Re: ASM for single-instance 11g db server?
Date: Tue, 05 Apr 2011 22:14:34 +1000
Message-ID: <inf139$gp$1_at_dont-email.me>
onedbguru wrote,on my timestamp of 5/04/2011 1:46 PM:
> I would disagree with your limited knowledge and inaccurate assessment
> of ASM and it's other features such as ACFS - especially in 11gR2. I
> am a STRONG proponent of using ASM for everything I can... and that
> includes OS Files using ASM/ACFS - think of it as a volume manager
> that not only works on a single node, but across an entire cluster. A
> year or so ago, I saw it used for the middle-tier Weblogic servers
> where OS files were accessible by any node in the cluster. With EVERY
> database I have migrated to ASM (both RAC and Single-instance) I
> gained a minimum of 7% but more often closer to 13% performance
> improvement. That includes tiny databases (<100G) as well as ELDB's
> (Extremely Large DB in the 100's of TB range - both clustered and non-
> clustered)
Hmmmm..... You being a STRONG proponent doesn't automatically define Mladen's knowledge of ASM as limited....
I'm curious how are you measuring 7% of performance improvement with any degree of precision? I usually discount anything below 10% as noise, simply because the db tools are simply not there to measure better than that. And no, AWR does NOT provide 0% gap. Nor does ARH or grid. Is this restricted to Linux? I have never seen any major performance advantage with ASM versus Aix+jfs2, for example. Other than a LOT less bugs *without* ASM...
> BTW - I NEVER propose the waste of spindles doing RAID10 on a SAN
> array. With modern SAN storage, having the many GB of cache at the
> storage array makes any perceived write performance of RAID5 a moot
> point. When you manage 100's of TB of storage, mirroring is a massive
> waste and still does not perform any better.
Agreed 100%. Very much so. In fact, I am in the process of re-allocating all our databases to RAID5 in the new SAN, precisely because given two equal SAN/processor environments I can't prove to myself that RAID5 is inherently slower than RAID10. At least in our mostly sequential I/O DW environment. I do of course accept that with random I/O things might be different.
> One of the additional
> features - if you really need 1) long distance clusters or 2)
> redundant storage, you can use ASM's FAILURE GROUPS - where you can
> have mirrored DISKGROUPS. Works great!!
Yes, but they still need to use IP transfers. ASM uses IP for long distance. And no: 2Gbps is NOT a fast long distance cluster I/O speed by ANY stretch of the imagination! At least with a SAN and dark fibre, I can do long distance mirrored groups with minimal sequential speed impact and no IP overhead whatsoever.
> With standard file systems, each file system only gets one read and
> one write FIFO buffer for moving stuff to/from memory. When you have
> many smaller LUNS in ASM, the parallelism gives a much superior
> performance.
Sorry but I don't follow this one? That might be in Linux file systems but let me assure you that with jfs2 in Aix and Fastpath I have no such limitation.
In fact I'm regularly getting around 500MB/s aggregate bandwidth transfer with a Clarion CX340, which according to EMC technical personnel is just about as fast as any server can drive those boxes with 4Gbps Brocade interconnects.
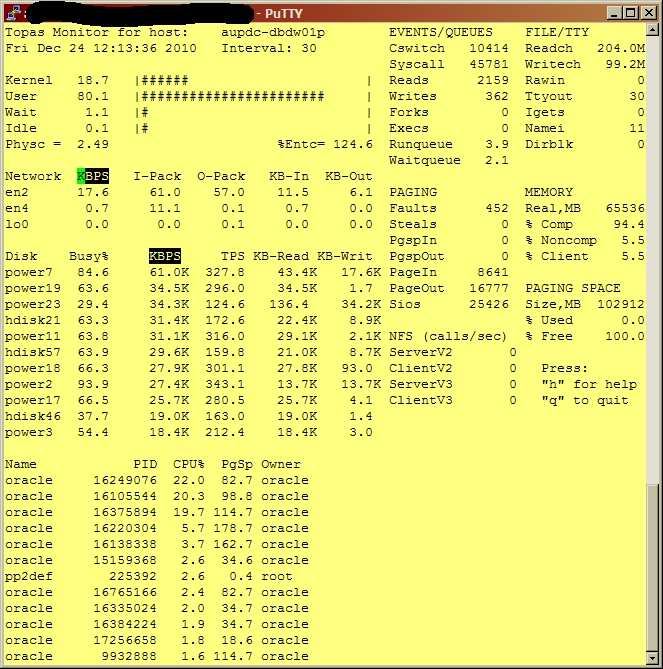
That's across nearly a dozen separate luns/file systems, all concurrently doing I/O from very many datafiles in each. You can see an example of that same box pushing 300MB/s aggregate I and O (averaged over 30secs, spot is higher) here: http://3.bp.blogspot.com/_JeMHZjfD9JI/TSWxC8eSJlI/AAAAAAAAAPg/duRm7QIWlng/s1600/300MBps.png See all those "powerxx" drives? They all pretty much reasonably balanced on busy%, aren't they? And not even anywhere near max. When it's reaching for 500, there are another 10 or so file systems that kick in. Then things get interesting: I've seen the vmware MSSQL servers reach for the sky when I'm flooding the SAN backplane with the DW going full bore! :)
{kind=link}
> With ASM moving to "another storage vendor" is very easy with ASM -
> you can do it with NO downtime. Several years ago we used ASM to move
> several hundred TB db from EMC to NetApp while adding>1TB/day with
> very little performance impact on the rest of the system. I have never
> seen any file-system based database do that and I have been around for
> a very long time...
