Re: ALTER SYSTEM commands result in 'reliable message' wait - RAC
Date: Fri, 21 Oct 2016 21:27:53 +0200
Message-ID: <CALH8A92v60Nad+pc=LPJsAJRbY3Xbv+vpL=X9MzrxSweDiUJHg_at_mail.gmail.com>
Ruan,
have you tried to identify the channel
according to
https://perfchron.com/2015/12/30/diagnosing-oracle-reliable-message-waits/
this might help digging deeper?
Martin
2016-10-20 23:53 GMT+02:00 Ruan Linehan <ruandav_at_gmail.com>:
> Hi all,
>
> Long time lurker(first time poster)...
>
> I am looking for some assistance...(Or brainstorming at least).
>
> I have cloned via RMAN active duplicate an ASM based (3 x Linux OS node)
> RAC 11.2.0.4.5 database from a shared cluster to a new (Similar HW) shared
> cluster (3 x node) environment.
> * I have actually performed this a few times and reproduced the issue each
> time.
>
> The RMAN duplicate works successfully, no problems. I am able to
> start/stop the instance on the destination side post duplicate
> Initially the destination instance is single instance and then I convert
> this to a 3 x instance RAC DB.
>
> However, I am observing and able to reproduce "hanging" symptoms on this
> cloned copy of the database (which it now transpires are also reproducible
> on the source DB also). We were not aware of this problem (The issue when
> attempting to recreate it is that it does not always appear consistently,
> attempted recreation of the issue is somewhat hit/miss).
>
> For example, see below and note the awful timings for the ALTER SYSTEM...
> commands. The initialisation parameter chosen is arbitrary. I have
> reproduced the issue with different parameters. It appears to only occur
> when incorporating the "memory"/"both" clause of the command.
>
> oracle$ sqlplus / as sysdba
> SQL*Plus: Release 11.2.0.4.0 Production on Wed Oct 19 15:35:17 2016
> Copyright (c) 1982, 2013, Oracle. All rights reserved.
> Connected to:
> Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit
> Production
> With the Partitioning, Real Application Clusters, Automatic Storage
> Management, OLAP,
> Data Mining and Real Application Testing options
>
> SQL> alter system set dispatchers='' scope=spfile;
> System altered.
> SQL> set timing on
> SQL> alter system set dispatchers='' scope=spfile;
> System altered.
> Elapsed: 00:00:00.01
> SQL> alter system set dispatchers='' scope=memory;
> System altered.
> Elapsed: 00:03:22.69
> SQL> alter system set dispatchers='' scope=both;
> System altered.
> Elapsed: 00:56:52.44
> SQL>
>
> Other general operations on the database are reportedly effected also (Its
> just very easy to demonstrate the above to show the extent of the "hang").
>
> I can shut down all but one RAC instance and the problem persists (albeit
> to a lesser extent, the timings are shorter). But they are still enormous
> in contrast to the expected command completion time.
>
> I have opened an SR and nothing has been uncovered as yet. Oracle support
> are struggling to ascertain the cause to say the least. There is nothing in
> the RDBMS alert logs for each instance and nothing indicative in the ASM
> alert logs...
> An ASH report for the user performing the command indicates 100% 'reliable
> message' wait.
>
> Extract from the RDBMS instance alert log where the above example was
> demonstrated...
>
> oracle$ tail -10 alert_DPOTHPRD1.log
> Wed Oct 19 15:34:07 2016
> CJQ0 started with pid=112, OS id=50645
> Wed Oct 19 15:35:40 2016
> ALTER SYSTEM SET dispatchers='' SCOPE=SPFILE;
> Wed Oct 19 15:35:51 2016
> ALTER SYSTEM SET dispatchers='' SCOPE=SPFILE;
> Wed Oct 19 15:39:20 2016
> ALTER SYSTEM SET dispatchers='' SCOPE=MEMORY;
> Wed Oct 19 16:36:51 2016
> ALTER SYSTEM SET dispatchers='' SCOPE=BOTH;
> oracle$
>
>
> The below is also taken from a hang analyze TRC file:
>
> ===============================================================================
>
> HANG ANALYSIS:
> instances (db_name.oracle_sid): dbprodrl.dbprodrl1, dbprodrl.dbprodrl2,
> dbprodrl.dbprodrl3
> no oradebug node dumps
> os thread scheduling delay history: (sampling every 1.000000 secs)
> 0.000000 secs at [ 15:37:49 ]
> NOTE: scheduling delay has not been sampled for 0.539347 secs
> 0.000000 secs from [ 15:37:45 - 15:37:50 ], 5 sec avg
> 0.000000 secs from [ 15:36:50 - 15:37:50 ], 1 min avg
> 0.000000 secs from [ 15:33:28 - 15:37:50 ], 5 min avg
> vktm time drift history
> ===============================================================================
>
> Chains most likely to have caused the hang:
> [a] Chain 1 Signature: 'reliable message'
> Chain 1 Signature Hash: 0x55ce7f30
> [b] Chain 2 Signature: 'EMON slave idle wait'
> Chain 2 Signature Hash: 0x9fbbc886
> [c] Chain 3 Signature: 'EMON slave idle wait'
> Chain 3 Signature Hash: 0x9fbbc886
>
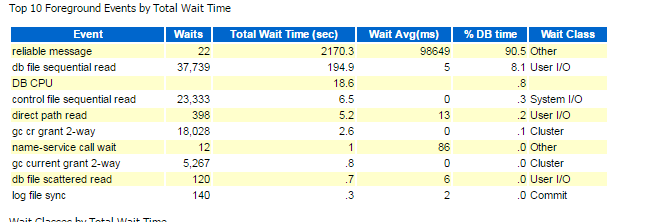
> And screen-grab from an AWR report...
> [image: Inline image 1]
>
> The (cloned) database is running on a shared cluster with three other
> active databases at present. None of the other databases display the same
> symptom. I have examined a multitude of 'reliable message' wait documents
> on metalink but none fit our scenario criteria. Possibly someone has prior
> experience diagnosing this particular wait event?
>
> Regards,
> Ruan Linehan
>
>
>
--
Martin Berger martin.a.berger_at_gmail.com
+43 660 2978929 <+436602978929>
_at_martinberx <https://twitter.com/martinberx>
http://berxblog.blogspot.com
--
http://www.freelists.org/webpage/oracle-l
- image/png attachment: image.png
Received on Fri Oct 21 2016 - 21:27:53 CEST
{kind=link}