clarifies the erroneous column heading.
Simply put, the simple explanation for this simple problem is that Oracle simply chose an incorrect–if not simply over-simplified–column heading in this section of the RAC AWR report.
Logical and Physical I/OFigure 2 shows the erroneous column heading. In this section of the RAC AWR report, both logical I/O and physical I/O are reported. In this context, all logical I/O in Oracle are single-block operations. What’s being reported in this section is that there were 68,115 logical reads per second of which 64,077 required a fetch from storage as the result of a cache miss. If Oracle suffers a miss on a logical I/O (which is an operation to find a cached, single block in SGA block buffer pool), the resultant action is to get that block from storage. Whether the missed block is “picked up” in a multi-block read or a single-block read is not germane in this section of the report. That said, I still think the column heading is very poorly worded. It should be “Blocks Read/s”.

Figure 2: RAC AWR Report. Global Activity Load Profile.
That heading made me think of Charlton Heston swinging off the back of a garbage truck yelling, “It’s Operations, IOPS is Operations”. Some may get the Soylent Green reference. Enough of my feeble attempt at humor.
The acronym IOPS stands for I/O operations per second. The word operations is critical. An I/O operation in, Oracle database, is a system call to transfer data to or from storage. Further down in the RAC AWR is the IOStat by Function section which uses a term that maps precisely to IOPS–requests. Another good term for an I/O operation is a request–a request of the operating system to transfer data–be it a read or a write. An operation–or a request–to transfer data comes in widely varying shapes and sizes. Figure 3 shows that the SLOB test described above actually performed approximately 8,000 requests–or, operations–per second from storage in the read path.
I’ll reiterate that. This workload performed 8,000 IOPS.
That’s a far cry less than suggested in Figure 2.

Figure 3: RAC AWR Report. IOStat by Function.
Further down in the RAC AWR report, is the Global Activity Statistics section. This section appears in both the RAC and non-RAC reports. Figure 4 shows a snippet of the Global Activity Statistics section from the RAC report generated during the SLOB. Here again we see the unfortunate misnomer of the statistic that actually represents the number of blocks retrieved from storage. Figure 4 shows the same 64,000 “physical reads” seen in Figure 2, however, there are adjacent statistics in the report to help make information out of this data. Figure 4 ties it all together. The workload performed some 8,000 read requests from storage. What was read from storage? Well, 64,000 blocks per second where physically read from storage.
Let’s Go ShoppingI have a grocery-shopping analogy in mind. Think of a requests as each time you transfer an item from the shelf to your cart. Some items are simple, single items like a bottle of water and others are multiple items in a package such as a pallet of bottled water. In this analogy, the pallet of bottled water is a multi-block read and the single bottle is, unsurprisingly, a single-block read. The physical reads statistic is the total number of water bottles–not items–placed into the cart. The number of item’s placed in the cart per second was 8,000 by way of plopping something into the cart 8,000 times per second. I hope the cart is huge.

Figure 4: Global Activity Statistics. RAC AWR Report.
As mentioned earlier in this post, the RAC AWR report is really just a multi-instance report. In this case I generated a multi-instance report that happened to capture a workload from a single-instance. That being the case, I can also read the non-RAC AWR report because it too covers the entire workload. If everyone, always, read the non-RAC AWR report there would never be any confusion about the difference between reads and payload (read requests and blocks read)–at least not since Oracle Database 11.2.0.4.
Starting in the final patchset release of 11g (11.2.0.4), the Load Profile section (which does not appear in the RAC AWR report) clearly spells out the situation with the “Physical read” misnomer. Figure 5 shows the Load Profile in the non-RAC report generated by the SLOB test. Here we can see that late in 11g there were critical, parenthesized, words added to the output. What was once reported only as “Physical reads” became “Physical read(blocks)” and the word requests was added to help DBAs determine both IOPS (requests per second are IOPS) and the payload, Again, we can clearly see that the test had an I/O workload that consisted of 8,000 requests per second for 64,000 blocks per second for a read throughput of 500MB/s.