Indeed. The only serious advantage I can see with ASM. Then again: how many
times in life does one need to transfer TB dbs from EMC to NetApp? I'd guess
it's not enough for any perceived advantage with ASM in that area to be of any
significance.
Might be very relevant for sites where hardware needs to be changed frequently.
Or cloud providers, who usually have to move things around under duress.
For the average IT shop? Not even close to relevant or a major factor.
> ability to "RAID<anything>" together - last system I worked on, the
> max was 8 spindles in a raid group... That may have changed... My
The Clarions go to 12 but I've found that 8 is the practical max in that architecture, for good performance and fit into other things like Mirrorview replication groups. I'll soon be conducting equivalent tests in a VMAX box and am very curious what will happen then. They don't really work with "luns" in that architecture and SRDF is a lot more sophisticated than Mirrorview.
> Oracle just announced a new product called CloudFS. Guess what it is
> comprised of?? Oracle Clusterware+ASM+ACFS. And the performance of
> ASM+ACFS is significantly faster - especially READS and DELETEs.. On
> your Linux (or any other UNIX for that matter)
I sincerely doubt that very much. In fact, I still have to see any site that
does I/O faster than we do - within our hardware pricepoint - and remain very
sceptical of any such "cloud" facility ever having any practical performance
advantage.
In fact during a recent evaluation for a new storage facility, we had quite a
few offers of these "cloudFS" providers. Mostly we just had to laugh at their
proposals. On paper they look very nice and cheap. Until you ask them what
happens when you need to do a DR exercise. Or how much I/O they can sustain,
aggregate and mixed. Then all the excuses and "change the subject" start. We
didn't waste anytime following it up...
> Try doing an "rm -FR
> somedir" where "somedir" has more than 300GB in hundreds of files -
> and tell me how long it took? With ACFS the removal of the pointers
> is instantaneous.
So it is with jfs2. I've seen a small slowdown with directories with in excess of 60000 files, but then it's expected that will happen!
> As for compression - if the need is for performance - quit being so
> stingy with the disk space and by what you need, not what you can "get
> away with". As they have said for years now, "Disks are cheap".
> When you do TB sized databases compressing/uncompressing is a
> ludicrous configuration.
Agreed. But don't go out pricing disks from SAN providers. Their fast offerings are anything but cheap... Still, a lot better than it was 10 years or so ago. Back then a 1TB db was an exception. Nowadays, 10s and even 100s of TB are more or less expected and not extraordinary by any means.
> I would also add that using ASM for non-RAC is very much worth it.
> When your db gets to the point that it needs RAC, then it will already
> be in ASM. And with RAC if you need to move to new systems, you just
> add the new hardware to the cluster and shutdown the old nodes and you
> keep going. Works great, last a long time...
As I said: with Linux, that may indeed be so. With Aix and a few other Unix flavours, I doubt it's all as linear as that.
Let's not dwell too long on the "simple ASM control language that dbas understand". Nothing could be more ridiculous!
From what I've seen of ASM so far, the commands are cryptic, not familiar at all to ANY dba or unix admin, incompletely documented and the whole setup requires frequent monitoring of quite a few log files and frequent re-starts of agents due to instability in many environments.
Let's not get started on the release-patch-dance needed to get anything going... And no: it's NOT any easier with grid!!!!
It might have changed with 11gr2 but like I always say with all new features of Oracle: show me proof that it's bugless and straightforward now and I'll use it. Until then, I'll just avoid it like the plague.
I'm paid to run systems, not to play "mr installer of patches" or "mr Oracle tester". That's for folks who spend their time in Oracle shows/marketing. Not for those who actually have to make systems run, solidly and reliably! As is, uptimes of 250 days are common in our Oracle dbs with one now bordering on 450. Definitely *not* the environmment to go "experimenting" in! And no: we do NOT install CPU patches. No need for them in our locked intranet.
One thing about 11gr2: the installer looks a lot tighter and better setup than the 10g one.
But it also has the propensity for default "java-like" very long pathnames, which anyone with a *n*x background hates with a vengeance! "/home/oracle/product/oracle/client_1..."???? Why not simply "/home/oracle/product/client_1..."? What is the point of adding more redundancy to already long pathnames?
<rant>
And let me mention my number 1 pet peeve of all graphical Oracle installers
since yonks: why on EARTH don't they do the preliminary checks BEFORE they let
us dig deep into a custom install?
Last thing one needs after a long custom install process is to see the thing go
"clunk" because the mathlib isn't installed or recognisable, or it thinks there
ain't enough swap space. Not a problem for me but a guaranteed show-stopper for
an inexperienced or would-be dba!
What is the problem with doing that check UPFRONT, before anyone even gets to
select anything?
Not that it'd make ANY sense, I'm sure. Jeeesh!....
</rant>
Received on Tue Apr 05 2011 - 07:14:34 CDT