Figure 5: Non-RAC AWR. Load Profile Section. Simple and Understandable I/O Statistics.
I hope a few readers make it to this point in the post because there is a spoiler alert. Below you’ll find links to the actual AWR reports generated by the SLOB test. Before you read them I feel compelled to throw this spoiler alert out there:
I set db_file_multiblock_read_count to 8 with the default Oracle Database block size.
That means processes were issuing 64KB read requests to the operating system.
With that spoiler alert I’m sure most readers are seeing a light come on. The test consists of 64 sessions performing 64KB reads. The reports tell us there are 8,000 requests per second (IOPS) and 64,077 blocks read per second for a read throughput of 500MB/s.
500MB / 8,000 == 64KB.
Links to the AWR reports:
https://github.com/therealkevinc/AWRS/blob/master/awr.html
https://github.com/therealkevinc/AWRS/blob/master/awr_rac.html
Click the following link and githup will give you a ZIPed copy of these AWR reports: https://github.com/therealkevinc/AWRS/archive/master.zip
No /proc/diskstats Does Not Track **Your** Physical I/O Requests
You have applications that scan disk using large sequential reads so you take a peek at /proc/diskstats (field #4 on modern Linux distributions) before and after your test in order to tally up the number of reads your application performed. That’s ok. That’s also a good way to get erroneous data.
Your application makes calls for I/O transfers of a particular size. The device drivers for your storage might not be able to accommodate your transfer request in a single DMA and will therefore “chop it up” into multiple transfers. This is quite common with Fibre Channel device drivers where, for example, I/O requests larger than, say, 256KB get rendered into multiple 256KB transfers in the kernel.
This is not a new phenomenon. However, folks may not naturally expect how stats in /proc/diskstats reflect this phenomenon.
The following screen shot shows a simple shell script I wrote to illustrate the point I’m making. The script is very simple. As the screen shot shows, the script will execute a single dd(1) command with direct I/O for 1,000 reads of sizes varying from 4KB to 1024KB.

First, I executed the script by pointing it to a file in an XFS file system on an NVMe drive. As the next screenshot shows, diskstats accurately tallied the application reads until the I/O sizes were larger than 256KB. We can see that the device is only taking DMA requests of up to 256KB. When the script was conducting 512KB and 1024KB I/O requests the count of reads doubled and quadrupled, respectively, as per /proc/diskstats.

I’m sure readers are wondering if the file system (XFS) might be muddying the water. It is not. The following screen shot shows scanning the device directly and the resultant diskstats data remained the same as it was when I scanned a file on that device.

This was not meant to be a life-changing blog post. The main point I’m sharing is that it’s important to not confuse your I/O requests with the I/O requests of the kernel. You can scan with whatever read size you’d like. However, the kernel has to abide by the transfer size limit announced by the device driver. To that end, you have your reads and the kernel has its reads. Just remember that /proc/diskstats is tracking the kernel’s read requests–not yours.
SLOB Chewed Up All My File System Space and Spit It Out. But, Why?
This is a quick blog post in response to a recent interaction with a SLOB user. The user reached out to me to lament that all her file system space was consumed as the result of a SLOB execution (runit.sh). I reminded her that runit.sh will alert to possible derelict mpstat/iostat/vmstat processes from an aborted SLOB test. If these processes exist they will be spooling their output to unlinked files.
The following screen shot shows what to expect if a SLOB test detects potential “deadwood” processes. If you see this sort of output from runit.sh, it’s best to investigate whether in fact they remain from an aborted test or whether there are other users on the system that left these processes behind.

The next screenshot shows how to take action on the runit.sh output:

If SLOB is consuming all your file system space, it’s probably already telling you why–all you need to do is take action. I hope this is helpful for some wayward Googler someday.
Sneak Preview of pgio (The SLOB Method for PostgreSQL) Part IV: How To Reduce The Amount of Memory In The Linux Page Cache For Testing Purposes.
I hope these sneak peeks are of interest…
PostgreSQL and Buffered I/OPostgreSQL uses buffered I/O. If you want to test your storage subsystem capabilities with database physical I/O you have to get the OS page cache “out of the way”–unless you want to load really large test data sets.
Although pgio (the SLOB Method for PostgreSQL) is still in Beta, I’d like to show this example of the tool I provide for users to make a really large RAM system into an effectively smaller RAM system.
Linux Huge PagesMemory allocated to huge pages is completely cordoned off unless a process allocates some IPC shared memory (shmget(1)). The pgio kit comes with a simple tools called pgio_reduce_free_memory.sh which leverages this quality of huge pages in order to draw down available memory so that one can test physical I/O with a database size that is quite smaller than the amount of physical memory in the database host.
The following picture shows an example of using pgio_reduce_free_memory.sh to draw set aside 443 gigabytes of available memory so as to leave only 32 gigabytes for OS page cache. As such, one can test a pgio database of, say, 64 gigabytes and generate a tremendous about of physical I/O.

I should think this little tool could be helpful for a lot of testing purposes beyond pgio.